本文主要是介绍KBQA学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
评价标准:召回率,准确率,F1-Score
方法:自然语言查询–>意图识别(Intention Recognition)–>实体链指(Entity Linking)+关系识别(Relation Detection) -->查询语句拼装(Query Construction)–>返回结果选择(Answering Selection)
KBQA除了 基于模板的方法 之外,还有 基于语义解析 和 基于深度学习 等方法
- 三元组表示
“奥巴马出生在火奴鲁鲁。” 可以用三元组表示为 (BarackObama, PlaceOfBirth, Honolulu)
(实体entity,实体关系relation,实体entity)
技术基础
一、词语的向量化表示
-
离散表示 One-Hot模型(维度高造成很大开销,词与词关系隔离)
-
分布式表示 思想:词的语义可以通过上下文信息确认,通过无监督学习,将文本信息映射到定长的向量表示
-
Word2Vec两种模型
CBOW模型(Continous Bags-of-Words Model) 利用上下文预测目标词语
Skip-Gram模型(Contin-uous Skip-Gram Model) 利用当前词语预测上下文
CBOW复杂度公式 N ∗ D + D ∗ log v N*D+D*{\log{v}} N∗D+D∗logv其中N是上下文窗口大小,D是词向量维度,V是词典大小
模型最大化目标函数
L c b o w = 1 T ∑ t = 1 T log p ( ω t ∣ C o n t e x t ( ω t ) ) L_{cbow}=\frac{1}{T} {\sum_{t=1}^T}{\log{p}({ω_t|Context(ω_t))}} Lcbow=T1t=1∑Tlogp(ωt∣Context(ωt))Skip-Gram模型 利用当前词语预测上下文
Skip-Gram复杂度公式 C ∗ ( D + D ∗ l o g ( V ) ) C*(D+D*log(V)) C∗(D+D∗log(V))
模型的最大化目标函数
L S k i p − G r a m = 1 T ∑ t = 1 T ∑ − c ≤ j ≤ c , j ≠ 0 log p ( ω t + j ∣ ω t ) L_{Skip-Gram}=\frac{1}{T}{\sum_{t=1}^T}{\sum_{-c≤j≤c,j≠0}}{\log{p}({ω_{t+j}|ω_t})} LSkip−Gram=T1t=1∑T−c≤j≤c,j=0∑logp(ωt+j∣ωt)
二、神经网络
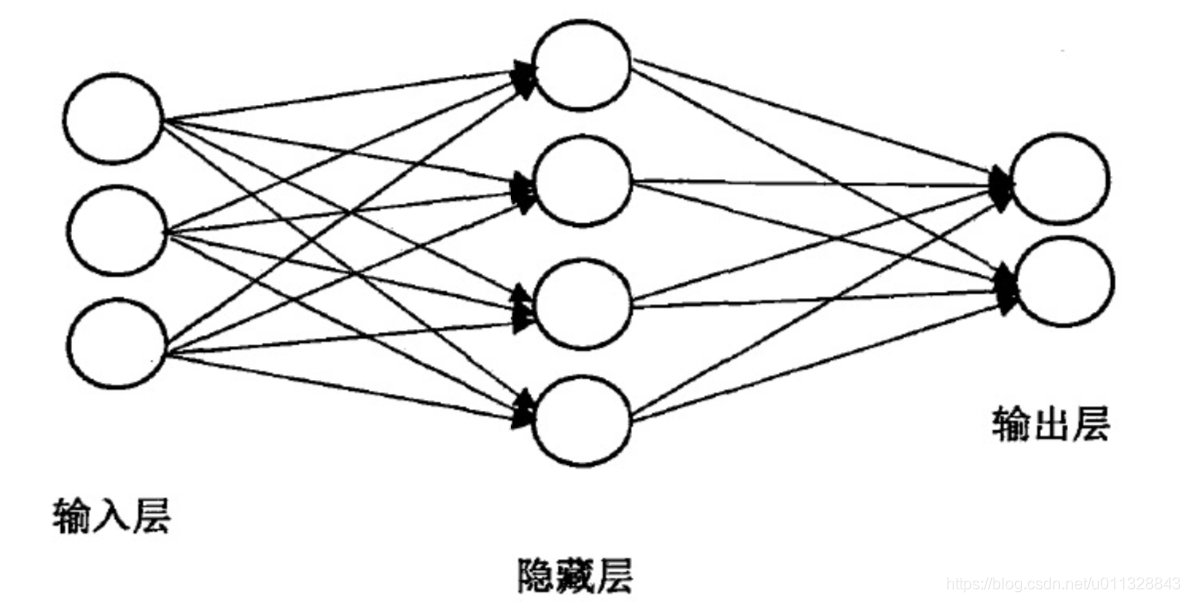
如图所示,这是一个三层神经网络模型,包括输入层(input layer)、隐藏层(hidden layer)、输出层(output layer)
2.1 卷积神经网络(CNN)
如图所示,卷积神经网络本质上是由卷积层、池化层、全连接层构成的深层神经网络。通过卷积层、池化层的结合,构成多个卷积组,然后逐层提取特征信息,最后通过全连接层得到最终的特征信息。
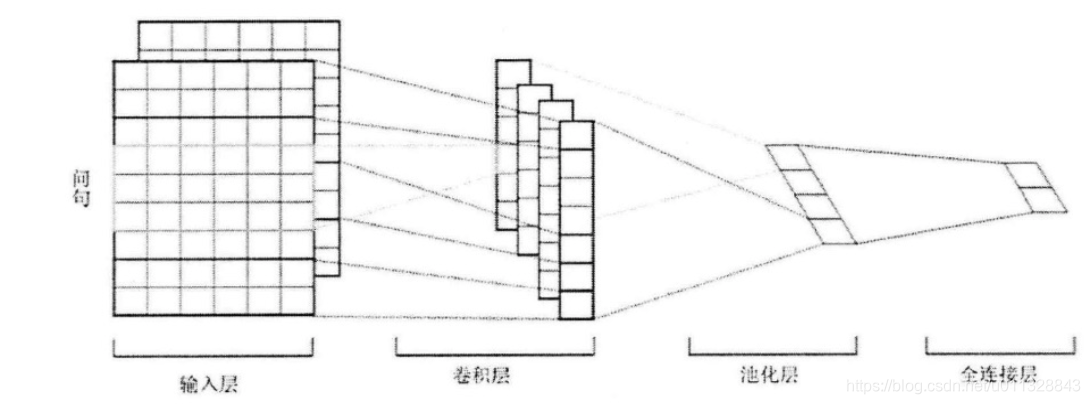
卷积神经网络主要特点是降采样、局部连接、以及权值共享
- 局部连接:通过感知小部分的区域来降低参数数量,提供特征拟合的能力
- 池化层:更进一步降低输出参数数量,提高CNN的泛化能力
- 权值共享:使一些基本特征能够被重复使用,共享网络参数并提高神经网络的训练效果
2.1.1 卷积层
是指“滑动窗口”与矩阵重叠局部区域间的线性运算,如图所示。
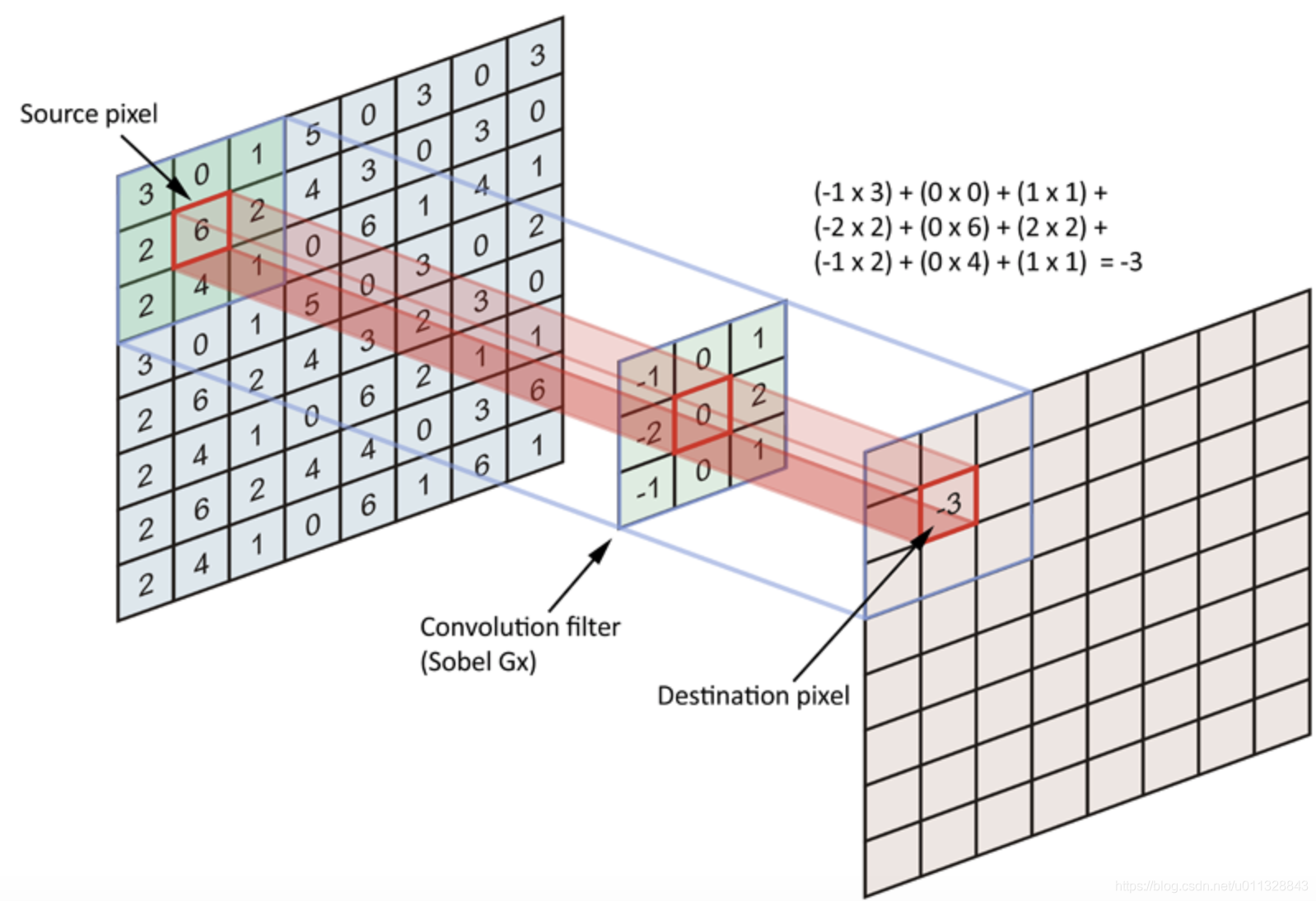
图中的“滑动窗口”(也叫卷积核)大小3*3,运算过程:滑动窗口从左上方开始,由左往右,由上至下,单次移动方向不变,距离(步长)固定。根据卷积核大小以及参数的不同,设置不同的卷积核可以提取到不同的特征。
以上图所示,卷积运算的公式是
Z = ∑ i = 1 d ∑ j = 1 d X m + i , n + j W i , j + b Z=\sum_{i=1}^{d}{\sum_{j=1}^{d}{X_{m+i,n+j}W_{i,j}}+b} Z=i=1∑dj=1∑dXm+i,n+jWi,j+b
其中W是卷积核,X代表输入的矩阵向量(图像,文本),b是偏移参数,D是窗口的高度和宽度,m、n代表“滑动窗口”局部区域的索引图右边展现的是卷积运算结果矩阵Z。卷积层的最终输出公式: C i , j = g ( Z i , j ) C_{i,j}=g(Z_{i,j}) Ci,j=g(Zi,j)
其中g(·)表示signmoid、tanh、relu等激活函数。
2.1.2 池化层
池化层对的任务是从输出中提取局部特征,通过筛选减少参数量。一般采用的Pooling方法有MaxPooling(取局部最大值,也叫最大池化法)、Mean-Pooling(取局部平均值,也叫平均池化法)等。
Pooling操作的好处:
①可以使神经网络的最终输出可以固定长度
②输出可以很方便地加入到另外的神经网络
2.2 循环神经网络(RNN)
利用有向循环网络的结构来充分保留序列信息,记忆模型历史信息。在RNN中,当前神经元的输出跟序列中的其他神经元的输出相关。RNN中t时刻的节点与t-1时刻节点相连接,使隐藏层同层的节点不在相互独立。如图所示,上一时刻的输出与当前时刻输入一起送入当前节点进行计算。
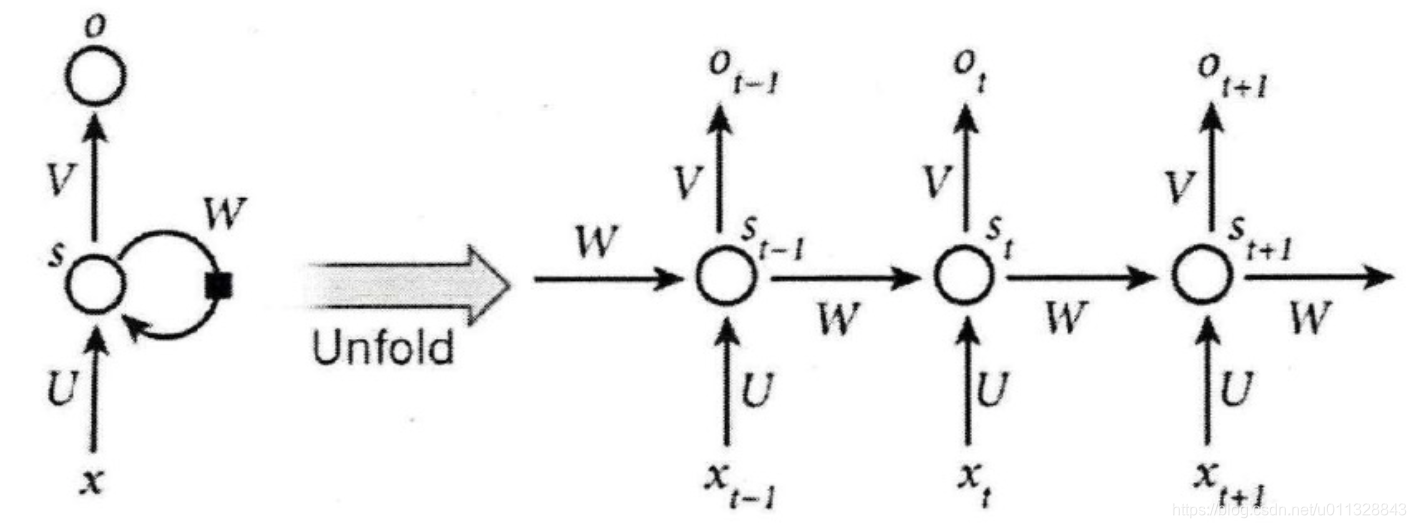
RNN的输入序列X={X0,X1…Xt…},Xt是t时刻的输入。U表示输入层和隐藏层之间的网络参数,V表示隐藏层和输出层间的网络参数,W表示当前时刻和上一层的隐藏层的网络参数。
RNN的计算方式:
S t = f ( U x t + W s t − 1 + b 1 ) S_t=f(Ux_t+Ws_{t-1}+b1) St=f(Uxt+Wst−1+b1)
O t = g ( V S t + b 2 ) O_t=g(VS_{t}+b2) Ot=g(VSt+b2)
其中 S t S_t St代表t时刻隐藏层的输出状态, O t O_t Ot代表t时刻输出层的输出。当t=0时, S t − 1 S_{t-1} St−1可以为空
f(·)、g(·)为非线性激活函数,根据模型可以选择signmoid、tanh、relu等。
RNN由于循环结构而具有一定的记忆能力,但是实际条件下输入过长的条件下,极易出现梯度消失和梯度爆炸问题。为改进这类问题,研究者提出来更为复杂的模型,如GRU模型,长短期记忆模型,双向循环神经网络,深层双向循环神经网络模型。
智能问答算法及技术
一、概述
目前主流研究思路
① 基于语义解析的方法(Semantic Parsing-Based,SP-based)
构建语义解析器,利用语义解析器将自然语言转化成逻辑表达,然后通过逻辑表达式在结构化的知识图谱查询知识三元组,提取答案
② 基于信息检索的方法(Information Retrieve,IR-based)
利用问句中的语义信息在知识图谱中检索相关知识
随着深度学习技术的进步,研究者着手基于深度学习的知识图谱问答(Neural Network-Based,NN-based)方法。
优点:突破了传统神经网络在层数上的限制,可自定义层数,利用其强大的表征学习能力学习隐藏的语义信息。
两方面改进:
① 在SP-based框架下使用深度学习方法代替传统方法实现实体识别、关系映射等流程
②端到端(End2End)的生成式学习框架,利用神经网络将实体、关系以及问句转化成向量形式,通过问句关系向量和知识向量之间语义相似度判断是否为正确答案
二、基于语义解析的问答
在自然语言处理方法的基础上的问答在解析后,将信息转化成机器语言
局限性:都需要标记语料的逻辑形式做监督训练,且只能在谓词较少的领域才有较好的效果
通常采用的思路:降低监督数量、提高逻辑谓词数量
Berant等提出了一种不需要标注的语义解析器
语义解析的关键过程:
①词汇映射
构建一个词典将词语映射到知识三元组中的实体或者关系中来实现
②构建语法树
将语法树的节点自下向上两两合并来实现,最终得到的根节点就是问句的逻辑表达式
映射层:
难点:如何向自然语言问句中的短语映射成需要的谓词
常用的语义解析方法:模式匹配;远程监督;人工规则组合
构建层:
过程:自底向上分析问句并构建一棵语法树,需要较多的人工规则
三、基于深度学习的问答
借助大规模语料的训练有效的解决文本语义构建的问题,缓解语义解析方法带来的难以推断和难以大规模训练的问题。
研究成果:
Bordes等将基于嵌入的语义模型来解决基于知识图谱的回答问题,将自然语言问句和知识三元组表示为低维向量,通过余弦相似度找到相似的答案
Berant等在上面的基础上提出了针对基于嵌入的语言模型的改进,利用嵌入子图在答案向量中融入尽可能多的语义信息
Weston在记忆框架更进一步提出了基于记忆神经网络的大规模QA实现,支持复杂度更高的推理功能
Yih等将基于知识图谱的问答分为实体识别及映射、关系映射两个步骤,分别利用两个卷积神经网络模型来完成整个映射过程
yang等将实体间的映射和关系映射成一个整体的过程,与上面的类似
Yih提出的Muli-Column CNN模型从上下文信息、答案路径、答案类型等多角度分析,利用多个CNN模型来抽取信息,并通过累计的打分方式来排列候选答案顺序。
yang等在MCCNN模型基础上引入了注意力机制,关注不同词对最后排序的影响,同时引入底层知识库作为问答过程的全局信息,集成更多的知识库信息到答案的向量表示中,有助于解决问句理解中的词汇不足、信息量过少的问题
zhang等通过不同方式融入注意力机制来获取不同的问句表达形式
中文领域:
xie等人分别在实体识别和属性链接过程中引入了神经网络模型
yang等人利用机器学习的GBDT方法完成实体识别,而属性链接则结合传统NBSVM模型和深度学习中卷积神经网络
lai等人利用分布式向量进行余弦相似度计算,结合人工构建特征,针对知识库层次单独构建细粒度的分词方法进行属性链接
王银丽等针对FAQ问句匹配设计并实现了限定领域的智能问答系统
杜泽宇等在CRF的实体识别算法和Word2Vec属性链接算法的基础上设计了一个基于中文知识图谱的电商领域问答系统算法框架(CEQA)
三、智能问答算法设计
3.1 框架
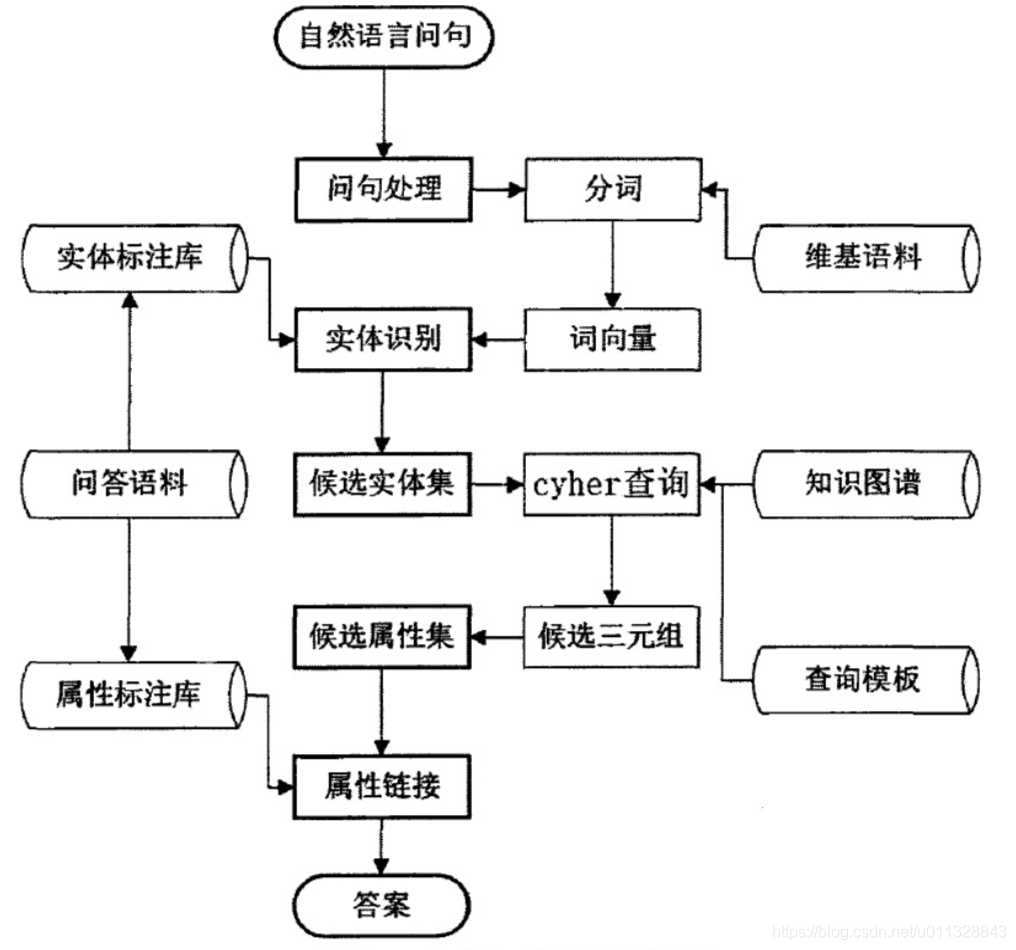
- 自然语言问句:指的是用户的提问
- 问句处理:分词,去停用词
- 词向量:利用词嵌入技术代替传统方法提取词语的潜在语义,将问句输入转化为模型词向量,主要用word2vec训练维基语料库
- 实体识别:获取问句中的实体名称
- 属性链接:找到问句询问的实体相关属性
- 候选三元组:描述问句可能的三元组,如<NER,PRO,VAL>(实体:NER,属性:pro,属性值:VAL)
- 查询构建:根据问题类别及查询模板,上下文流程识别的实体和属性信息,构建查询从知识库中获取候选三元组,从而构建候选属性集
3.2 实体识别算法
3.2.1 LSTM模型
选择LSTM的实体识别模型,提出了门结构

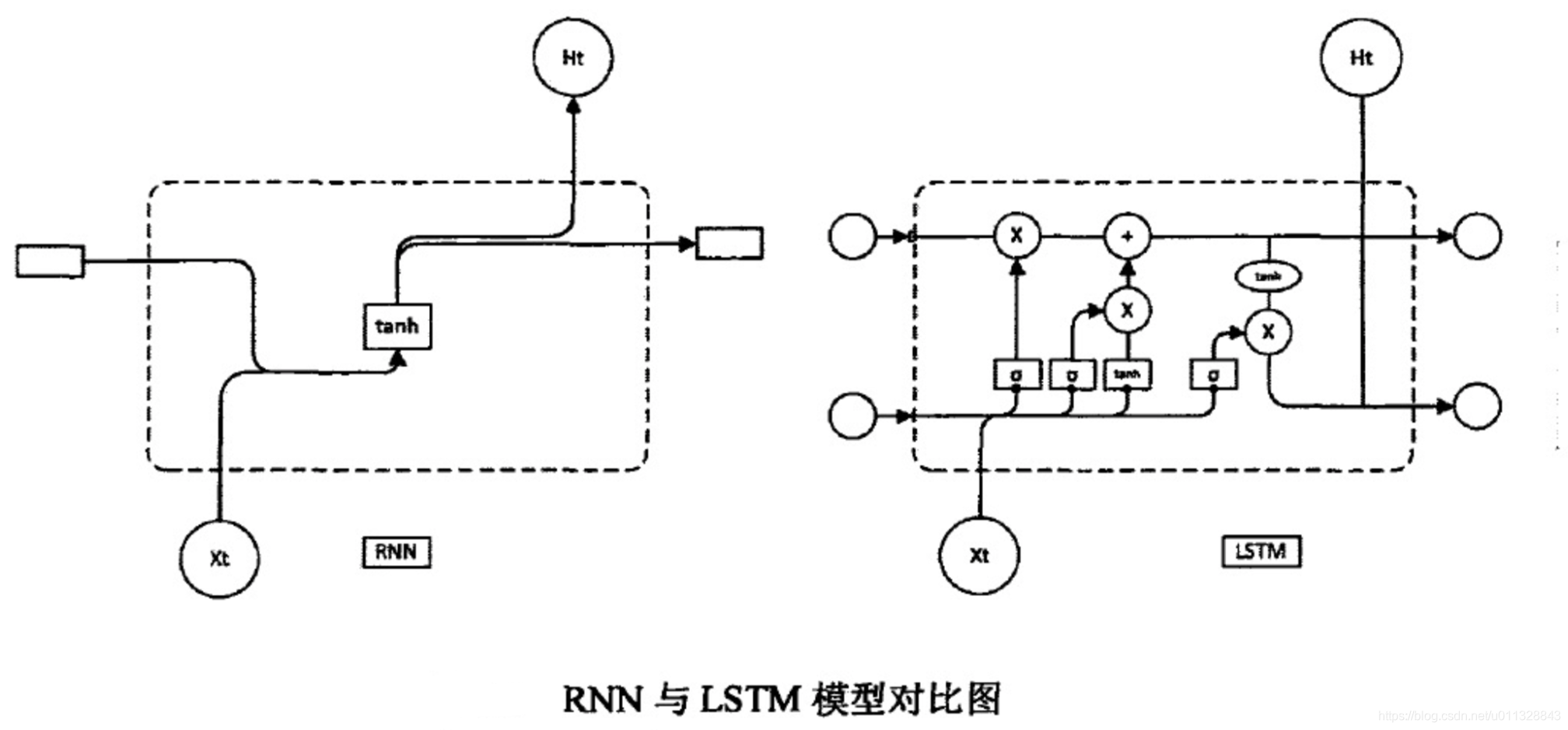
遗忘门决定细胞丢弃的数量,用signmoid函数来实现,计算公式如下:
f t = σ ( W f ⋅ h t − 1 + U f ⋅ x t + b f ) f_t=σ(W_f·h_{t-1}+U_f·x_t+b_f) ft=σ(Wf⋅ht−1+Uf⋅xt+bf)
其中, x t x_t xt表示当前时刻输入, h t − 1 h_{t-1} ht−1为上一时刻隐藏层的输出, U f U_f Uf代表输入信息的权重, W f W_f Wf代表遗忘门权重, b f b_f bf为偏置项
细胞更新时,首先通过输入确定更新的信息,然后根据得到的信息确定LSTM需要在新的细胞状态中的保存的信息
i t = σ ( W i ⋅ h t − 1 + U i ⋅ x t + b i ) i_t=σ(W_i·h_{t-1}+U_i·x_t+b_i) it=σ(Wi⋅ht−1+Ui⋅xt+bi)
c t ′ = t a n h ( W c ⋅ h t − 1 + U i ⋅ x t + b c ) c_t'=tanh(W_c·h_{t-1}+U_i·x_t+b_c) ct′=tanh(Wc⋅ht−1+Ui⋅xt+bc)
c t = f t ⋅ c t − 1 + i t ⋅ c t ′ c_t=f_t·c_{t-1}+i_t·c_t' ct=ft⋅ct−1+it⋅ct′
其中, U i 、 W I 、 U c 、 W c U_i、W_I、U_c、W_c Ui、WI、Uc、Wc均为参数矩阵, b i 、 b c b_i、b_c bi、bc为偏置参数, c t c_t ct为当前时刻的Cell状态, C t − 1 C_{t-1} Ct−1为上一时刻Cell状态
输出门最终决定了LSTM模型的输出向量,计算公式如下:
o t = σ ( W 0 ⋅ h t − 1 + U 0 ⋅ x t + b 0 ) o_t=σ(W_0·h_{t-1}+U_0·x_t+b_0) ot=σ(W0⋅ht−1+U0⋅xt+b0)
h t = o t ∗ t a n h ( C t ) h_t=o_t*tanh(C_t) ht=ot∗tanh(Ct)
其中, W 0 、 U 0 W_0、U_0 W0、U0为参数矩阵, b 0 b_0 b0为偏置参数, h t h_t ht为当前LSTM的最终输出
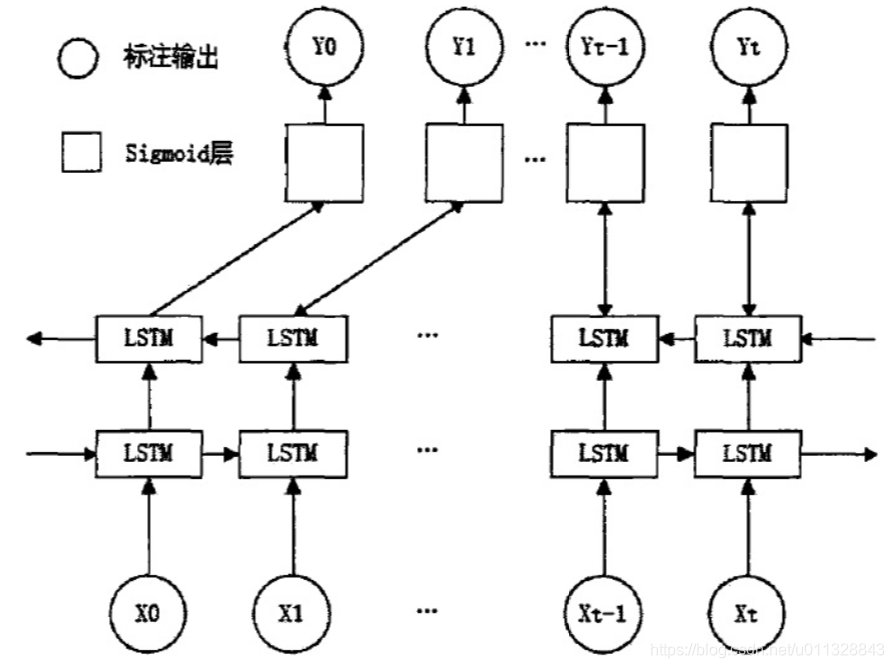
3.2.2 Bi-LSTM模型
双向长短期记忆网络(Bi-LSTM):采用两个LSTM单元对输入序列进行处理,输出向量为两个LSTM输出向量的拼接。这个模型分别训练前后向序列兼顾了上下文信息,可以提取深层次的语义信息
这篇关于KBQA学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









