本文主要是介绍course-nlp——7-seq2seq-translation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文参考自https://github.com/fastai/course-nlp。
使用 RNN 进行翻译
此笔记本是根据 Sylvain Gugger 创建的笔记本修改而来的。
今天我们将处理翻译任务。我们将从法语翻译成英语,为了使任务规模保持在可控的范围内,我们将仅限于翻译问题。
此任务是序列到序列 (seq2seq) 的一个示例。 Seq2seq 可能比分类更具挑战性,因为输出的长度是可变的(并且通常与输入的长度不同)。
法语/英语平行文本来自 http://www.statmt.org/wmt15/translation-task.html 。它由 Chris Callison-Burch 创建,他抓取了数百万个网页,然后使用一组简单的启发式方法将法语 URL 转换为英语 URL(即用“en”替换“fr”和大约 40 条其他手写规则),并假设这些文档是彼此的翻译。
在 PyTorch 中翻译要困难得多:https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
from fastai.text import *
下载并预处理我们的数据
我们将首先将原始数据集缩减为问题所需。您只需执行一次,取消注释即可运行。数据集可在此处下载。
path = Config().data_path()
# ! wget https://s3.amazonaws.com/fast-ai-nlp/giga-fren.tgz -P {path}
# ! tar xf {path}/giga-fren.tgz -C {path}
path = Config().data_path()/'giga-fren'
path.ls()
[PosixPath('/home/racheltho/.fastai/data/giga-fren/models'),PosixPath('/home/racheltho/.fastai/data/giga-fren/giga-fren.release2.fixed.fr'),PosixPath('/home/racheltho/.fastai/data/giga-fren/cc.en.300.bin'),PosixPath('/home/racheltho/.fastai/data/giga-fren/data_save.pkl'),PosixPath('/home/racheltho/.fastai/data/giga-fren/giga-fren.release2.fixed.en'),PosixPath('/home/racheltho/.fastai/data/giga-fren/cc.fr.300.bin'),PosixPath('/home/racheltho/.fastai/data/giga-fren/questions_easy.csv')]
# with open(path/'giga-fren.release2.fixed.fr') as f: fr = f.read().split('\n')
# with open(path/'giga-fren.release2.fixed.en') as f: en = f.read().split('\n')
我们将使用正则表达式来找出英文数据集中以“Wh”开头并以问号结尾的字符串,从而找出问题。您只需运行以下几行代码一次:
# re_eq = re.compile('^(Wh[^?.!]+\?)')
# re_fq = re.compile('^([^?.!]+\?)')
# en_fname = path/'giga-fren.release2.fixed.en'
# fr_fname = path/'giga-fren.release2.fixed.fr'
# re_eq = re.compile('^(Wh[^?.!]+\?)')
# re_fq = re.compile('^([^?.!]+\?)')
# en_fname = path/'giga-fren.release2.fixed.en'
# fr_fname = path/'giga-fren.release2.fixed.fr'
# qs = [(q1,q2) for q1,q2 in qs]
# df = pd.DataFrame({'fr': [q[1] for q in qs], 'en': [q[0] for q in qs]}, columns = ['en', 'fr'])
# df.to_csv(path/'questions_easy.csv', index=False)
path.ls()
[PosixPath('/home/racheltho/.fastai/data/giga-fren/models'),PosixPath('/home/racheltho/.fastai/data/giga-fren/giga-fren.release2.fixed.fr'),PosixPath('/home/racheltho/.fastai/data/giga-fren/cc.en.300.bin'),PosixPath('/home/racheltho/.fastai/data/giga-fren/data_save.pkl'),PosixPath('/home/racheltho/.fastai/data/giga-fren/giga-fren.release2.fixed.en'),PosixPath('/home/racheltho/.fastai/data/giga-fren/cc.fr.300.bin'),PosixPath('/home/racheltho/.fastai/data/giga-fren/questions_easy.csv')]
将我们的数据加载到DataBunch中
我们的问题是这样的:
df = pd.read_csv(path/'questions_easy.csv')
df.head()

为了简单起见,我们将所有内容都小写。
df['en'] = df['en'].apply(lambda x:x.lower())
df['fr'] = df['fr'].apply(lambda x:x.lower())
首先,我们需要批量整理输入和目标:它们的长度不同,所以我们需要添加填充以使序列长度相同;
def seq2seq_collate(samples, pad_idx=1, pad_first=True, backwards=False):"Function that collect samples and adds padding. Flips token order if needed"samples = to_data(samples)max_len_x,max_len_y = max([len(s[0]) for s in samples]),max([len(s[1]) for s in samples])res_x = torch.zeros(len(samples), max_len_x).long() + pad_idxres_y = torch.zeros(len(samples), max_len_y).long() + pad_idxif backwards: pad_first = not pad_firstfor i,s in enumerate(samples):if pad_first: res_x[i,-len(s[0]):],res_y[i,-len(s[1]):] = LongTensor(s[0]),LongTensor(s[1])else: res_x[i,:len(s[0]):],res_y[i,:len(s[1]):] = LongTensor(s[0]),LongTensor(s[1])if backwards: res_x,res_y = res_x.flip(1),res_y.flip(1)return res_x,res_y
然后我们创建一个使用此整理函数的特殊DataBunch。
doc(Dataset)
doc(DataLoader)
doc(DataBunch)
class Seq2SeqDataBunch(TextDataBunch):"Create a `TextDataBunch` suitable for training an RNN classifier."@classmethoddef create(cls, train_ds, valid_ds, test_ds=None, path:PathOrStr='.', bs:int=32, val_bs:int=None, pad_idx=1,dl_tfms=None, pad_first=False, device:torch.device=None, no_check:bool=False, backwards:bool=False, **dl_kwargs) -> DataBunch:"Function that transform the `datasets` in a `DataBunch` for classification. Passes `**dl_kwargs` on to `DataLoader()`"datasets = cls._init_ds(train_ds, valid_ds, test_ds)val_bs = ifnone(val_bs, bs)collate_fn = partial(seq2seq_collate, pad_idx=pad_idx, pad_first=pad_first, backwards=backwards)train_sampler = SortishSampler(datasets[0].x, key=lambda t: len(datasets[0][t][0].data), bs=bs//2)train_dl = DataLoader(datasets[0], batch_size=bs, sampler=train_sampler, drop_last=True, **dl_kwargs)dataloaders = [train_dl]for ds in datasets[1:]:lengths = [len(t) for t in ds.x.items]sampler = SortSampler(ds.x, key=lengths.__getitem__)dataloaders.append(DataLoader(ds, batch_size=val_bs, sampler=sampler, **dl_kwargs))return cls(*dataloaders, path=path, device=device, collate_fn=collate_fn, no_check=no_check)
SortishSampler??
TextList 的子类将在调用 .databunch 中使用此 DataBunch 类,并使用 TextList 进行标记(因为我们的目标是其他文本)。
class Seq2SeqTextList(TextList):_bunch = Seq2SeqDataBunch_label_cls = TextList
这就是我们使用数据块 API 所需要的全部内容!
src = Seq2SeqTextList.from_df(df, path = path, cols='fr').split_by_rand_pct(seed=42).label_from_df(cols='en', label_cls=TextList)
np.percentile([len(o) for o in src.train.x.items] + [len(o) for o in src.valid.x.items], 90)
28.0
np.percentile([len(o) for o in src.train.y.items] + [len(o) for o in src.valid.y.items], 90)
23.0
我们删除目标长度超过 30 个标记的项目。
src = src.filter_by_func(lambda x,y: len(x) > 30 or len(y) > 30)
len(src.train) + len(src.valid)
48352
data = src.databunch()
data.save()
data
Seq2SeqDataBunch;Train: LabelList (38706 items)
x: Seq2SeqTextList
xxbos qu’est - ce que la lumière ?,xxbos où sommes - nous ?,xxbos d'où venons - nous ?,xxbos que ferions - nous sans elle ?,xxbos quel est le groupe autochtone principal sur l’île de vancouver ?
y: TextList
xxbos what is light ?,xxbos who are we ?,xxbos where did we come from ?,xxbos what would we do without it ?,xxbos what is the major aboriginal group on vancouver island ?
Path: /home/racheltho/.fastai/data/giga-fren;Valid: LabelList (9646 items)
x: Seq2SeqTextList
xxbos quels pourraient être les effets sur l’instrument de xxunk et sur l’aide humanitaire qui ne sont pas co - xxunk ?,xxbos quand la source primaire a - t - elle été créée ?,xxbos pourquoi tant de soldats ont - ils fait xxunk de ne pas voir ce qui s'est passé le 4 et le 16 mars ?,xxbos quels sont les taux d'impôt sur le revenu au canada pour 2007 ?,xxbos pourquoi le programme devrait - il intéresser les employeurs et les fournisseurs de services ?
y: TextList
xxbos what would be the resulting effects on the pre - accession instrument and humanitarian aid that are not co - decided ?,xxbos when was the primary source created ?,xxbos why did so many soldiers look the other way in relation to the incidents of march 4th and march xxunk ?,xxbos what are the income tax rates in canada for 2007 ?,xxbos why is the program good for employers and service providers ?
Path: /home/racheltho/.fastai/data/giga-fren;Test: None
path
PosixPath('/home/racheltho/.fastai/data/giga-fren')
data = load_data(path)
data.show_batch()

创建我们的模型
预训练嵌入
您需要从 fastText 文档下载词向量(抓取向量)。FastText 已为 157 种语言预先训练了词向量,并在 Common Crawl 和 Wikipedia 上进行了训练。这些模型是使用 CBOW 进行训练的。
如果您需要复习一下词向量,可以查看我在此词向量研讨会中的简要介绍以及随附的 github repo。
有关 CBOW(连续词袋与 Skip-gram)的更多阅读材料:
- fastText 教程
- StackOverflow
要安装 fastText:
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ pip install 。
import fastText as ft
下载词向量的命令只需要运行一次:
# ! wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.en.300.bin.gz -P {path}
# ! wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.fr.300.bin.gz -P {path}
# gunzip {path} / cc.en.300.bin.gz
# gunzip {path} / cc.fr.300.bin.gz
fr_vecs = ft.load_model(str((path/'cc.fr.300.bin')))
en_vecs = ft.load_model(str((path/'cc.en.300.bin')))
我们使用预训练向量和随机数据为缺失部分创建一个嵌入模块。
def create_emb(vecs, itos, em_sz=300, mult=1.):emb = nn.Embedding(len(itos), em_sz, padding_idx=1)wgts = emb.weight.datavec_dic = {w:vecs.get_word_vector(w) for w in vecs.get_words()}miss = []for i,w in enumerate(itos):try: wgts[i] = tensor(vec_dic[w])except: miss.append(w)return emb
emb_enc = create_emb(fr_vecs, data.x.vocab.itos)
emb_dec = create_emb(en_vecs, data.y.vocab.itos)
emb_enc.weight.size(), emb_dec.weight.size()
(torch.Size([11336, 300]), torch.Size([8152, 300]))
model_path = Config().model_path()
torch.save(emb_enc, model_path/'fr_emb.pth')
torch.save(emb_dec, model_path/'en_emb.pth')
emb_enc = torch.load(model_path/'fr_emb.pth')
emb_dec = torch.load(model_path/'en_emb.pth')
Our Model
Encoders & Decoders
该模型本身由编码器和解码器组成
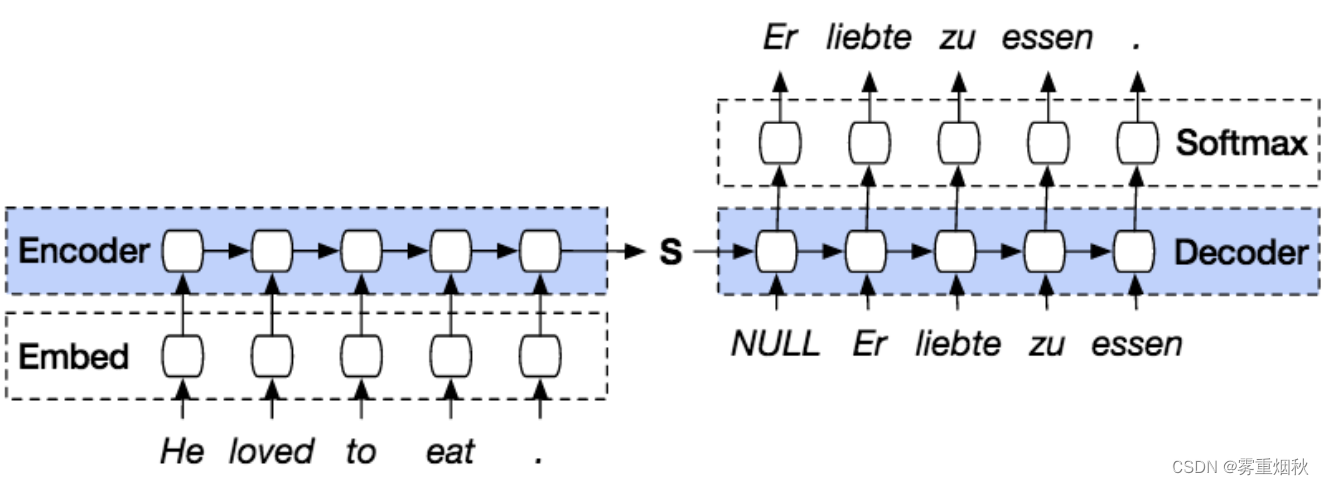
编码器是一个循环神经网络,我们给它输入句子,产生一个输出(我们暂时丢弃)和一个隐藏状态。隐藏状态是 RNN 产生的激活。
然后将该隐藏状态提供给解码器(另一个 RNN),解码器将其与预测的输出结合使用以产生翻译。我们循环直到解码器产生一个填充标记(或 30 次迭代以确保在训练开始时它不是无限循环)。
我们将使用 GRU 作为编码器,并使用单独的 GRU 作为解码器。其他选项包括使用 LSTM 或 QRNN(请参阅此处)。GRU、LSTM 和 QRNN 都解决了 RNN 缺乏长期记忆的问题。
class Seq2SeqRNN(nn.Module):def __init__(self, emb_enc, emb_dec, nh, out_sl, nl=2, bos_idx=0, pad_idx=1):super().__init__()self.nl,self.nh,self.out_sl = nl,nh,out_slself.bos_idx,self.pad_idx = bos_idx,pad_idxself.em_sz_enc = emb_enc.embedding_dimself.em_sz_dec = emb_dec.embedding_dimself.voc_sz_dec = emb_dec.num_embeddingsself.emb_enc = emb_encself.emb_enc_drop = nn.Dropout(0.15)self.gru_enc = nn.GRU(self.em_sz_enc, nh, num_layers=nl,dropout=0.25, batch_first=True)self.out_enc = nn.Linear(nh, self.em_sz_dec, bias=False)self.emb_dec = emb_decself.gru_dec = nn.GRU(self.em_sz_dec, self.em_sz_dec, num_layers=nl,dropout=0.1, batch_first=True)self.out_drop = nn.Dropout(0.35)self.out = nn.Linear(self.em_sz_dec, self.voc_sz_dec)self.out.weight.data = self.emb_dec.weight.datadef encoder(self, bs, inp):h = self.initHidden(bs)emb = self.emb_enc_drop(self.emb_enc(inp))_, h = self.gru_enc(emb, h)h = self.out_enc(h)return hdef decoder(self, dec_inp, h):emb = self.emb_dec(dec_inp).unsqueeze(1)outp, h = self.gru_dec(emb, h)outp = self.out(self.out_drop(outp[:,0]))return h, outpdef forward(self, inp):bs, sl = inp.size()h = self.encoder(bs, inp)dec_inp = inp.new_zeros(bs).long() + self.bos_idxres = []for i in range(self.out_sl):h, outp = self.decoder(dec_inp, h)dec_inp = outp.max(1)[1]res.append(outp)if (dec_inp==self.pad_idx).all(): breakreturn torch.stack(res, dim=1)def initHidden(self, bs): return one_param(self).new_zeros(self.nl, bs, self.nh)
xb,yb = next(iter(data.valid_dl))
xb.shape
torch.Size([64, 30])
rnn = Seq2SeqRNN(emb_enc, emb_dec, 256, 30)
rnn
Seq2SeqRNN((emb_enc): Embedding(11336, 300, padding_idx=1)(emb_enc_drop): Dropout(p=0.15)(gru_enc): GRU(300, 256, num_layers=2, batch_first=True, dropout=0.25)(out_enc): Linear(in_features=256, out_features=300, bias=False)(emb_dec): Embedding(8152, 300, padding_idx=1)(gru_dec): GRU(300, 300, num_layers=2, batch_first=True, dropout=0.1)(out_drop): Dropout(p=0.35)(out): Linear(in_features=300, out_features=8152, bias=True)
)
len(xb[0])
30
h = rnn.encoder(64, xb.cpu())
h.size()
torch.Size([2, 64, 300])
在使用通常的扁平化交叉熵版本之前,损失会填充输出和目标,使它们具有相同的大小。我们对准确性也做了同样的事情。
def seq2seq_loss(out, targ, pad_idx=1):bs,targ_len = targ.size()_,out_len,vs = out.size()if targ_len>out_len: out = F.pad(out, (0,0,0,targ_len-out_len,0,0), value=pad_idx)if out_len>targ_len: targ = F.pad(targ, (0,out_len-targ_len,0,0), value=pad_idx)return CrossEntropyFlat()(out, targ)
训练我们的模型
learn = Learner(data, rnn, loss_func=seq2seq_loss)
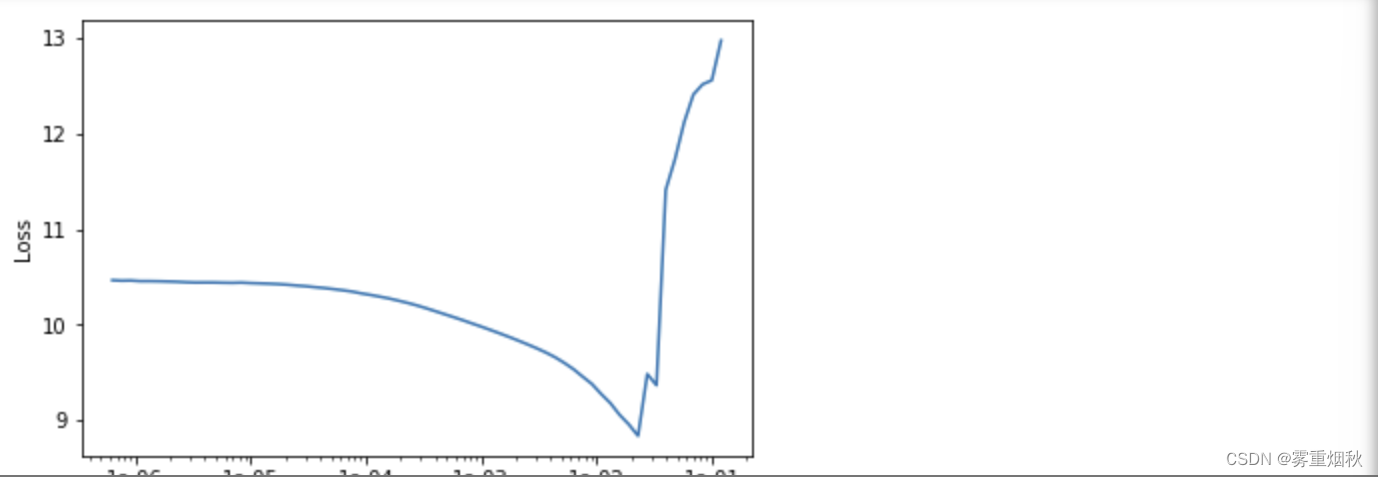
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.recorder.plot()
learn.fit_one_cycle(4, 1e-2)

让我们释放一些 RAM
del fr_vecs
del en_vecs
由于损失不太容易解释,我们还要看看准确率。同样,我们将添加填充,以便输出和目标的长度相同。
def seq2seq_acc(out, targ, pad_idx=1):bs,targ_len = targ.size()_,out_len,vs = out.size()if targ_len>out_len: out = F.pad(out, (0,0,0,targ_len-out_len,0,0), value=pad_idx)if out_len>targ_len: targ = F.pad(targ, (0,out_len-targ_len,0,0), value=pad_idx)out = out.argmax(2)return (out==targ).float().mean()
Bleu 度量(参见专用笔记本)
在翻译中,通常使用的指标是 BLEU。
Rachael Tatman 的一篇精彩文章:Evaluating Text Output in NLP: BLEU at your own risk
class NGram():def __init__(self, ngram, max_n=5000): self.ngram,self.max_n = ngram,max_ndef __eq__(self, other):if len(self.ngram) != len(other.ngram): return Falsereturn np.all(np.array(self.ngram) == np.array(other.ngram))def __hash__(self): return int(sum([o * self.max_n**i for i,o in enumerate(self.ngram)]))
def get_grams(x, n, max_n=5000):return x if n==1 else [NGram(x[i:i+n], max_n=max_n) for i in range(len(x)-n+1)]
def get_correct_ngrams(pred, targ, n, max_n=5000):pred_grams,targ_grams = get_grams(pred, n, max_n=max_n),get_grams(targ, n, max_n=max_n)pred_cnt,targ_cnt = Counter(pred_grams),Counter(targ_grams)return sum([min(c, targ_cnt[g]) for g,c in pred_cnt.items()]),len(pred_grams)
class CorpusBLEU(Callback):def __init__(self, vocab_sz):self.vocab_sz = vocab_szself.name = 'bleu'def on_epoch_begin(self, **kwargs):self.pred_len,self.targ_len,self.corrects,self.counts = 0,0,[0]*4,[0]*4def on_batch_end(self, last_output, last_target, **kwargs):last_output = last_output.argmax(dim=-1)for pred,targ in zip(last_output.cpu().numpy(),last_target.cpu().numpy()):self.pred_len += len(pred)self.targ_len += len(targ)for i in range(4):c,t = get_correct_ngrams(pred, targ, i+1, max_n=self.vocab_sz)self.corrects[i] += cself.counts[i] += tdef on_epoch_end(self, last_metrics, **kwargs):precs = [c/t for c,t in zip(self.corrects,self.counts)]len_penalty = exp(1 - self.targ_len/self.pred_len) if self.pred_len < self.targ_len else 1bleu = len_penalty * ((precs[0]*precs[1]*precs[2]*precs[3]) ** 0.25)return add_metrics(last_metrics, bleu)
使用指标进行训练
learn = Learner(data, rnn, loss_func=seq2seq_loss, metrics=[seq2seq_acc, CorpusBLEU(len(data.y.vocab.itos))])
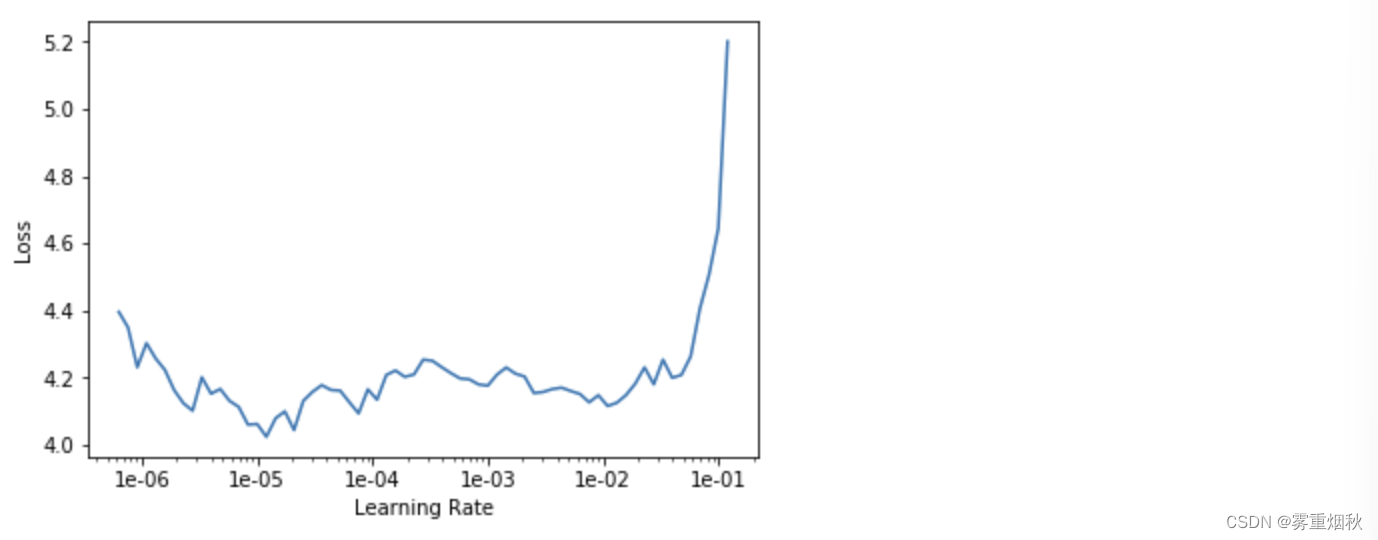
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.recorder.plot()
learn.fit_one_cycle(4, 1e-2)
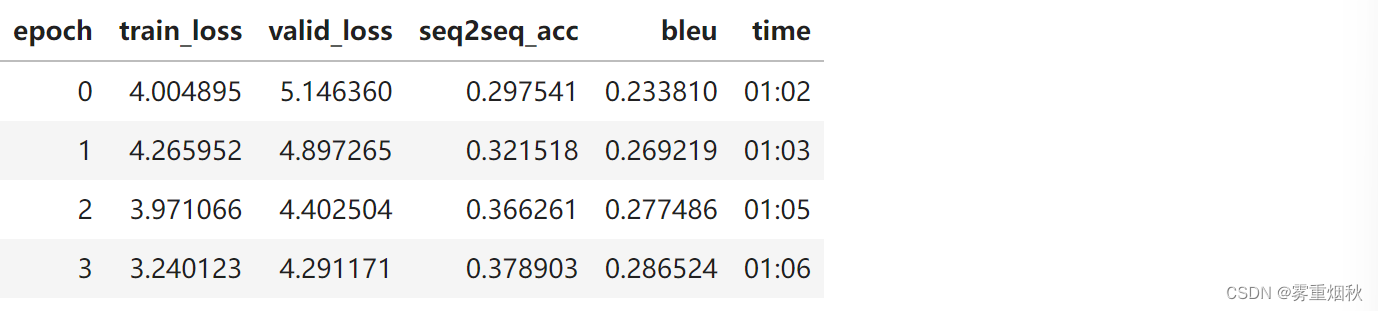
learn.fit_one_cycle(4, 1e-3)
那么我们的模型有多好?让我们看几个预测。
def get_predictions(learn, ds_type=DatasetType.Valid):learn.model.eval()inputs, targets, outputs = [],[],[]with torch.no_grad():for xb,yb in progress_bar(learn.dl(ds_type)):out = learn.model(xb)for x,y,z in zip(xb,yb,out):inputs.append(learn.data.train_ds.x.reconstruct(x))targets.append(learn.data.train_ds.y.reconstruct(y))outputs.append(learn.data.train_ds.y.reconstruct(z.argmax(1)))return inputs, targets, outputs
inputs, targets, outputs = get_predictions(learn)
inputs[700], targets[700], outputs[700]
(Text xxbos quels sont les résultats prévus à court et à long termes de xxunk , et dans quelle mesure ont - ils été obtenus ?,Text xxbos what are the short and long - term expected outcomes of the ali and to what extent have they been achieved ?,Text xxbos what were the results , the , , , , , , and and and and and)
inputs[701], targets[701], outputs[701]
(Text xxbos de quel(s ) xxunk ) a - t - on besoin pour xxunk les profits réels de la compagnie pour l'année qui vient ?,Text xxbos which of the following additional information is necessary to estimate the company 's actual profit for the coming year ?,Text xxbos what is the the to to to the the ( ( ) ))
inputs[2513], targets[2513], outputs[2513]
(Text xxbos de quelles façons l'expérience et les capacités particulières des agences d'exécution contribuent - elles au projet ?,Text xxbos what experience and specific capacities do the implementing organizations bring to the project ?,Text xxbos what are the key and and and and and and of of of of of of ?)
inputs[4000], targets[4000], outputs[4000]
inputs[4000], targets[4000], outputs[4000]
通常开头很好,但问题结束时却变成了重复的单词。
Teacher forcing
帮助训练的一种方法是向解码器提供真实目标,而不是其预测(如果解码器以错误的单词开始,则不太可能给出正确的翻译)。我们在开始时一直这样做,然后逐渐减少教师强制的数量。
class TeacherForcing(LearnerCallback):def __init__(self, learn, end_epoch):super().__init__(learn)self.end_epoch = end_epochdef on_batch_begin(self, last_input, last_target, train, **kwargs):if train: return {'last_input': [last_input, last_target]}def on_epoch_begin(self, epoch, **kwargs):self.learn.model.pr_force = 1 - epoch/self.end_epoch
我们将以下代码添加到我们的转发方法中:
if (targ is not None) and (random.random()<self.pr_force):
if i>=targ.shape[1]: break
dec_inp = targ[:,i]
此外,forward 将接受一个额外的目标参数。
class Seq2SeqRNN_tf(nn.Module):def __init__(self, emb_enc, emb_dec, nh, out_sl, nl=2, bos_idx=0, pad_idx=1):super().__init__()self.nl,self.nh,self.out_sl = nl,nh,out_slself.bos_idx,self.pad_idx = bos_idx,pad_idxself.em_sz_enc = emb_enc.embedding_dimself.em_sz_dec = emb_dec.embedding_dimself.voc_sz_dec = emb_dec.num_embeddingsself.emb_enc = emb_encself.emb_enc_drop = nn.Dropout(0.15)self.gru_enc = nn.GRU(self.em_sz_enc, nh, num_layers=nl,dropout=0.25, batch_first=True)self.out_enc = nn.Linear(nh, self.em_sz_dec, bias=False)self.emb_dec = emb_decself.gru_dec = nn.GRU(self.em_sz_dec, self.em_sz_dec, num_layers=nl,dropout=0.1, batch_first=True)self.out_drop = nn.Dropout(0.35)self.out = nn.Linear(self.em_sz_dec, self.voc_sz_dec)self.out.weight.data = self.emb_dec.weight.dataself.pr_force = 0.def encoder(self, bs, inp):h = self.initHidden(bs)emb = self.emb_enc_drop(self.emb_enc(inp))_, h = self.gru_enc(emb, h)h = self.out_enc(h)return hdef decoder(self, dec_inp, h):emb = self.emb_dec(dec_inp).unsqueeze(1)outp, h = self.gru_dec(emb, h)outp = self.out(self.out_drop(outp[:,0]))return h, outpdef forward(self, inp, targ=None):bs, sl = inp.size()h = self.encoder(bs, inp)dec_inp = inp.new_zeros(bs).long() + self.bos_idxres = []for i in range(self.out_sl):h, outp = self.decoder(dec_inp, h)res.append(outp)dec_inp = outp.max(1)[1]if (dec_inp==self.pad_idx).all(): breakif (targ is not None) and (random.random()<self.pr_force):if i>=targ.shape[1]: continuedec_inp = targ[:,i]return torch.stack(res, dim=1)def initHidden(self, bs): return one_param(self).new_zeros(self.nl, bs, self.nh)
emb_enc = torch.load(model_path/'fr_emb.pth')
emb_dec = torch.load(model_path/'en_emb.pth')
rnn_tf = Seq2SeqRNN_tf(emb_enc, emb_dec, 256, 30)learn = Learner(data, rnn_tf, loss_func=seq2seq_loss, metrics=[seq2seq_acc, CorpusBLEU(len(data.y.vocab.itos))],callback_fns=partial(TeacherForcing, end_epoch=3))
learn.lr_find()
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.
learn.fit_one_cycle(6, 3e-3)
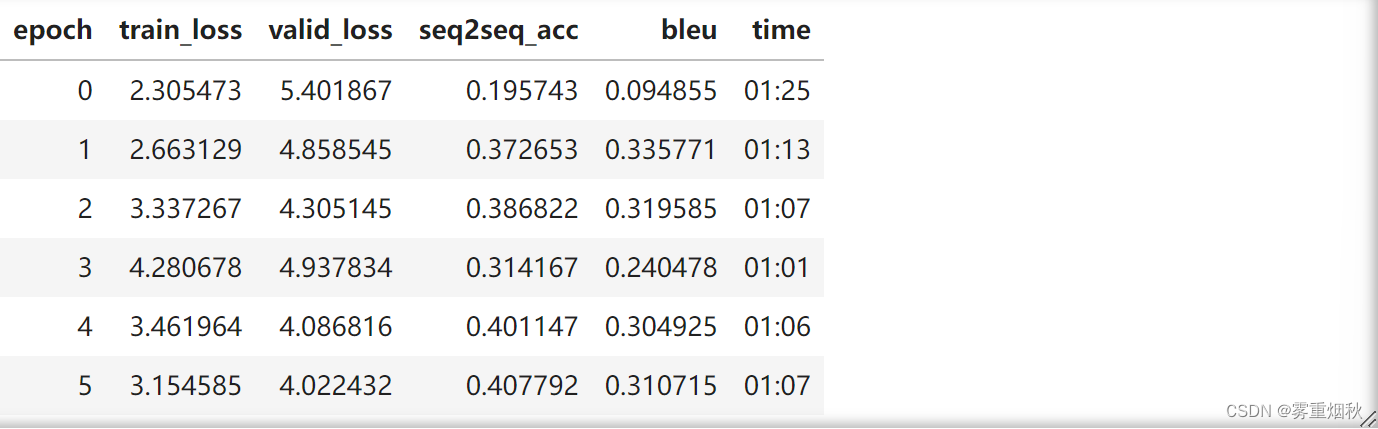
inputs, targets, outputs = get_predictions(learn)
inputs[700],targets[700],outputs[700]
(Text xxbos qui a le pouvoir de modifier le règlement sur les poids et mesures et le règlement sur l'inspection de l'électricité et du gaz ?,Text xxbos who has the authority to change the electricity and gas inspection regulations and the weights and measures regulations ?,Text xxbos who has the xxunk and xxunk and xxunk xxunk ?)
inputs[2513], targets[2513], outputs[2513]
(Text xxbos quelles sont les deux tendances qui ont nuit à la pêche au saumon dans cette province ?,Text xxbos what two trends negatively affected the province ’s salmon fishery ?,Text xxbos what are the main reasons for the xxunk of the xxunk ?)
inputs[4000], targets[4000], outputs[4000]
(Text xxbos où les aires marines nationales de conservation du canada seront - elles situées ?,Text xxbos where will national marine conservation areas of canada be located ?,Text xxbos where are the canadian regulations located in the canadian ?)
带有注意力机制的 Seq2Seq 翻译
注意力是一种利用编码器输出的技术:我们不会完全丢弃它,而是将其与隐藏状态一起使用,以注意输入句中的特定单词,以便对输出句进行预测。具体来说,我们计算注意力权重,然后将编码器输出与这些注意力权重的线性组合添加到解码器的输入中。
Jay Alammar 的这篇博文很好地说明了注意力(可视化最初来自 Tensor2Tensor 笔记本):

第二个可能有帮助的方法是使用双向模型作为编码器。我们将 GRU 编码器的 bidrectional 参数设置为 True,并将编码器线性输出层的输入数量加倍。
此外,我们现在需要设置隐藏状态:
hid = hid.view(2,self.n_layers, bs, self.n_hid).permute(1,2,0,3).contiguous()
hid = self.out_enc(self.hid_dp(hid).view(self.n_layers, bs, 2*self.n_hid))
从头开始重新运行的代码
from fastai.text import *
path = Config().data_path()
path = Config().data_path()/'giga-fren'
def seq2seq_collate(samples:BatchSamples, pad_idx:int=1, pad_first:bool=True, backwards:bool=False) -> Tuple[LongTensor, LongTensor]:"Function that collect samples and adds padding. Flips token order if needed"samples = to_data(samples)max_len_x,max_len_y = max([len(s[0]) for s in samples]),max([len(s[1]) for s in samples])res_x = torch.zeros(len(samples), max_len_x).long() + pad_idxres_y = torch.zeros(len(samples), max_len_y).long() + pad_idxif backwards: pad_first = not pad_firstfor i,s in enumerate(samples):if pad_first: res_x[i,-len(s[0]):],res_y[i,-len(s[1]):] = LongTensor(s[0]),LongTensor(s[1])else: res_x[i,:len(s[0])],res_y[i,:len(s[1])] = LongTensor(s[0]),LongTensor(s[1])if backwards: res_x,res_y = res_x.flip(1),res_y.flip(1)return res_x,res_y
class Seq2SeqDataBunch(TextDataBunch):"Create a `TextDataBunch` suitable for training an RNN classifier."@classmethoddef create(cls, train_ds, valid_ds, test_ds=None, path:PathOrStr='.', bs:int=32, val_bs:int=None, pad_idx=1,dl_tfms=None, pad_first=False, device:torch.device=None, no_check:bool=False, backwards:bool=False, **dl_kwargs) -> DataBunch:"Function that transform the `datasets` in a `DataBunch` for classification. Passes `**dl_kwargs` on to `DataLoader()`"datasets = cls._init_ds(train_ds, valid_ds, test_ds)val_bs = ifnone(val_bs, bs)collate_fn = partial(seq2seq_collate, pad_idx=pad_idx, pad_first=pad_first, backwards=backwards)train_sampler = SortishSampler(datasets[0].x, key=lambda t: len(datasets[0][t][0].data), bs=bs//2)train_dl = DataLoader(datasets[0], batch_size=bs, sampler=train_sampler, drop_last=True, **dl_kwargs)dataloaders = [train_dl]for ds in datasets[1:]:lengths = [len(t) for t in ds.x.items]sampler = SortSampler(ds.x, key=lengths.__getitem__)dataloaders.append(DataLoader(ds, batch_size=val_bs, sampler=sampler, **dl_kwargs))return cls(*dataloaders, path=path, device=device, collate_fn=collate_fn, no_check=no_check)
class Seq2SeqTextList(TextList):_bunch = Seq2SeqDataBunch_label_cls = TextList
data = load_data(path)
model_path = Config().model_path()
emb_enc = torch.load(model_path/'fr_emb.pth')
emb_dec = torch.load(model_path/'en_emb.pth')
def seq2seq_loss(out, targ, pad_idx=1):bs,targ_len = targ.size()_,out_len,vs = out.size()if targ_len>out_len: out = F.pad(out, (0,0,0,targ_len-out_len,0,0), value=pad_idx)if out_len>targ_len: targ = F.pad(targ, (0,out_len-targ_len,0,0), value=pad_idx)return CrossEntropyFlat()(out, targ)
def seq2seq_acc(out, targ, pad_idx=1):bs,targ_len = targ.size()_,out_len,vs = out.size()if targ_len>out_len: out = F.pad(out, (0,0,0,targ_len-out_len,0,0), value=pad_idx)if out_len>targ_len: targ = F.pad(targ, (0,out_len-targ_len,0,0), value=pad_idx)out = out.argmax(2)return (out==targ).float().mean()
class NGram():def __init__(self, ngram, max_n=5000): self.ngram,self.max_n = ngram,max_ndef __eq__(self, other):if len(self.ngram) != len(other.ngram): return Falsereturn np.all(np.array(self.ngram) == np.array(other.ngram))def __hash__(self): return int(sum([o * self.max_n**i for i,o in enumerate(self.ngram)]))
def get_grams(x, n, max_n=5000):return x if n==1 else [NGram(x[i:i+n], max_n=max_n) for i in range(len(x)-n+1)]
def get_correct_ngrams(pred, targ, n, max_n=5000):pred_grams,targ_grams = get_grams(pred, n, max_n=max_n),get_grams(targ, n, max_n=max_n)pred_cnt,targ_cnt = Counter(pred_grams),Counter(targ_grams)return sum([min(c, targ_cnt[g]) for g,c in pred_cnt.items()]),len(pred_grams)
def get_predictions(learn, ds_type=DatasetType.Valid):learn.model.eval()inputs, targets, outputs = [],[],[]with torch.no_grad():for xb,yb in progress_bar(learn.dl(ds_type)):out = learn.model(xb)for x,y,z in zip(xb,yb,out):inputs.append(learn.data.train_ds.x.reconstruct(x))targets.append(learn.data.train_ds.y.reconstruct(y))outputs.append(learn.data.train_ds.y.reconstruct(z.argmax(1)))return inputs, targets, outputs
class CorpusBLEU(Callback):def __init__(self, vocab_sz):self.vocab_sz = vocab_szself.name = 'bleu'def on_epoch_begin(self, **kwargs):self.pred_len,self.targ_len,self.corrects,self.counts = 0,0,[0]*4,[0]*4def on_batch_end(self, last_output, last_target, **kwargs):last_output = last_output.argmax(dim=-1)for pred,targ in zip(last_output.cpu().numpy(),last_target.cpu().numpy()):self.pred_len += len(pred)self.targ_len += len(targ)for i in range(4):c,t = get_correct_ngrams(pred, targ, i+1, max_n=self.vocab_sz)self.corrects[i] += cself.counts[i] += tdef on_epoch_end(self, last_metrics, **kwargs):precs = [c/t for c,t in zip(self.corrects,self.counts)]len_penalty = exp(1 - self.targ_len/self.pred_len) if self.pred_len < self.targ_len else 1bleu = len_penalty * ((precs[0]*precs[1]*precs[2]*precs[3]) ** 0.25)return add_metrics(last_metrics, bleu)
class TeacherForcing(LearnerCallback):def __init__(self, learn, end_epoch):super().__init__(learn)self.end_epoch = end_epochdef on_batch_begin(self, last_input, last_target, train, **kwargs):if train: return {'last_input': [last_input, last_target]}def on_epoch_begin(self, epoch, **kwargs):self.learn.model.pr_force = 1 - epoch/self.end_epoch
实现注意力
class Seq2SeqRNN_attn(nn.Module):def __init__(self, emb_enc, emb_dec, nh, out_sl, nl=2, bos_idx=0, pad_idx=1):super().__init__()self.nl,self.nh,self.out_sl,self.pr_force = nl,nh,out_sl,1self.bos_idx,self.pad_idx = bos_idx,pad_idxself.emb_enc,self.emb_dec = emb_enc,emb_decself.emb_sz_enc,self.emb_sz_dec = emb_enc.embedding_dim,emb_dec.embedding_dimself.voc_sz_dec = emb_dec.num_embeddingsself.emb_enc_drop = nn.Dropout(0.15)self.gru_enc = nn.GRU(self.emb_sz_enc, nh, num_layers=nl, dropout=0.25, batch_first=True, bidirectional=True)self.out_enc = nn.Linear(2*nh, self.emb_sz_dec, bias=False)self.gru_dec = nn.GRU(self.emb_sz_dec + 2*nh, self.emb_sz_dec, num_layers=nl,dropout=0.1, batch_first=True)self.out_drop = nn.Dropout(0.35)self.out = nn.Linear(self.emb_sz_dec, self.voc_sz_dec)self.out.weight.data = self.emb_dec.weight.dataself.enc_att = nn.Linear(2*nh, self.emb_sz_dec, bias=False)self.hid_att = nn.Linear(self.emb_sz_dec, self.emb_sz_dec)self.V = self.init_param(self.emb_sz_dec)def encoder(self, bs, inp):h = self.initHidden(bs)emb = self.emb_enc_drop(self.emb_enc(inp))enc_out, hid = self.gru_enc(emb, 2*h)pre_hid = hid.view(2, self.nl, bs, self.nh).permute(1,2,0,3).contiguous()pre_hid = pre_hid.view(self.nl, bs, 2*self.nh)hid = self.out_enc(pre_hid)return hid,enc_outdef decoder(self, dec_inp, hid, enc_att, enc_out):hid_att = self.hid_att(hid[-1])# we have put enc_out and hid through linear layersu = torch.tanh(enc_att + hid_att[:,None])# we want to learn the importance of each time stepattn_wgts = F.softmax(u @ self.V, 1)# weighted average of enc_out (which is the output at every time step)ctx = (attn_wgts[...,None] * enc_out).sum(1)emb = self.emb_dec(dec_inp)# concatenate decoder embedding with context (we could have just# used the hidden state that came out of the decoder, if we weren't# using attention)outp, hid = self.gru_dec(torch.cat([emb, ctx], 1)[:,None], hid)outp = self.out(self.out_drop(outp[:,0]))return hid, outpdef show(self, nm,v):if False: print(f"{nm}={v[nm].shape}")def forward(self, inp, targ=None):bs, sl = inp.size()hid,enc_out = self.encoder(bs, inp)
# self.show("hid",vars())dec_inp = inp.new_zeros(bs).long() + self.bos_idxenc_att = self.enc_att(enc_out)res = []for i in range(self.out_sl):hid, outp = self.decoder(dec_inp, hid, enc_att, enc_out)res.append(outp)dec_inp = outp.max(1)[1]if (dec_inp==self.pad_idx).all(): breakif (targ is not None) and (random.random()<self.pr_force):if i>=targ.shape[1]: continuedec_inp = targ[:,i]return torch.stack(res, dim=1)def initHidden(self, bs): return one_param(self).new_zeros(2*self.nl, bs, self.nh)def init_param(self, *sz): return nn.Parameter(torch.randn(sz)/math.sqrt(sz[0]))
hid=torch.Size([2, 64, 300])
dec_inp=torch.Size([64])
enc_att=torch.Size([64, 30, 300])
hid_att=torch.Size([64, 300])
u=torch.Size([64, 30, 300])
attn_wgts=torch.Size([64, 30])
enc_out=torch.Size([64, 30, 512])
ctx=torch.Size([64, 512])
emb=torch.Size([64, 300])model = Seq2SeqRNN_attn(emb_enc, emb_dec, 256, 30)
learn = Learner(data, model, loss_func=seq2seq_loss, metrics=[seq2seq_acc, CorpusBLEU(len(data.y.vocab.itos))],callback_fns=partial(TeacherForcing, end_epoch=30))
learn.lr_find()
learn.recorder.plot()
learn.fit_one_cycle(15, 3e-3)
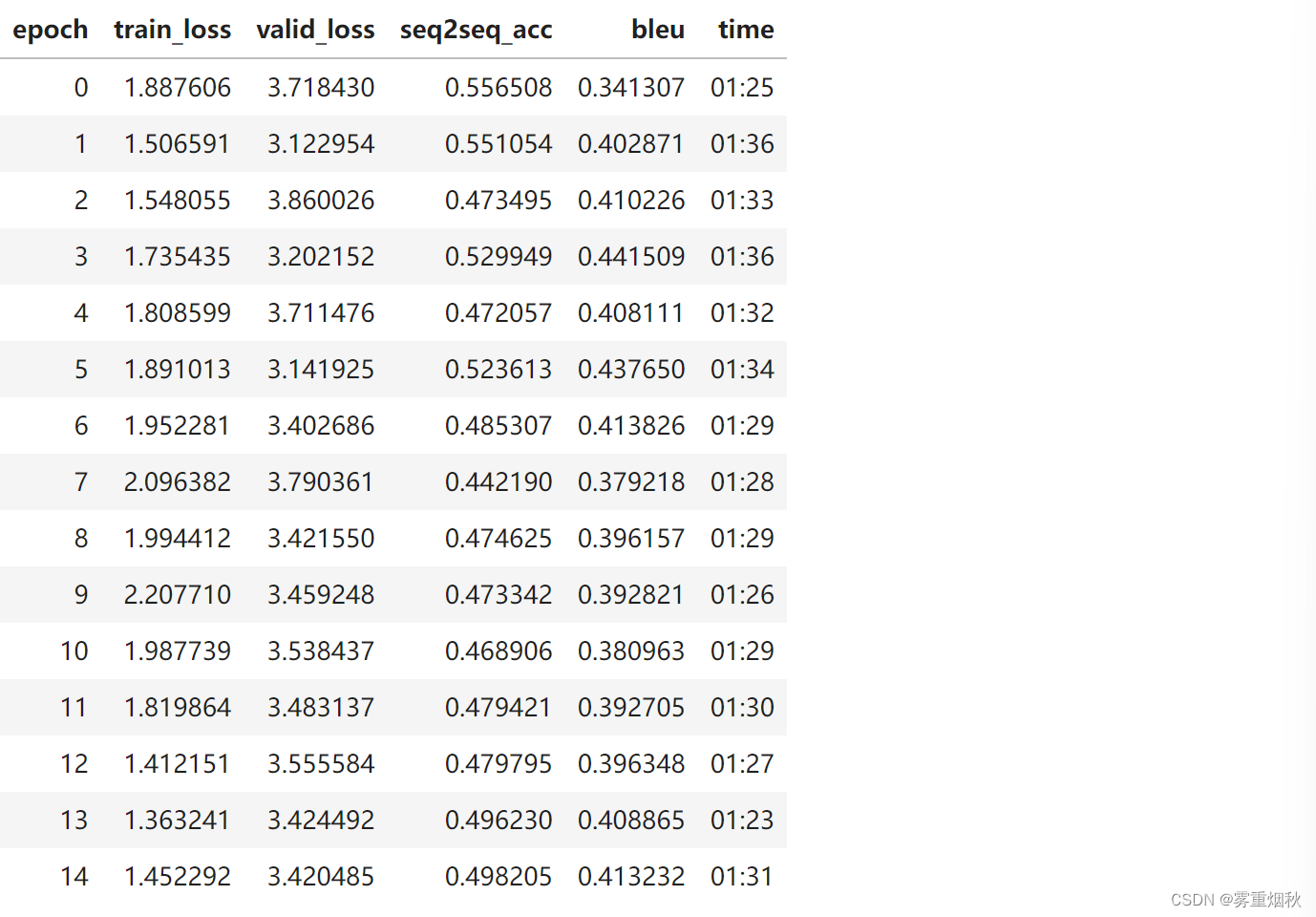
inputs, targets, outputs = get_predictions(learn)
inputs[700], targets[700], outputs[700]
(Text xxbos qui a le pouvoir de modifier le règlement sur les poids et mesures et le règlement sur l'inspection de l'électricité et du gaz ?,Text xxbos who has the authority to change the electricity and gas inspection regulations and the weights and measures regulations ?,Text xxbos what do we regulations and and regulations ? ?)
inputs[701], targets[701], outputs[701]
(Text xxbos ´ ` ou sont xxunk leurs grandes convictions en ce qui a trait a la ` ` ´ transparence et a la responsabilite ?,Text xxbos what happened to their great xxunk about transparency and accountability ?,Text xxbos what are the and and and and and and and and and to to ? ?)
inputs[4002], targets[4002], outputs[4002]
(Text xxbos quelles ressources votre communauté possède - t - elle qui favoriseraient la guérison ?,Text xxbos what resources exist in your community that would promote recovery ?,Text xxbos what resources would your community community community community community community ?)
神经文本生成
from seq2seq import *
path = Config().data_path()/'giga-fren'
data = load_data(path)
model_path = Config().model_path()
emb_enc = torch.load(model_path/'fr_emb.pth')
emb_dec = torch.load(model_path/'en_emb.pth')
class Seq2SeqRNN_attn(nn.Module):def __init__(self, emb_enc, emb_dec, nh, out_sl, nl=2, bos_idx=0, pad_idx=1):super().__init__()self.nl,self.nh,self.out_sl,self.pr_force = nl,nh,out_sl,1self.bos_idx,self.pad_idx = bos_idx,pad_idxself.emb_enc,self.emb_dec = emb_enc,emb_decself.emb_sz_enc,self.emb_sz_dec = emb_enc.embedding_dim,emb_dec.embedding_dimself.voc_sz_dec = emb_dec.num_embeddingsself.emb_enc_drop = nn.Dropout(0.15)self.gru_enc = nn.GRU(self.emb_sz_enc, nh, num_layers=nl, dropout=0.25, batch_first=True, bidirectional=True)self.out_enc = nn.Linear(2*nh, self.emb_sz_dec, bias=False)self.gru_dec = nn.GRU(self.emb_sz_dec + 2*nh, self.emb_sz_dec, num_layers=nl,dropout=0.1, batch_first=True)self.out_drop = nn.Dropout(0.35)self.out = nn.Linear(self.emb_sz_dec, self.voc_sz_dec)self.out.weight.data = self.emb_dec.weight.dataself.enc_att = nn.Linear(2*nh, self.emb_sz_dec, bias=False)self.hid_att = nn.Linear(self.emb_sz_dec, self.emb_sz_dec)self.V = self.init_param(self.emb_sz_dec)def encoder(self, bs, inp):h = self.initHidden(bs)emb = self.emb_enc_drop(self.emb_enc(inp))enc_out, hid = self.gru_enc(emb, 2*h)pre_hid = hid.view(2, self.nl, bs, self.nh).permute(1,2,0,3).contiguous()pre_hid = pre_hid.view(self.nl, bs, 2*self.nh)hid = self.out_enc(pre_hid)return hid,enc_outdef decoder(self, dec_inp, hid, enc_att, enc_out):hid_att = self.hid_att(hid[-1])u = torch.tanh(enc_att + hid_att[:,None])attn_wgts = F.softmax(u @ self.V, 1)ctx = (attn_wgts[...,None] * enc_out).sum(1)emb = self.emb_dec(dec_inp)outp, hid = self.gru_dec(torch.cat([emb, ctx], 1)[:,None], hid)outp = self.out(self.out_drop(outp[:,0]))return hid, outpdef forward(self, inp, targ=None):bs, sl = inp.size()hid,enc_out = self.encoder(bs, inp)dec_inp = inp.new_zeros(bs).long() + self.bos_idxenc_att = self.enc_att(enc_out)res = []for i in range(self.out_sl):hid, outp = self.decoder(dec_inp, hid, enc_att, enc_out)res.append(outp)dec_inp = outp.max(1)[1]if (dec_inp==self.pad_idx).all(): breakif (targ is not None) and (random.random()<self.pr_force):if i>=targ.shape[1]: continuedec_inp = targ[:,i]return torch.stack(res, dim=1)def initHidden(self, bs): return one_param(self).new_zeros(2*self.nl, bs, self.nh)def init_param(self, *sz): return nn.Parameter(torch.randn(sz)/math.sqrt(sz[0]))
model = Seq2SeqRNN_attn(emb_enc, emb_dec, 256, 30)
learn = Learner(data, model, loss_func=seq2seq_loss, metrics=seq2seq_acc,callback_fns=partial(TeacherForcing, end_epoch=30))
learn.fit_one_cycle(5, 3e-3)
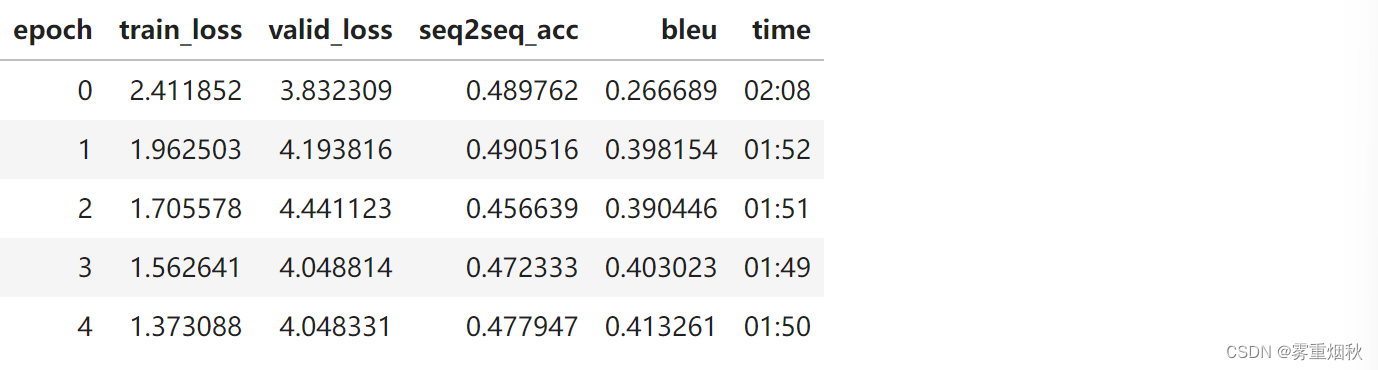
learn.save('5')
def preds_acts(learn, ds_type=DatasetType.Valid):"Same as `get_predictions` but also returns non-reconstructed activations"learn.model.eval()ds = learn.data.train_dsrxs,rys,rzs,xs,ys,zs = [],[],[],[],[],[] # 'r' == 'reconstructed'with torch.no_grad():for xb,yb in progress_bar(learn.dl(ds_type)):out = learn.model(xb)for x,y,z in zip(xb,yb,out):rxs.append(ds.x.reconstruct(x))rys.append(ds.y.reconstruct(y))preds = z.argmax(1)rzs.append(ds.y.reconstruct(preds))for a,b in zip([xs,ys,zs],[x,y,z]): a.append(b)return rxs,rys,rzs,xs,ys,zs
rxs,rys,rzs,xs,ys,zs = preds_acts(learn)
idx=701
rx,ry,rz = rxs[idx],rys[idx],rzs[idx]
x,y,z = xs[idx],ys[idx],zs[idx]
rx,ry,rz
(Text xxbos quelles sont les lacunes qui existent encore dans notre connaissance du travail autonome et sur lesquelles les recherches devraient se concentrer à l’avenir ?,Text xxbos what gaps remain in our knowledge of xxunk on which future research should focus ?,Text xxbos what gaps are needed in our work and what is the research of the work and what research will be in place to future ?)
def select_topk(outp, k=5):probs = F.softmax(outp,dim=-1)vals,idxs = probs.topk(k, dim=-1)return idxs[torch.randint(k, (1,))]
摘自《神经文本退化的奇怪案例》。
from random import choicedef select_nucleus(outp, p=0.5):probs = F.softmax(outp,dim=-1)idxs = torch.argsort(probs, descending=True)res,cumsum = [],0.for idx in idxs:res.append(idx)cumsum += probs[idx]if cumsum>p: return idxs.new_tensor([choice(res)])
def decode(self, inp):inp = inp[None]bs, sl = inp.size()hid,enc_out = self.encoder(bs, inp)dec_inp = inp.new_zeros(bs).long() + self.bos_idxenc_att = self.enc_att(enc_out)res = []for i in range(self.out_sl):hid, outp = self.decoder(dec_inp, hid, enc_att, enc_out)dec_inp = select_nucleus(outp[0], p=0.3)
# dec_inp = select_topk(outp[0], k=2)res.append(dec_inp)if (dec_inp==self.pad_idx).all(): breakreturn torch.cat(res)
def predict_with_decode(learn, x, y):learn.model.eval()ds = learn.data.train_dswith torch.no_grad():out = decode(learn.model, x)rx = ds.x.reconstruct(x)ry = ds.y.reconstruct(y)rz = ds.y.reconstruct(out)return rx,ry,rz
rx,ry,rz = predict_with_decode(learn, x, y)
rz
Text xxbos what gaps are needed in our understanding of work and security and how research will need to be put in place ?
这篇关于course-nlp——7-seq2seq-translation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!