kbqa专题

KBQA 图谱问答论文整理
公众号 系统之神与我同在 本文来自知乎和微信公众号收集 综述 1.Core techniques of question answering systems over knowledge bases: a survey. Dennis Diefenbach, Vanessa Lopez, Kamal Singh, Pierre Maret. Knowledge and Information
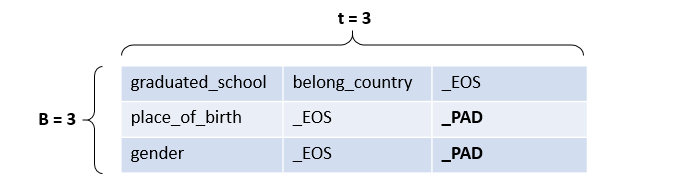
基于知识库的问答KBQA:seq2seq模型实践
0. 前言 0.1 问题描述 基于知识图谱的自动问答(Question Answering over Knowledge Base, 即 KBQA)问题的大概形式是,预先给定一个知识库(比如Freebase),知识库中包含着大量的先验知识数据,然后利用这些知识资源自动回答自然语言形态的问题(比如“肉夹馍是江苏的美食吗”,“虵今年多大了”等人民群众喜闻乐见的问题)。 0.2 什么是知识库 知

LLM应用实战:当图谱问答(KBQA)集成大模型(三)
1. 背景 最近比较忙(也有点茫),本qiang~想切入多模态大模型领域,所以一直在潜心研读中... 本次的更新内容主要是响应图谱问答集成LLM项目中反馈问题的优化总结,对KBQA集成LLM不熟悉的客官可以翻翻之前的文章《LLM应用实战:当KBQA集成LLM》、《LLM应用实战:当KBQA集成LLM(二)》。 针对KBQA集成LLM项目,该系列文章主要是通过大模型来代替传统KBQA的相关功能
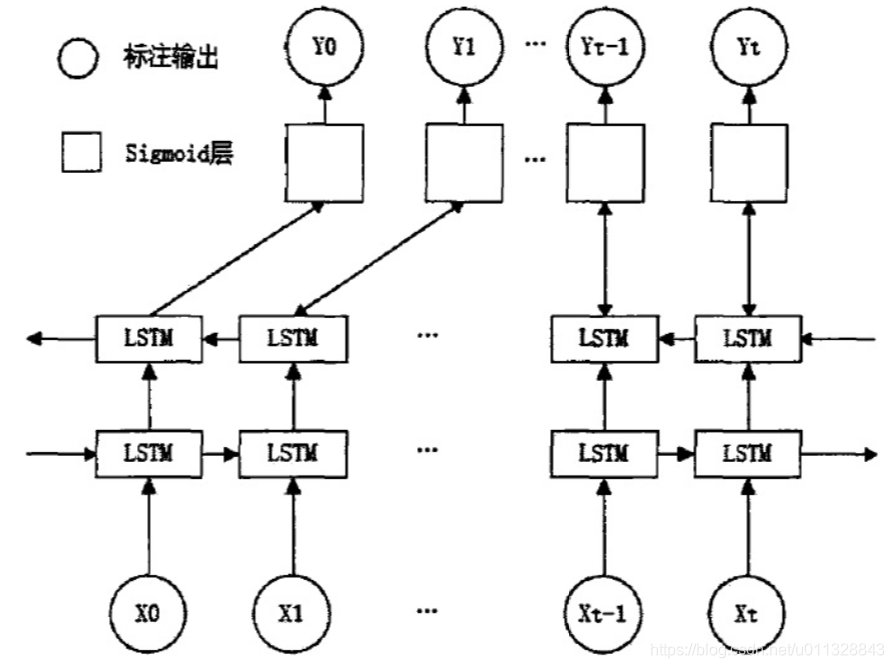

基于语义解析的KBQA论文
简单KBQA Template-based question answering over RDF data. Unger, Christina, Lorenz Bühmann, Jens Lehmann, A. N. Ngomo, D. Gerber, P. Cimiano. WWW(2012). [PDF]Large-scale semantic parsing via schema mat
基于kbqa 的复旦大学论文解释 learning question answering over QA corpora and knowledge bases(二)
我们表示第i项其中,,所以,所以我们建立了QA与X的似然线性关系, (13) 最大似然估计QA就是等价最大似然估计X,(2)通过边际化联合概率,得到,基于总体的模板t和谓语p,似然如公式(14),我们阐述整个过程如图4,
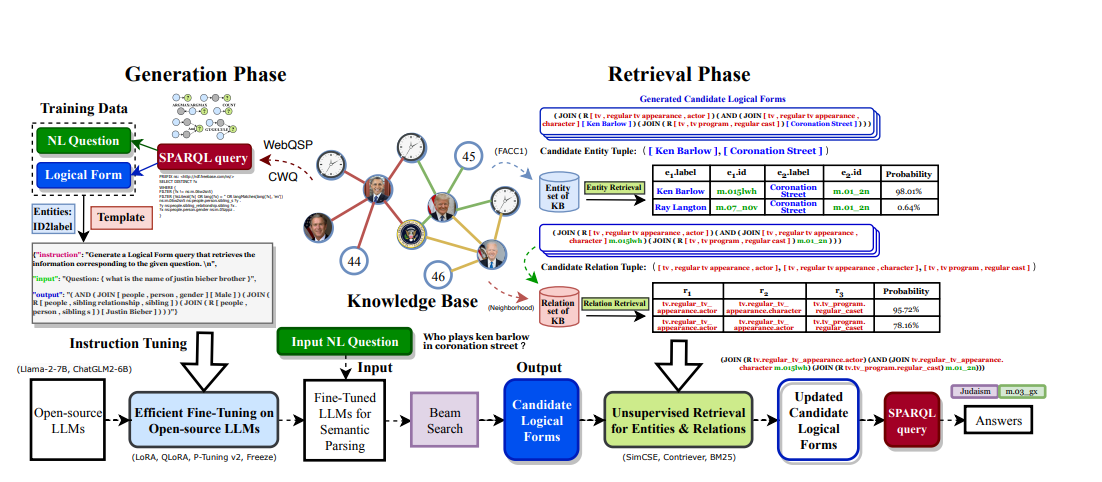
【大模型 知识图谱】ChatKBQA:KBQA知识图谱问答 + 大模型
ChatKBQA:KBQA知识图谱问答 + 大模型 提出背景传统方法处理流程ChatKBQA处理流程对比优势 总结ChatKBQA框架概览特征1:逻辑形式生成特征2:无监督实体和关系检索特征3:参数高效的微调特征4:GQoT 可解释的查询执行特征5:错误减少和避免 论文:https://arxiv.org/abs/2310.08975 代码:https://gith

基于REfo的KBQA实现及其实例
1、利用结巴分词对中文句子进行分词,词性标注(词性标注使用的词性兼容了ICTCLAS汉语词性标准) 参考https://gist.github.com/luw2007/6016931 2、将词的文本和词性打包,视为“词对象”,对应 :class:Word(token,pos) 3、利用REfo模块对词进行对象级别(object-level)的正则匹配,判断问题属于3中类型中的哪一种,并产生对应的
知识图谱构建7——基于REFO的简单知识问答(KBQA)
知识图谱构建7——基于REFO的简单知识问答(KBQA) 实例结构: 利用get_dict.sh脚本将数据库电影名和演员名抽取出来,生成字典文件,用于扩展jieba分词,脚本一些命令可以参考: shell教程: http://www.runoob.com/linux/linux-shell-io-redirections.html 博客:命令行数据科学工具笔记 https://blog.im

快速入门 KBQA问答系统的实现
KBQA问答系统的实现 首先默认你是已经学会了如何构建知识图谱,并且学会用sparql语言查询里面的知识库里面的知识。如果不会,请看下面的链接 使用D2RQ把关系数据库的信息转化为rdf文件。 使用jena 构建知识数据库tdb,然后学会如何查询相关知识 源码在GitHub这里 目录结构很简单: KBQA /kbqa 里面有四个文件,分别是 word_tag.py ## 这个主要是用来分词的

3.jieba分词+es实现KBQA问答系统
1.jieba分词 jieba分词号称是最好的中文分词器,目前Python版本在运维,Java版本很久没有更新了。 jieba能实现什么功能呢?我们通过下面的TEST可以看下: 我们实现一个例子: 如:系统提问“拍拍贷利率是多少” @Testpublic void testReadJiebaDict(){/**JiebaSegmenter:分词器,WordDictionary:词典*/Strin
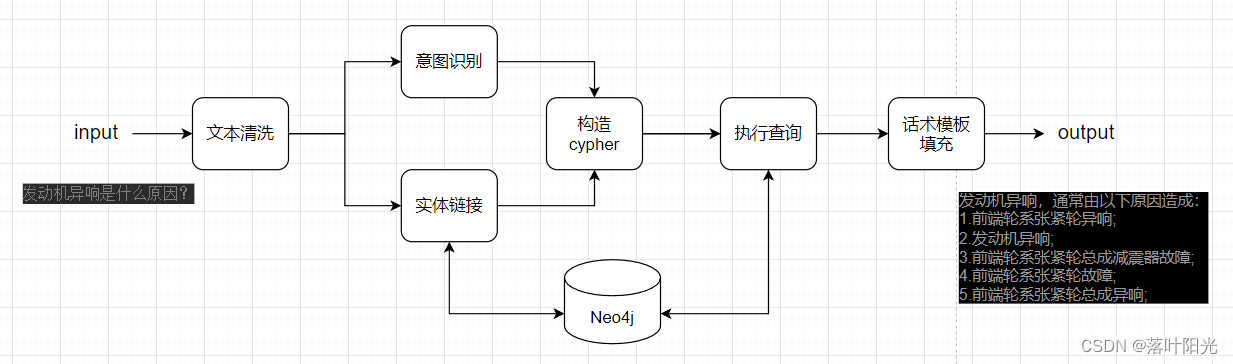
【知识图谱】KBQA核心架构小结
KBQA是指基于知识图谱的问答系统,是知识图谱的重要应用形式,基于知识图谱的问答和基于LLM的问答殊途同归。 KBQA是一个系统,由多种功能模块组成,其核心架构梳理如下: 下面对各个模块简单小结 文本清洗 只有是文本的领域都基本上要做一些清洗和预处理操作,比如标点符号统一,无效字符删除等。 另外,在这个阶段需要认真评估应用场景的问题描述方式和KG构建阶段的数据特点是否一致(专业化说叫数据分布