本文主要是介绍Seq2Seq与Attention,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、seq2seq
对于序列数据常用的深度学习结构是RNN,但是普通RNN的结构存在缺陷,比如梯度消失,输入序列与输出序列要求等长等问题。这在许多情况下,比如翻译、生成总结等,RNN没有很好的效果。为了解决RNN梯度消失问题,提出了lstn结构,但是仍没有解决输入序列与输出序列要求等长的问题。
Sequence-to-sequence(seq2seq)解除了输入和输出序列等长和长度固定的问题。一个seq2seq最简单的结构如下:
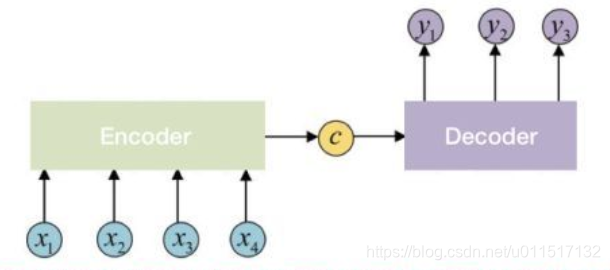
一个seq2seq模型包括三部分:Encoder,Context,Decoder。
Encoder负责将输入序列压缩成指定长度的向量,这个向量就是Context,可以看成是这个序列的语义,这个过程称为编码。
Decoder负责将Context解码,生成目标语句。
可以把Encoder和Decoder分别看成是RNN,在Encoder中根据输入数据生成一个语义编码C,C的获取方式有很多种,最简单的就是把Encoder中最后一个隐藏层赋值给C,也可以对最后一个隐藏状态做一个变换得到C,还可以对所有的隐藏状态做变换得到C。
拿到C之后,就可以用另一个RNN进行解码,这部分RNN被称为Decoder,具体做法就是将C当做之前的初始状态h0输入到Decoder中,C还有一种做法是将C当做每一步的输入。
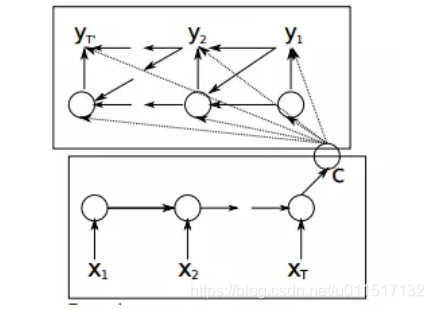
对上面结构进行一定的细化和优化:1.Encoder和Decoder都采用RNN结构,2.将C当单做每一个Decoder的输入;3.将Decoder在t-1时刻的输出当做t时刻的输入,于是seq2seq可以变为如下结构:
下面是利用seq2seq进行翻译的例子:
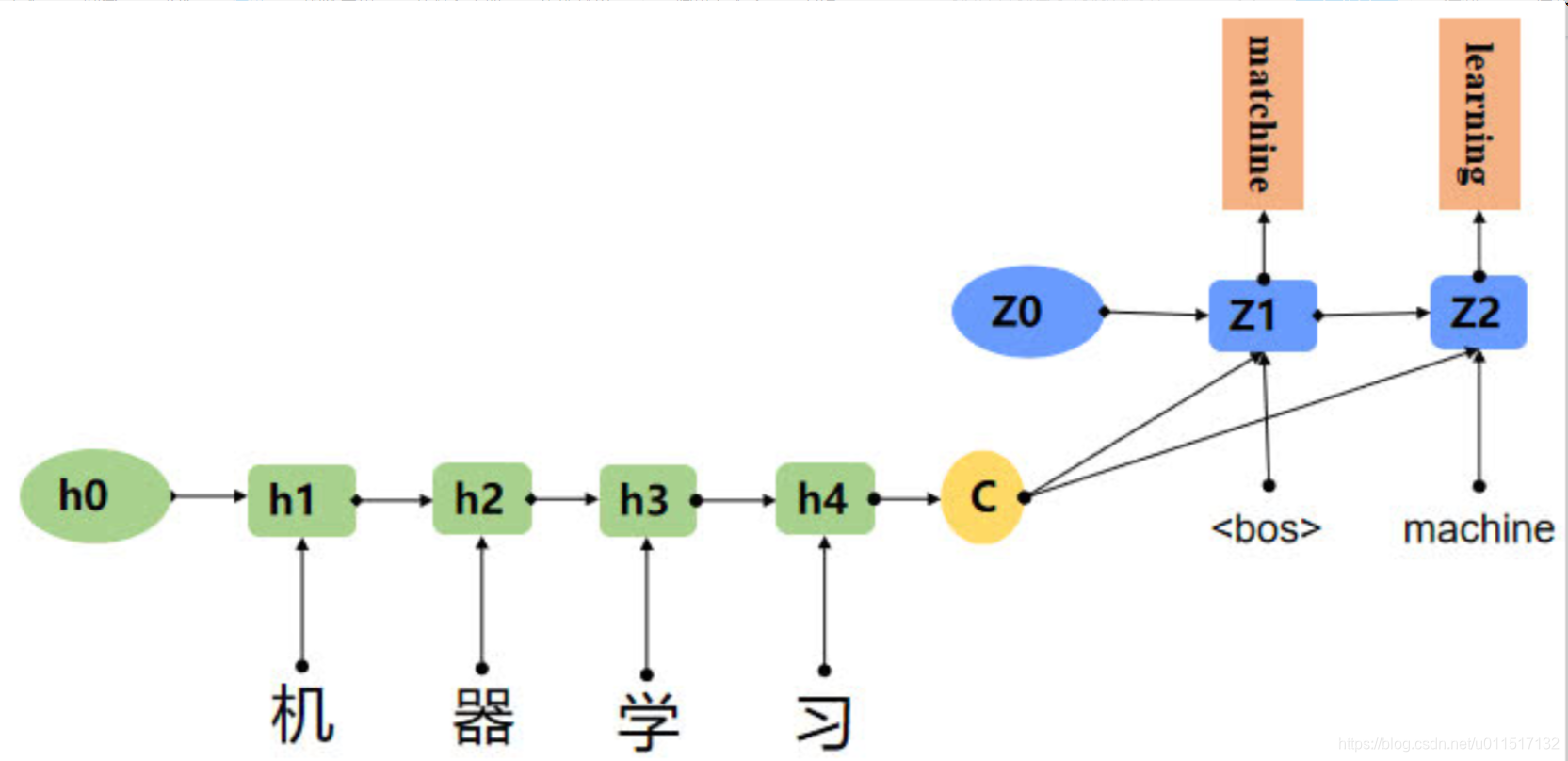
seq2seq解决RNN出现的问题,但是仍然存在问题。由于seq2seq的Decoder的输入是Encoder产生的Context,这个Context是不变的,这意味着原句子中任意单词对生成某个目标单词来说影响力都是相同的,这使得当输入序列较长的时候模型效果不佳。这就是模型没有体现出注意力的表现。
在上边那个例子中在生成“machine”时,“机”,“器”,“学”,""习"的贡献是相同的,很明显,这是不太合理,显然,“机”,“器”,对于翻译成"machine"更为重要。所以我们希望在模型翻译"machine"的时候,“机”,"器"两个字的贡献(权重)更大,当在翻译成"learning"时,“学”,"习"两个字贡献(权重)更大。
二、Attention
The attention model用来帮助解决机器翻译在句子过长时效果不佳的问题。
这种新的构架替输入句的每个文字都创造一个context vector,而非仅仅替输入句创造一个从最终的hidden state得来的context vector,举例来说,如果一个输入句有N个文字,就会产生N个context vector,好处是,每个context vector能够被更有效的译码。
加入Attention机制的模型架构如下图:
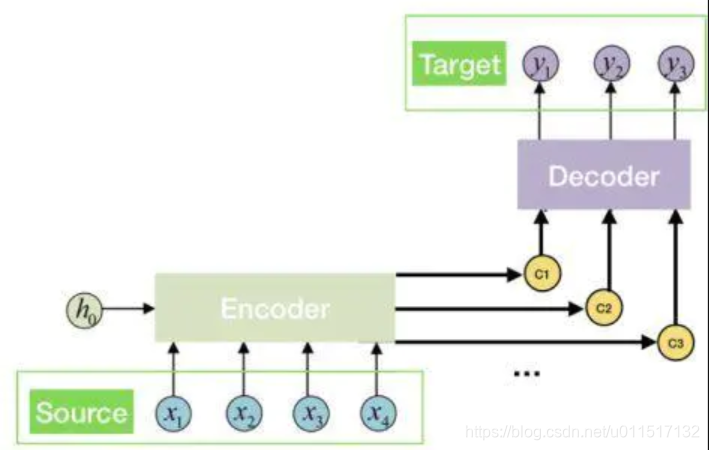
其中:
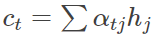
h j h_j hj代表了Encoder中第 j j j个隐藏状态。 a t j a_{tj} atj为 h j h_j hj的权重,具体计算方式如下:

h t h_t ht代表了Encoder中第 t t t个隐藏状态, h s ‾ \overline{h_s} hs代表了Decoder中第 s s s个隐藏状态。 a t ( s ) a_t(s) at(s)具体可以解释为 h t h_t ht与 h s ‾ \overline{h_s} hs的关联性大小。对于函数 s c o r e ( h t , h s ‾ ) score(h_t,\overline{h_s}) score(ht,hs)的计算,常用的有如下几种方式:
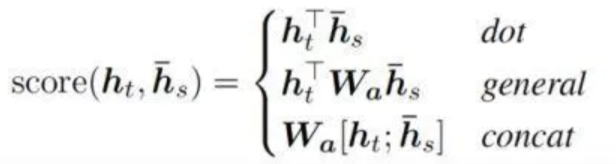
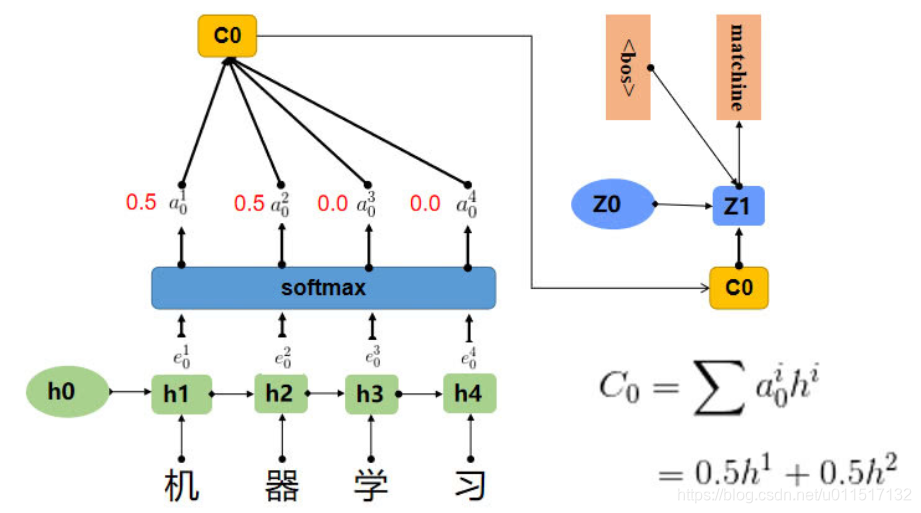
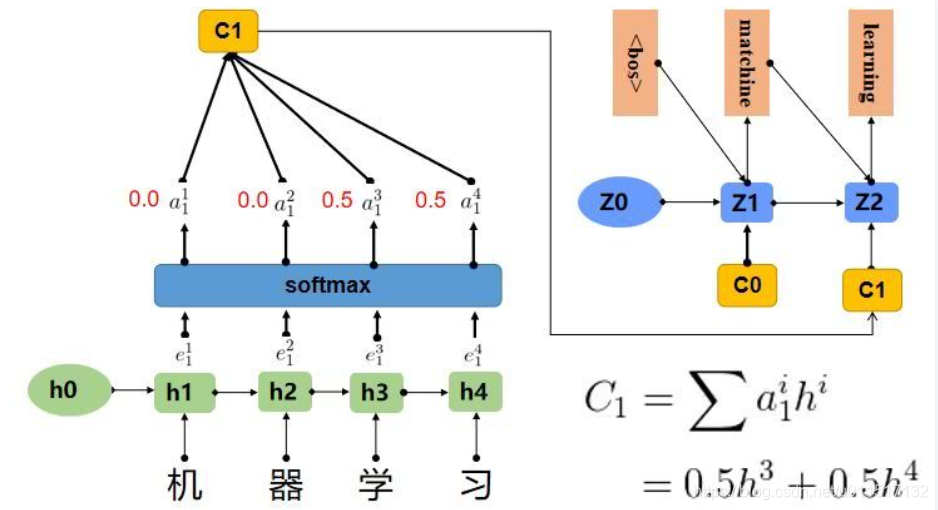
对于上边用seq2seq进行翻译的例子,加入Attention后。模型可表示如下:
参考文献:
Seq2seq模型(一)——attention机制
从Seq2seq到Attention模型到Self Attention
这篇关于Seq2Seq与Attention的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








