seq2seq专题

深度学习100问50:seq2seq的原理是什么
嘿,朋友!让我用超有趣的方式给你讲讲 seq2seq 的原理吧! 想象一下,seq2seq 就像是一个神奇的翻译官团队。这个团队有两个重要成员:编码器和解码器。 一、编码器——信息收集小能手 把输入的序列(比如一段话)想象成一本神秘的魔法书。编码器就像是一个勤奋的魔法师,他一页一页地翻阅这本魔法书。每翻一页,他就会根据书上的内容更新自己的魔法状态。等他把整本书都翻完了,他就把这本书里
NLP-生成模型-2014:Seq2Seq【缺点:①解码器无法对齐编码器(Attention机制);②编码器端信息过使用或欠使用(Coverage机制);③解码器无法解决OOV(Pointer机制)】
《原始论文:Sequence to Sequence Learning with Neural Networks》 Seq2Seq模型是将一个序列信号,通过“编码&解码”生成一个新的序列信号,通常用于机器翻译、语音识别、自动对话等任务。 Seq2Seq(多层LSTM-多层LSTM)+Attention架构是Transformer提出之前最好的序列生成模型。 我们之前遇到的较为熟悉的序列问题,

人工智能-机器学习-深度学习-自然语言处理(NLP)-生成模型:Seq2Seq模型(Encoder-Decoder框架、Attention机制)
我们之前遇到的较为熟悉的序列问题,主要是利用一系列输入序列构建模型,预测某一种情况下的对应取值或者标签,在数学上的表述也就是通过一系列形如 X i = ( x 1 , x 2 , . . . , x n ) \textbf{X}_i=(x_1,x_2,...,x_n) Xi=(x1,x2,...,xn) 的向量序列来预测 Y Y Y 值,这类的问题的共同特点是,输入可以是一个定长或者不

自然语言处理-应用场景-聊天机器人(二):Seq2Seq【CHAT/闲聊机器人】--> BeamSearch算法预测【替代 “维特比算法” 预测、替代 “贪心算法” 预测】
在项目准备阶段我们知道,用户说了一句话后,会判断其意图,如果是想进行闲聊,那么就会调用闲聊模型返回结果。 目前市面上的常见闲聊机器人有微软小冰这种类型的模型,很久之前还有小黄鸡这种体验更差的模型 常见的闲聊模型都是一种seq2seq的结构。 一、准备训练数据 单轮次的聊天数据非常不好获取,所以这里我们从github上使用一些开放的数据集来训练我们的闲聊模型 数据地址:https://gi
自然语言处理-应用场景-文本生成:Seq2Seq --> 看图说话【将一张图片转为一段文本】
人工智能-自然语言处理(NLP)-应用场景-Seq2Seq:看图说话【将一张图片转为一段文本】

【王树森】RNN模型与NLP应用(7/9):机器翻译与Seq2Seq模型(个人向笔记)
Machine Translation Data 做机器学习任务的第一步都是处理数据,我们首先需要准备机器翻译的数据。由于我们是学习用途,因此拿一个小规模数据集即可:http://www.manythings.org/anki/下面的数据集中:一个英语句子对应多个德语句子,如果翻译的时候能命中其中的一个则算作完全正确。 1. Preprocessing 将大写全部转化为小写去掉标点符号

NLP—RNN、Seq2Seq和Attention
文章目录 循环神经网络(Recurrent Neural Network,RNN)最基本的单层神经网络经典的RNN结构(N vs N)RNN变体(N vs 1)RNN变体(1 vs N) 序列到序列(Sequence to Sequence,Seq2Seq)注意力机制(Attention)Attention 的优点Attention 的缺点Attention可视化 循环神经网

seq2seq编码器encoder和解码器decoder详解
编码器 在序列到序列模型中,编码器将输入序列(如一个句子)转换为一个隐藏状态序列,供解码器生成输出。编码层通常由嵌入层和RNN(如GRU/LSTM)等组成 Token:是模型处理文本时的基本单元,可以是词,子词,字符等,每个token都有一个对应的ID。是由原始文本中的词或子词通过分词器(Tokenizer)处理后得到的最小单位,这些 token 会被映射为词汇表中的唯一索引 ID输入: 原始
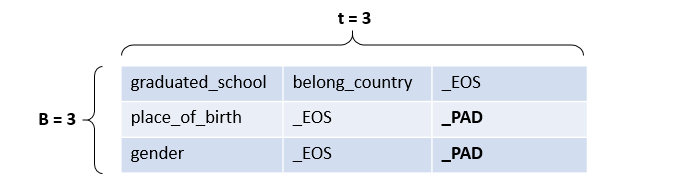
基于知识库的问答KBQA:seq2seq模型实践
0. 前言 0.1 问题描述 基于知识图谱的自动问答(Question Answering over Knowledge Base, 即 KBQA)问题的大概形式是,预先给定一个知识库(比如Freebase),知识库中包含着大量的先验知识数据,然后利用这些知识资源自动回答自然语言形态的问题(比如“肉夹馍是江苏的美食吗”,“虵今年多大了”等人民群众喜闻乐见的问题)。 0.2 什么是知识库 知
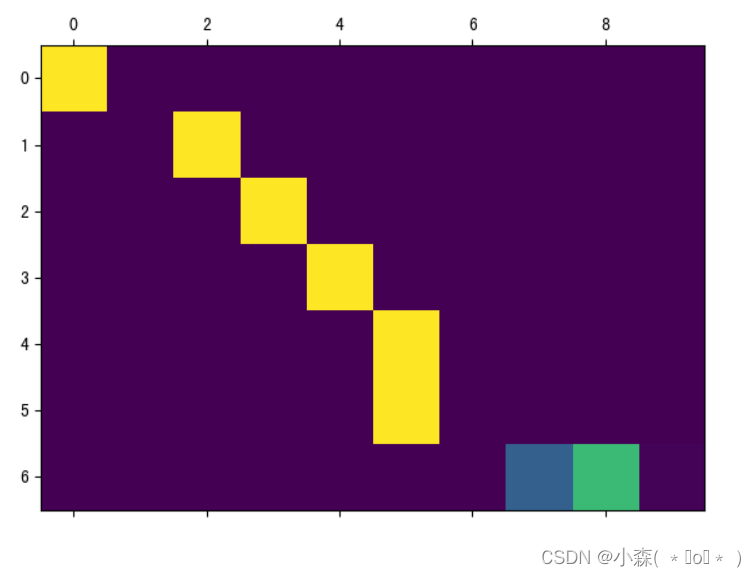
使用seq2seq架构实现英译法
seq2seq介绍 模型架构: Seq2Seq(Sequence-to-Sequence)模型是一种在自然语言处理(NLP)中广泛应用的架构,其核心思想是将一个序列作为输入,并输出另一个序列。这种模型特别适用于机器翻译、聊天机器人、自动文摘等场景,其中输入和输出的长度都是可变的。 embedding层在seq2seq模型中起着将离散单词转换为连续向量表示的关键作用,为后续的自然语
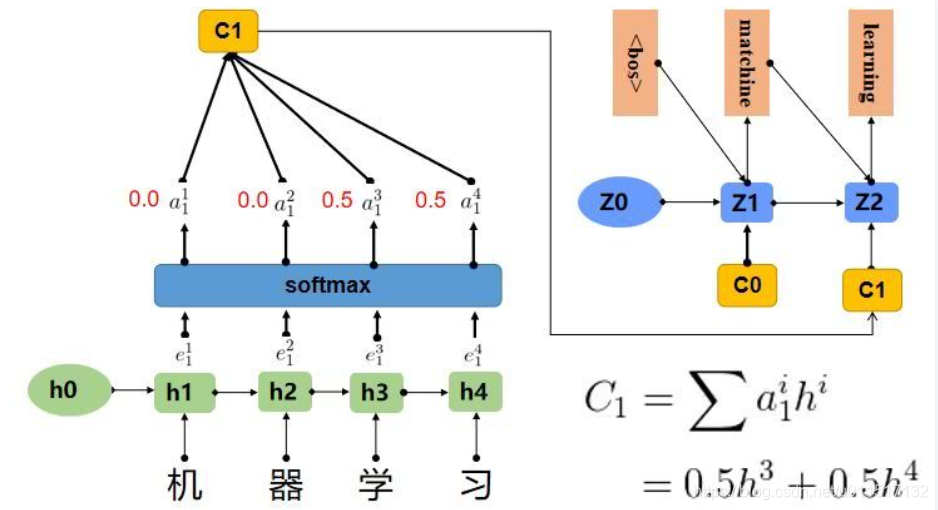
Seq2Seq与Attention
一、seq2seq 对于序列数据常用的深度学习结构是RNN,但是普通RNN的结构存在缺陷,比如梯度消失,输入序列与输出序列要求等长等问题。这在许多情况下,比如翻译、生成总结等,RNN没有很好的效果。为了解决RNN梯度消失问题,提出了lstn结构,但是仍没有解决输入序列与输出序列要求等长的问题。 Sequence-to-sequence(seq2seq)解除了输入和输出序列等长和长度固定的问题。一

李宏毅《机器学习》课程笔记(作业八:seq2seq)
怎么样生成一个有结构的东西。可以用RNN依次产生序列的元素。 在智能对话等等场景中,是”有条件的生成“。核心的思路是用一个encoder把输入变成一个vector,再用一个decoder输入这个vector Attention就是一种动态的条件生成网络。 待后续补充
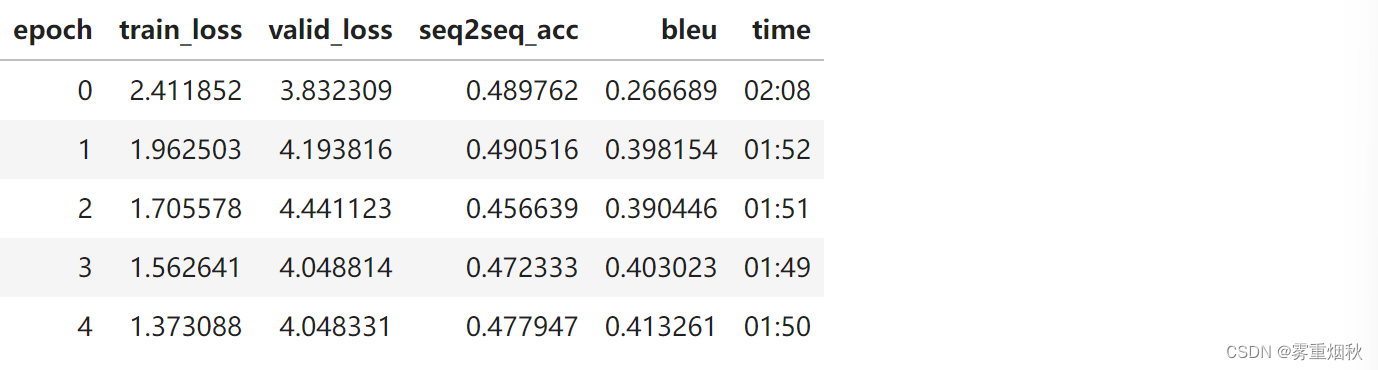
course-nlp——7-seq2seq-translation
本文参考自https://github.com/fastai/course-nlp。 使用 RNN 进行翻译 此笔记本是根据 Sylvain Gugger 创建的笔记本修改而来的。 今天我们将处理翻译任务。我们将从法语翻译成英语,为了使任务规模保持在可控的范围内,我们将仅限于翻译问题。 此任务是序列到序列 (seq2seq) 的一个示例。 Seq2seq 可能比分类更具挑战性,因为输出的长
使用Python实现深度学习模型:序列到序列模型(Seq2Seq)
序列到序列(Seq2Seq)模型是一种深度学习模型,广泛应用于机器翻译、文本生成和对话系统等自然语言处理任务。它的核心思想是将一个序列(如一句话)映射到另一个序列。本文将详细介绍 Seq2Seq 模型的原理,并使用 Python 和 TensorFlow/Keras 实现一个简单的 Seq2Seq 模型。 1. 什么是序列到序列模型? Seq2Seq 模型通常由两个主要部分组成:编码器(Enc

Seq2Seq模型:详述其发展历程、深远影响与结构深度剖析
Seq2Seq(Sequence-to-Sequence)模型是一种深度学习架构,专为处理从一个输入序列到一个输出序列的映射任务设计。这种模型最初应用于机器翻译任务,但因其灵活性和有效性,现已被广泛应用于自然语言处理(NLP)、语音识别、图像描述生成、对话系统、文本摘要等众多领域中涉及序列转换的问题。 一、Seq2Seq模型的发展与影响 1、早期研究与背景 循环神经网络(RNNs)的发展

李沐第十八课《seq2seq》
这节课主要讲了两个东西,一个是seq2seq(编码器-解码器),一个是attention机制 seq2seq 当输入和输出都不是定长的时候,比如翻译等,我们可以采用编码器-解码器机制,编码器对应输入序列,解码器对应输出序列。 1,编码器的作用是将一个不定长的输入序列转换为一个定长的背景向量c 2,编码器最终输出的背景向量c,这个背景向量c编码了输入序列X1,X2,X3..XT的信息,

基于附带Attention机制的seq2seq模型架构实现英译法的案例
模型架构 先上图 我们这里选用GRU来实现该任务,因此上图的十个方框框都是GRU块,如第二张图,放第一张图主要是强调编码器的输出是作用在解码器每一次输入的观点,具体的详细流程图将在代码实现部分给出。 编码阶段 1. 准备工作 要用到的数据集点此下载https://download.pytorch.org/tutorial/data.zip,备用地址,点击下载https://www.
python-pytorch seq2seq+attention笔记0.5.00
python-pytorch seq2seq+attention笔记0.5.00 1. LSTM模型的数据size2. 关于LSTM的输入数据包含hn和cn时,hn和cn的size3. LSTM参数中默认batch_first4. Attention机制的三种算法5. 模型的编码器6. 模型的解码器7. 最终模型8. 数据的准备9. 遇到的问题10. 完整代码 1. LSTM模型

TensorFlow seq2seq解读
github链接 注:1.2最新版本不兼容,用命令pip3 install tensorflow==1.0.0 在translate.py文件里,是调用各种函数;在seq2seq_model.py文件里,是定义了这个model的具体输入、输出、中间参数是怎样的init,以及获取每个epoch训练数据get_batch和训练方法step。确定这些之后再考虑各种变量的shape等问题。 代码结构

Pytorch学习(7)——Seq2Seq与Attention
视频地址:https://www.bilibili.com/video/BV1vz4y1R7Mm?p=7 Sqe2Seq, Attention 先去 https://github.com/ZeweiChu/PyTorch-Course/tree/master/notebooks 下载数据集(nmt文件夹) import osimport sysimport mathfrom colle

seq2seq架构略解
用于序列翻译任务(下图来自d2l) 训练时输入输出格式: 若数据集为{ <(a1,a2,a3,a4,a5),(b1,b2,b3,b4,b5)> }(AB语言对应的句子组) 输入 A语言的单词序列+结束符(a1,a2,a3,a4,a5,<eos>) 开始符+B语言的单词序列(<bos>,b1,b2,b3,b4,b5) 输出 B语言的单词序列(b1,b2,b3,b4,b5,<eos>

李沐62_序列到序列学习seq2seq——自学笔记
"英-法”数据集来训练这个机器翻译模型。 !pip install --upgrade d2l==0.17.5 #d2l需要更新 import collectionsimport mathimport torchfrom torch import nnfrom d2l import torch as d2l 循环神经网络编码器。 我们使用了嵌入层(embedding laye
Pytorch基于深度学习模型Seq2Seq的聊天机器人构建与应用部署实战
聊天机器人是非常常见而广泛的应用,很多企业都有很多机器人客服的需求,比如:移动、电信、联通、淘宝、京东等等,聊天机器人的本质就是文本数据处理,我的主要研究方向并不是文本处理相关的,但是断断续续学习、工作中接触到了一定的文本数据处理的任务,对文本数据处理也算得上是有一定的了解程度吧。 聊天机器人的应用可以简单理解为“输入一句话,机器返回一句响应的话”,返回的话跟你的话或者是问

论文阅读 seq2seq模型的coverage机制
Get To The Point: Summarization with Pointer-Generator Networks Abigail See, Peter J. Liu, Christopher D. Manning Standford University & Google Brain, 2017 这是ACL2017上的一篇文章,提出了coverage机制,目的是为了解决seq2
seq2seq实例详解(待完成)
seq2seq实例详解(待完成) 比较好的博客: https://blog.csdn.net/wangyangzhizhou/article/details/77883152 https://blog.csdn.net/leadai/article/details/78809788