本文主要是介绍基于知识库的问答KBQA:seq2seq模型实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 前言
0.1 问题描述
基于知识图谱的自动问答(Question Answering over Knowledge Base, 即 KBQA)问题的大概形式是,预先给定一个知识库(比如Freebase),知识库中包含着大量的先验知识数据,然后利用这些知识资源自动回答自然语言形态的问题(比如“肉夹馍是江苏的美食吗”,“虵今年多大了”等人民群众喜闻乐见的问题)。
0.2 什么是知识库
知识库(Knowledge Base),或者说,知识图谱(Knowledge Graph),是以知识为主要单位,实体为主要载体,包含着现实生活中人们对万千事物的认知与各类事实的庞大数据库。一般来说,知识(或者事实)主要以三元组形式呈现:<头实体,关系,尾实体>,其中实体即人、地点、或特定概念等万物。举例来说,<虵,改变了,中国> 就是一条简单的三元组示例,其中头尾皆为知识库中固有的实体单元。
0.3 方法框架
先放个图
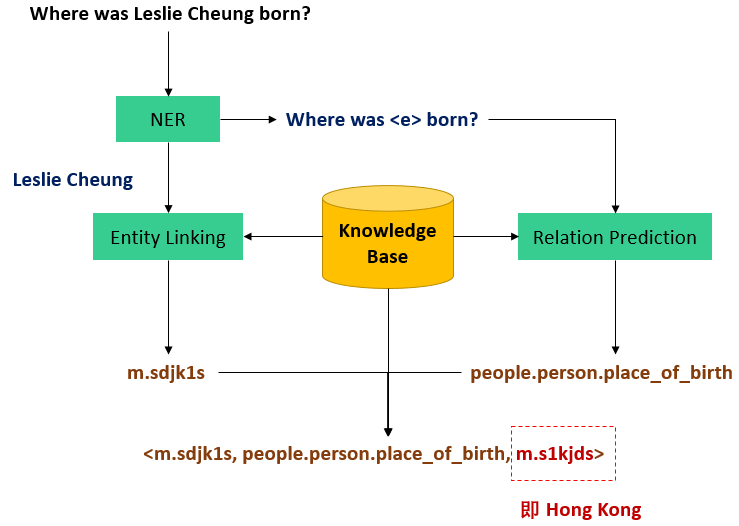
对着图说:假设要回答“Where was Leslie Cheung born”这个问题,主要分四步:
- 实体识别(Named Entity Recognition),即把问题中的主要实体的名字从问题中抽出来,这样才知道应该去知识库中搜取哪个实体的信息来解决问题,即图中把“Leslie Cheung”这个人名抽出来;
- 实体链接(Entity Linking),把抽取出来的实体名和知识库中具体的实体对应起来,做这一步是因为,由于同名实体的存在,名字不是实体的唯一标识,实体独一无二的编号(id)才是,找到了实体名没卵用,必须要对应到知识库中具体的实体id,才能在知识库中把具体实体找到,获取相关信息。即图中将“Leslie Cheung”映射到“m.sdjk1s”这个 id 上(Freebase 的实体 id 是这个格式的)。这一步会存在一些问题,比如直接搜“姓名”叫“Leslie Cheung”的实体是搜不到的,因为“Leslie Cheung”其实是某个实体的“外文名”,他的“姓名”叫“张国荣”,以及有时候还会有多个叫“Leslie Cheung”的人。具体解决方式后面再说。
- 关系预测(Relation Prediction),根据原问句中除去实体名以外的其他词语预测出应该从知识库中哪个关系去解答这个问题,是整个问题中最主要的一步。即图中从“Where was <e> born”预测出“people.person.place_of_birth”(Freebase 的关系名格式,翻译过来就是“出生地”)这个关系应该连接着问题的主要实体“Leslie Cheung”与这个问题的答案。
- 找到了实体与关系,直接在知识库中把对应的三元组检索出来,即 “<m.sdjk1s,
people.person.place_of_birth, m.s1kjds>”,那么这条三元组的尾实体,即“m.s1kjds”就是问题的答案,查询其名字,就是“Hong Kong”。
0.4 源代码与数据下载:
- 代码:其中 data/origin 目录下是问答数据集的原始数据,鉴于实体识别与链接做起来比较麻烦,所以直接给出中间数据,data/seq2seq 目录下是已经经过前两步,可以直接用于训练 seq2seq 模型的数据
https://github.com/wavewangyue/kbqagithub.com/wavewangyue/kbqa
- word2vec (WikiAnswers 数据预训练) 模型下载:https://pan.baidu.com/s/1N34hCbYJY3QolJVbBYWkwg 提取码 mgnt
- 数据集:SimpleQuestions & WebQuestions 学术界问答领域比较喜闻乐见的两个数据集了,当然都是英文;另外,知识库用的是 Freebase,权威知识库,当然也是英文
- 环境:Python3,Pytorch0.4.1
依照惯例,还是先上结论
KBQA 的解决方法有两个方向
-
- 通过逻辑表达式直接生成 SPARQL(数据库查询语言,类似 SQL 那种)查数据库
- 就是按上面说的框架那四步,我也是按照这个框架来做
具体做法五花八门,模型各式各样,文中所用的 seq2seq 也只是一个简单实践,效果上比较如下图,out-of-state now 是目前(2017年底)最好结果,APVA-TURBO 是我最近在做的一篇论文
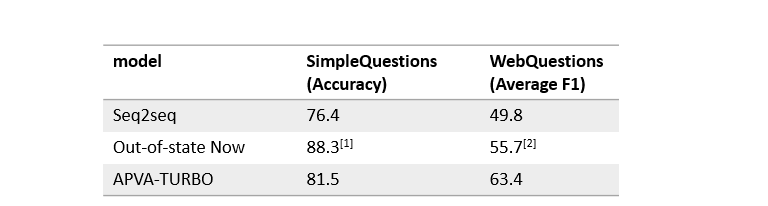
[1] (EMNLP 2017) No Need to Pay Attention: Simple Recurrent Neural Networks Work !
[2] (NAACL 2016) Question Answering over Knowledge Base using Factual Memory Networks
简单的 seq2seq 效果还不错,虽然跟最好成绩有很大差距,但是还不错。后来我又加入了一些比如 KB embedding,Verification Mechanism,Turbo Training 等补丁上去,变成现在的 APVA-TURBO 模型,在 WebQuestions 上已经快领先 8 个点了,但是这里不细讲了,直接发一个论文链接,感兴趣的可以深入研究
The APVA-TURBO Approach To Question Answering in Knowledge Base. Yue Wang, Richong Zhang, Cheng Xu and Yongyi Mao. Published 2018 in COLING
http://aclweb.org/anthology/C18-1170
无关的吐槽发泄一下:论文在半个月前投 ACL2018 的,然后因为段落的格式问题被拒了(是的,因为格式问题,WTF???),快毕业了 A 没有了太遗憾了,现在准备这星期投 COLING 2018,哎,这就是命

下面正式开编,说一下按照这个框架来做 KBQA 任务的完整流程以及 pytorch 的实现,个人浅见,随性发挥,可能有不对的地方,反正你也不能打我
P.S. 这个文章不是讲 APVA-TURBO 的啊,只是想说一些简单的科普性质的东西,对 APVA-TURBO 感兴趣的话可以看论文或者加微信交流
1. 实体识别 + 实体链接
先贴一下数据集的原始数据形态,拿 SimpleQuestions 的数据贴一下,WebQuestions 的数据要比这个丑陋一些,就不提了。数据量方面,SimpleQuestions 的 train/test 是 75910/21687 ,WebQuestions 是 3778/2032

SimpleQuestions 的原始数据中,每一行一条数据,分四列,分别是头实体id,关系,尾实体id与问句内容
1.1 实体识别(Named Entity Recognition, NER)
首先训练实体识别模型,目标是给一个问题,能把问题中的实体名(entity mention)找到,方法就是喜闻乐见的 BIO 序列标注方法,模型用 NER 任务普遍使用的 LSTM+CRF 增强效果,序列标注在上一篇文章说过,“B” 即实体名的开始单词,“I” 为实体名的中间单词(或结尾词),“O” 为不是实体名的单词,输入一串单词序列,输出一串长度相同的由 BIO 组成的字母序列
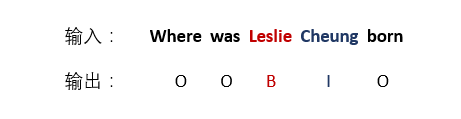
方法有了,构造训练数据。基于上面的 SimpleQuestions 数据,把已经给定的实体id转换成实体名,再在原问句中根据编辑距离把相似度最高的短语(N-gram词组)标出来

训练数据有了,开始训练模型,不是主要内容不细说了,放一个模型图
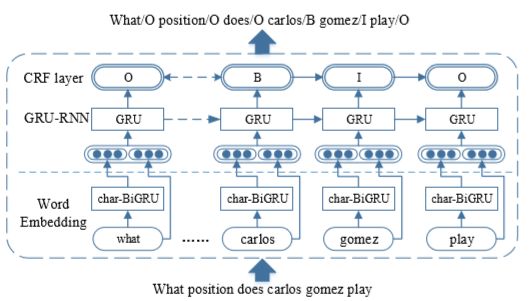
我把 LSTM 换成了 GRU,不过都一个意思。这里 char-BiGRU 是从字母维度上的 embedding,目的就是为了增加特征,辅助增强 word embedding 的效果。最后的 CRF layer,是为了学习 BIO tag 之间的规律,改善最终输出结果。LSTM+CRF 比较经典的模型,网上教程应该挺多的,不细讲了
1.2 实体链接(Entity Linking)
找到了实体名,然后就是对应到 KB 中的具体实体。这一步做法比较简单,但是对最终效果的影响还是比较大的,包括在 KB 中能不能找到对应的实体,以及找到多个实体怎么排序的问题。直接说方法,首先收集 KB 中所有实体的名称(包括“name”“外文名”“别名”等等的),然后构建单词到实体 id 的反向 map 表,举个例子
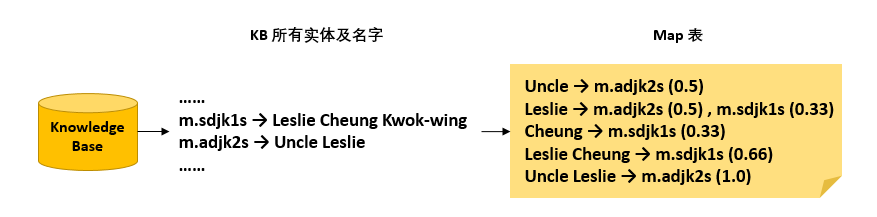
这里 Leslie 可以链接到两个实体,因为两个实体的名字中都含有 Leslie 这个单词。注意每一个括号里的数字,代表词(或词组)链接到这个实体的打分,计算方式就是这个词组的单词个数除以这个实体完整实体名的单词个数。
这里打分也可以适当考虑实体的知名度进去,比如“Leslie Cheung Kwok-wing”这个实体知名度更高,“Uncle Leslie”没怎么听说过,所以用户提这个问题更有可能是问关于前者的,所以前者的打分也要适当提高一些
当然排序策略可以很多,也可以加更多特征进去
1.3 关系预测数据处理
终于进入正题了。经过之前两步的数据处理,现在的数据基本是这个样子

simple.source.test

simple.target.test
上面是输入下面是期望输出,输入中每条数据就是一个问句,由若干个单词组成的序列,其中已经把实体名拿走,用“<e>”这个标记词进行替换。输出是一个关系名,虽然由于 Freebase 的关系格式定义,一个关系名由三个用“.”拼接的单词组成,但是这里只把他当成一个完整的单词看待。其实关系预测本质上就是一个文本分类问题,给定所有的关系列表,输入一个文本,分类到一个最可能的关系上
在这一步结束后,得到了预测出的关系名,再加上上一步实体链接得到的具体实体,就能从知识库中找到三元组,找到答案,从而解决问题了。下面具体讲关系预测的模型及实现代码细节
2. 关系预测
先上一个模型图
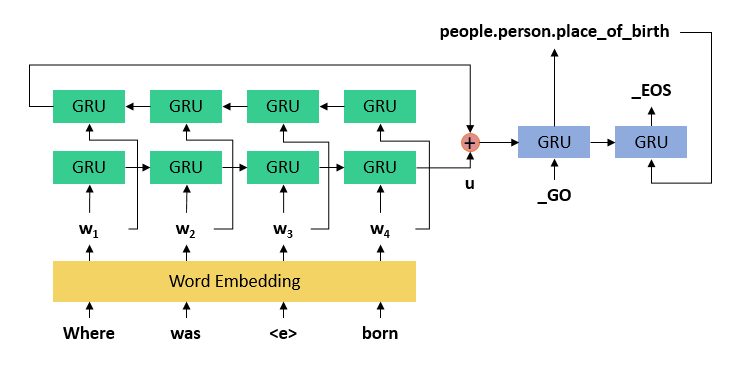
最简单的没有任何添加剂的纯天然的 seq2seq 模型,即 encoder-decoder 架构(当然也可以再加 attention 什么的上去),左边(绿色)是一个双向 GRU(或 LSTM)(双向即两层,一层正向走一层反向走,然后把两层的最后结果加到一起,只用单向也可以)作为 encoder,能把整个问题压缩成一个向量 u,右边是一个单向 GRU ,把向量 u 解压缩成一个关系,或关系序列,_GO 是表示序列开始生成的标记词,_EOS 是表示序列生成完毕的标记词
下面详细说一下为什么会是关系“序列”。这也是本来一个简单的多分类任务为什么不用简单的 RNN 分类模型而用 seq2seq 这种序列生成模型的原因
有时候仅靠一个关系(一跳)并不能找到最终答案,比如“张国荣曾在哪个国家留学”,为了回答这个问题需要输出两个关系(两跳),第一跳是从“张国荣”通过“毕业院校”这个关系找到“英国里兹大学”这个实体,第二跳是从“英国里兹大学”通过“所属国家”这个关系找到“英国”这个最终答案。所以原来“张国荣出生在哪里”这个问题对应的输出序列是“出生地,_EOS”,而“张国荣曾在哪个国家留学”对应的输出序列就变成了“毕业院校,所属国家,_EOS”,需要输出的关系序列长度是不一样的,这也是 seq2seq 模型解决问答问题的优势所在
2.1 Encoder
好了,编完了,下面上代码,首先是 Encoder
class EncoderRNN(nn.Module):def __init__(self, config):super(EncoderRNN, self).__init__()self.input_size = config.source_vocab_sizeself.hidden_size = config.hidden_sizeself.num_layers = 1self.dropout = 0.1self.embedding = nn.Embedding(self.input_size, self.hidden_size)self.gru = nn.GRU(self.hidden_size, self.hidden_size, self.num_layers, dropout=self.dropout, bidirectional=True)def forward(self, input_seqs, input_lengths, hidden=None):# Note: we run this all at once (over multiple batches of multiple sequences)# input: S*Bembedded = self.embedding(input_seqs) # S*B*Dpacked = torch.nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)outputs, hidden = self.gru(packed, hidden) outputs, output_lengths = torch.nn.utils.rnn.pad_packed_sequence(outputs)#outputs: S*B*2D#hidden: 2*B*Doutputs = outputs[:, :, :self.hidden_size] + outputs[:, : ,self.hidden_size:] # Sum bidirectional outputshidden = hidden[:1, :, :] + hidden[-1:, :, :]#outputs: S*B*D#hidden: 1*B*Dreturn outputs, hiddensource_vocab_size 是所有数据中涉及到的单词词表大小,hidden_size 是单词被压缩成的词向量维度,设 batch 的大小为 B,batch 内每个输入序列长度为 S,首先是形状 S*B 的张量进来,然后经过 embedding 得到 S*B*D 的张量,然后直接进 GRU ,得到结果 outputs 以及 hidden,这里因为使用了双向 GRU 所以 outputs 出来是 S*B*2D 的,hidden 出来是 2*B*D 的,需要压缩一下,outputs 在模型后面没有用到可以无所谓。这里再细说一下这个 pack_padded_sequence 的作用,这个函数机制真的是让我只想双击666
对于使用了 batch 的 GRU(或LSTM)来说,要求输入的 batch 中的每一个序列长度相同。但是一个 batch 里的问题有长有短,怎么可能都相同呢,所以就需要用一个没有意义的标记词(“_PAD”)把所有问题填充(Padding)到相同的长度,举个例子
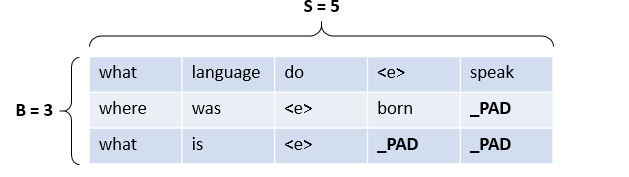
在这个大小为 3 的 batch 里 ,后两个问题因为长度不足都被 padding 到了 5 个单词,但是在推到 GRU 里运行的时候,我们只希望它们前面有效的单词进去就可以了,后面的 _PAD 填充过多时会严重影响最后出来的效果,bucket 机制或许可以适当解决这个问题,但是 pytorch 提供的这个 pack_padded_sequence 非常完美,它可以自动保证 _PAD 不会真正进入到 GRU 中影响效果,只需要你事先把 input_seqs 先按长度从大到小排列一下,然后把排序后每个序列的真正长度 input_lengths 传进来,比如这个例子里 input_lengths 就是 [5,4,3],然后包装好放进 GRU 里, GRU 运行完了再用 pad_packed_sequence 这个函数解包一下,就 OK 了
现在是2019.12,我想收回上面那段话。在转用tensorflow之后,表示这个跟dynamic_rnn的sequence_length相比简直弱爆了,这玩意还得把输入seqs按长度排序????输出完了还得手动写代码把seqs顺序还原回来???WTF
2.2 Decoder
class DecoderRNN(nn.Module):def __init__(self, config):super(DecoderRNN, self).__init__()# Define parametersself.hidden_size = config.hidden_sizeself.output_size = config.target_vocab_sizeself.num_layers = 1self.dropout_p = 0.1# Define layersself.embedding = nn.Embedding(self.output_size, self.hidden_size)self.dropout = nn.Dropout(self.dropout_p)self.gru = nn.GRU(self.hidden_size, self.hidden_size, self.num_layers, dropout=self.dropout_p)self.out = nn.Linear(self.hidden_size, self.output_size)def forward(self, word_input, prev_hidden):# Get the embedding of the current input word (last output word)# word input: B# prev_hidden: 1*B*Dbatch_size = word_input.size(0)embedded = self.embedding(word_input) # B*Dembedded = self.dropout(embedded)embedded = embedded.unsqueeze(0) # 1*B*Drnn_output, hidden = self.gru(embedded, prev_hidden)# rnn_output : 1*B*D# hidden : 1*B*Drnn_output = rnn_output.squeeze(0) # B*Doutput = self.out(rnn_output) # B*target_vocab_sizereturn output, hiddenDecoder 也比较简单,但是跟上面 Encoder 有个很大的区别就是这里 Decoder 一次只处理一个单词,假设期望输出序列长度是 M,需要运行 M 次,而上面 Encoder 是一次就把长度为 N 的序列都处理完。Decoder 不能这么做的原因是在它的下一次输入是上一次输出,只有先运行一遍得到第一个单词才能再去得到第二个单词,而不像 Encoder 一开始就知道整个输入序列。
2.3 run_epoch
encoder 和 decoder 搭完了,下面就是怎么把他们拼起来了,一个 S*D 的 batch 来了,先跑 encoder,得到 1*S*D 的 encoder_hidden,就是模型图中最重要的 u,然后设最长输出序列长度为 t,分 t 次运行 decoder 模型,一次输入一个单词,最初的输入单词为标记词“_GO”,并将 u 作为初始隐层塞到 decoder 里。
encoder = EncoderRNN(config)
decoder = DecoderRNN(config)
encoder_optimizer = optim.SGD(encoder.parameters(), lr=config.learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=config.learning_rate)def run_epoch(source_batch, source_lengths, target_batch, target_lengths, encoder, decoder, encoder_optimizer, decoder_optimizer, TRAIN=True):if TRAIN:encoder_optimizer.zero_grad()decoder_optimizer.zero_grad()loss = 0else:encoder.train(False)decoder.train(False)batch_size = source_batch.size()[1]encoder_outputs, encoder_hidden = encoder(source_batch, source_lengths, None)decoder_input = Variable(torch.LongTensor([target_w2i["_GO"]] * batch_size))decoder_hidden = encoder_hiddenmax_target_length = max(target_lengths)all_decoder_outputs = Variable(torch.zeros(max_target_length, batch_size, decoder.output_size))if USE_CUDA:decoder_input = decoder_input.cuda()all_decoder_outputs = all_decoder_outputs.cuda()for t in range(max_target_length):decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)all_decoder_outputs[t] = decoder_outputdecoder_input = target_batch[t]# S * B * vocab_size -> B * S * vocab_sizeall_decoder_outputs = all_decoder_outputs.transpose(0, 1).contiguous()target_batch = target_batch.transpose(0, 1).contiguous()if TRAIN: # trainloss = seq2seq_model.masked_cross_entropy(all_decoder_outputs, target_batch, target_lengths)loss.backward()encoder_optimizer.step()decoder_optimizer.step()return loss.data[0]else: # testhits = 0for b in range(batch_size):topv, topi = all_decoder_outputs[b].data.topk(1)pre = topi.squeeze(1)[:target_lengths[b]]sta = target_batch[b][:target_lengths[b]].dataif torch.equal(pre, sta):hits += 1encoder.train(True)decoder.train(True)return float(hits)*100 / batch_size先定义好参数优化器 optimizer,这里使用随机梯度下降算法(SGD),然后每输入一个 batch,运行一次 run_epoch 函数,计算一次 loss,更新一次参数,然后结束,返回这次 loss 的值;当 TRAIN=False,也就是测试的时候,不计算 loss 也不更新参数,直接对比真实输出与期望输出,返回准确度。
这里计算 loss 用了 masked_cross_entropy 这个函数,这个函数是我从网上抄来的,出处是
https://github.com/spro/practical-pytorch/blob/master/seq2seq-translation/masked_cross_entropy.py
他这个 loss 计算有一个很大的好处是什么呢,这就又涉及到 padding 的问题了,刚才说输入序列需要 padding,并且通过 pack_padded_sequence 避免了 _PAD 带来的影响,而输出序列也需要 padding,也需要一种措施避免影响,还是举个例子
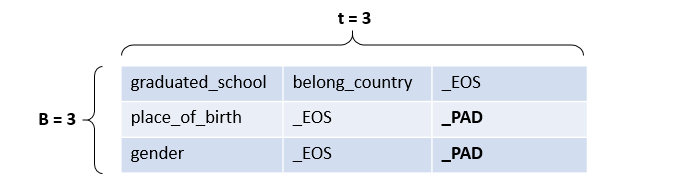
在这个大小为 3 的 batch 中,最长输出序列 t=3,后两条数据因为长度不足被加入了 _PAD 标记词,但是计算 loss 并更新参数的时候,我们只希望计算除 _PAD 以外的位置上的 loss,并不想关心 _PAD 上的 loss,因为没有意义,且会给效果带来影响。masked_cross_entropy 这个函数就通过一个 mask 矩阵把 _PAD 位置上的 loss 过滤掉了,非常流弊。具体不再细说了,可以看源码
3. 训练及测试
终于一切基础都搭完可以开始训练了,也没啥可以说的,直接放代码吧
for iter in range(0, num_epoch):source_batch, source_lengths, target_batch, target_lengths = get_batch(train_pairs, batch_size)loss = run_epoch(source_batch, source_lengths, target_batch, target_lengths, encoder, decoder, encoder_optimizer, decoder_optimizer, TRAIN=True) print_loss_total += lossif iter % print_every == 0:print "-----------------------------"print "iter " + str(iter) + "/" + str(num_epoch)print "time: "+time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))print_loss_avg = (print_loss_total / print_every) if iter > 0 else print_loss_totalprint_loss_total = 0print "loss: "+str(print_loss_avg) source_batch, source_lengths, target_batch, target_lengths = get_batch(test_pairs, batch_size)precision = run_epoch(source_batch, source_lengths, target_batch, target_lengths, encoder, decoder, encoder_optimizer, decoder_optimizer, TRAIN=False)print "precision: "+str(precision)if iter % save_every == 0:torch.save(encoder, config.checkpoint_path+"/encoder.model.iter"+str(iter)+".pth")torch.save(decoder, config.checkpoint_path+"/decoder.model.iter"+str(iter)+".pth")一共训练 num_epoch 轮,每轮通过 get_batch 这个函数制作一个 batch,运行一次 run_epoch 函数,更新一次模型,然后每隔 print_every 轮进行一次测试并打印结果,每隔 save_every 轮保存一次模型。get_batch 这个函数具体细节不写了,可以看源码。
这篇关于基于知识库的问答KBQA:seq2seq模型实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





