regularization专题

人工智能:模型复杂度、模型误差、欠拟合、过拟合/泛化能力、过拟合的检测、过拟合解决方案【更多训练数据、Regularization/正则、Shallow、Dropout、Early Stopping】
人工智能:模型复杂度、模型误差、欠拟合、过拟合/泛化能力、过拟合的检测、过拟合解决方案【更多训练数据、Regularization/正则、Shallow、Dropout、Early Stopping】 一、模型误差与模型复杂度的关系1、梯度下降法2、泛化误差2.1 方差2.2 偏差2.3 噪声2.4 泛化误差的拆分 3、偏差-方差窘境(bias-variance dilemma)4、Bias
Why is L1 regularization supposed to lead to sparsity than L2?
Just because of its geometric shape: Here is some intentionally non-rigorous intuition: suppose you have a linear system Ax=b for which you know there exists a sparse solution x∗ , and that

为什么深度学习中减小泛化误差称为“正则化(Regularization)”
深度学习的一个重要方面是正则化(Regularization),Ian Goodfellow在《Deep Learning 》称正则化(Regularization)就是减小泛化误差。那么,为什么减小泛化误差称为正则化呢? 首先看正则化——Regularization这个单词,Regularization是创造出来的词,在牛津词典和柯林斯词典上都没有,但是有regularize。柯林斯词典对re

论文阅读 Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
Adaptive Consistency Regularization for Semi-Supervised Transfer Learning 论文题目:自适应一致性正则化方法用于半监督迁移学习 作者单位:百度大数据研究院 作者:Abulikemu Abuduweili 代码地址:https://github.com/SHI-Labs/Semi-Supervised-Transfer-Lea
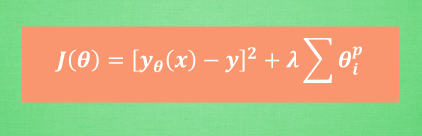
L1 / L2 正规化 (Regularization)
过拟合 我们知道, 过拟合就是所谓的模型对可见的数据过度自信, 非常完美的拟合上了这些数据, 如果具备过拟合的能力, 那么这个方程就可能是一个比较复杂的非线性方程 , 正是因为这里的 x^3 和 x^2 使得这条虚线能够被弯来弯去, 所以整个模型就会特别努力地去学习作用在 x^3 和 x^2 上的 c d 参数. 但是我们期望模型要学到的却是 这条蓝色的曲线. 因为它能更有效地概括数据.而
机器学习入门(5)——正则化(Regularization)
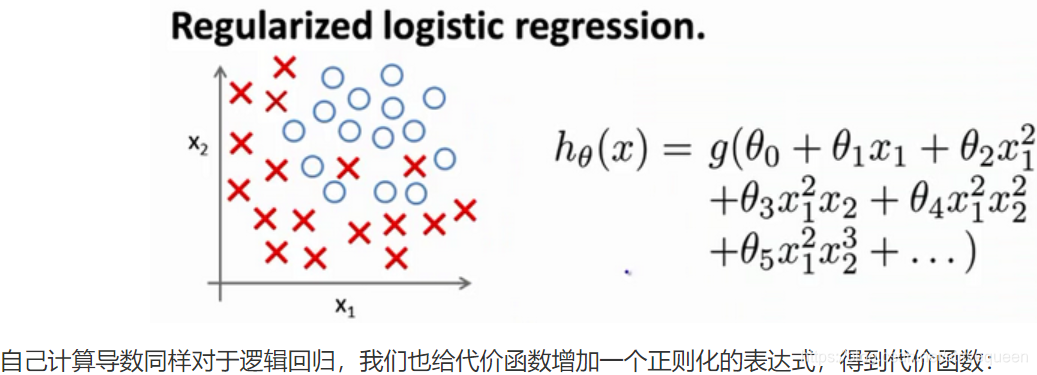
过拟合问题(The Problem of Overfitting)代价函数(Cost Function)正则化线性回归(Regularized Linear Regression)正则化的逻辑回归模型(Regularized Logistic Regression) 过拟合问题(The Problem of Overfitting) 回归问题的例子: 第一个模型是一个线性模

第三讲-------Logistic Regression Regularization
第三讲-------Logistic Regression & Regularization 本讲内容: Logistic Regression ========================= (一)、Classification (二)、Hypothesis Representation (三)、Decision Boundary (四)、Cost Funct

乳腺影像论文1:Symmetry-based regularization in deep breast cancer screening
Symmetry-based regularization in deep breast cancer screening ResultsDatasetExperimentMethod数据增强不变性正则化损失等变体系结构 因为我做的是弱标签的图像分类,所以我只关心全图的信息,Results等只是全图的信息。 Results modelinput sizeACC模型集成输入类

Regularization——正则化
1.过拟合问题 这是使用不同的模型根据房子的大小对于房价的预测 第一张图的模型距离数据点的平均距离仍然比较大,拟合效果并不是特别好,也叫欠拟合(underfitting) 第二张图的模型对于训练集数据的拟合的不错,也能预测数据的趋势,这是我们需要的模型 第三张图的模型拐来拐去,甚至的拟合了训练集的每一个数据点,损失函数接近
![[UIM]论文解读:subword Regularization: Multiple Subword Candidates](https://img-blog.csdnimg.cn/direct/0e2ab2a617e14b84b8ba38c9eab54d0a.png)
[UIM]论文解读:subword Regularization: Multiple Subword Candidates
文章目录 一、完整代码二、论文解读2.1 介绍2.2 NMT2.3 Unigram language model2.4 subword 抽样2.5 效果 三、整体总结 论文:Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates 作者

层规范化(Layer Normalization)和正则化(Regularization)
层规范化(Layer Normalization)和正则化(Regularization)是两个不同的概念,尽管它们都在机器学习和深度学习中非常重要,但它们的目的和应用方式有所不同。 层规范化(Layer Normalization): 层规范化是一种特征缩放技术,用于修改神经网络中层的输入数据。它通过对每个样本的所有特征计算均值和标准差,并使用这些统计数据来规范化每个特征,确保每层的输入分布
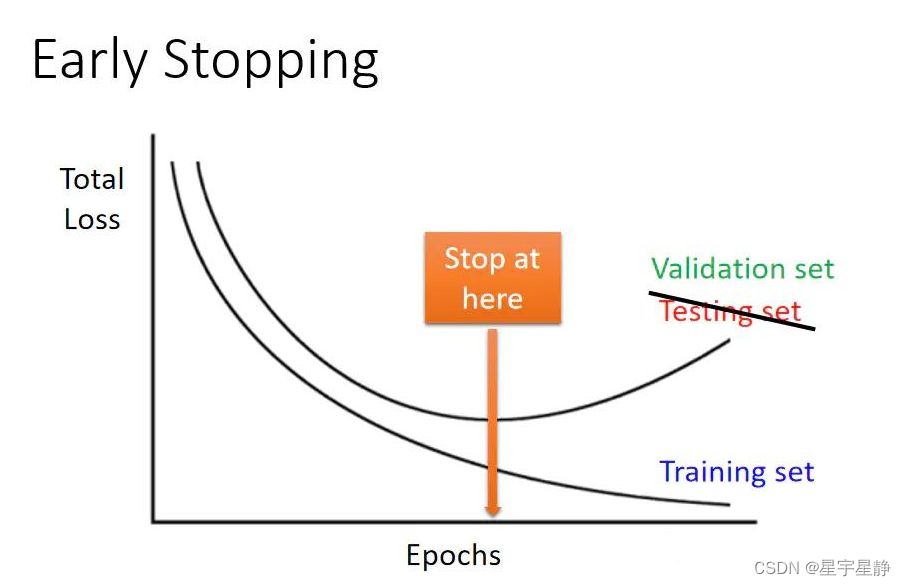
数据扩增(Data Augmentation)、正则化(Regularization)和早停止(Early Stopping)
数据扩增(Data Augmentation)、正则化(Regularization)和早停止(Early Stopping)是深度学习中常用的三种技术,它们有助于提高模型的泛化性能和防止过拟合 数据扩增(Data Augmentation) 定义:数据扩增是通过对训练集中的原始数据进行一系列变换,生成新的训练样本,从而增加训练数据的多样性。这有助于提高模型的鲁棒性,使其能够更好地泛化到未见
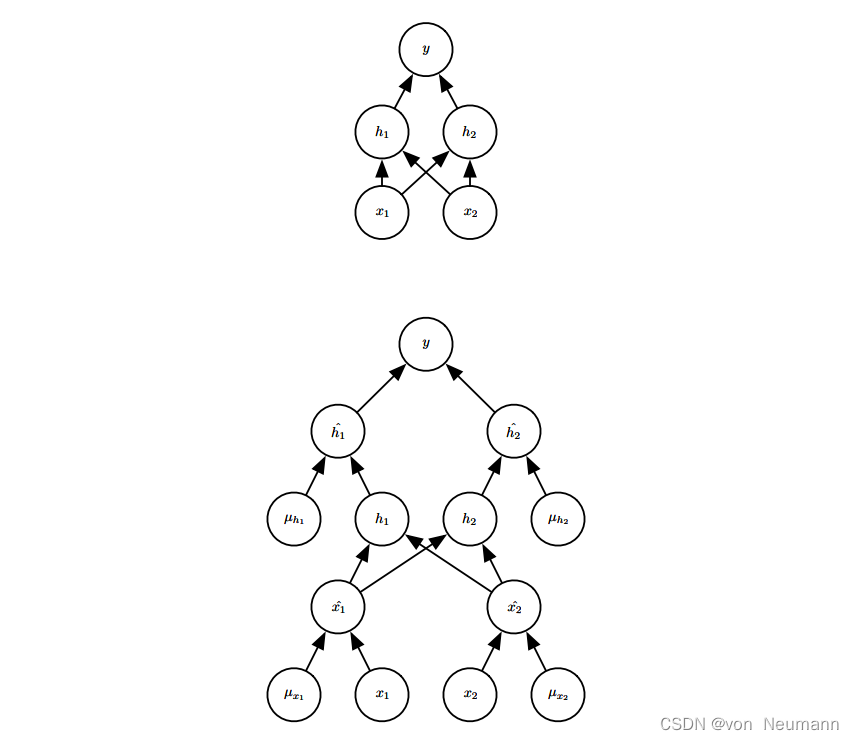
深入理解深度学习——正则化(Regularization):Dropout
分类目录:《深入理解深度学习》总目录 Dropout供了正则化一大类模型的方法,计算方便且功能强大。在第一种近似下,Dropout可以被认为是集成大量深层神经网络的实用Bagging方法。Bagging涉及训练多个模型,并在每个测试样本上评估多个模型。当每个模型都是一个很大的神经网络时,这似乎是不切实际的,因为训练和评估这样的网络需要花费很多运行时间和内存。通常我们只能集成五至十个神经网络,

机器学习笔记——正则化(regularization)
正则化 过拟合 我们在利用数据来进行曲线拟合的时候会出现三种情况,欠拟合(underfitting),合适(just right),过拟合(overfitting)。欠拟合的情况一般是由于变量太少,而过拟合的原因一般是变量太多 下面我们主要考虑过拟合的问题。过拟合的解决方法一种是减少特征的数量,一种就是正则化 代价函数 正则化采用的方法就是修改代价函数,将其加上我们认为不那么

【论文阅读】Virtual Adversarial Training: a Regularization Method for SL and SSL
《Virtual Adversarial Training: a Regularization Method for Supervised and Semi-supervised Learning》 1. 摘要 We propose a new regularization method based on virtual adversarial loss: a new measure of

Train/Dev/Test sets的比例选择;防止过拟合的两种方法:L2 regularization和Dropout;梯度消失和梯度爆炸的概念和危害;梯度初始化;梯度检查
Train/Dev/Test sets的比例选择 一般地,我们将所有的样本数据分成三个部分:Train/Dev/Test sets。Train sets用来训练你的算法模型;Dev sets用来验证不同算法的表现情况,从中选择最好的算法模型;Test sets用来测试最好算法的实际表现,作为该算法的无偏估计。 在样本数量不是很大的情况下,例如100,1000,10000:常设置Train se

《PHONEME-BASED DISTRIBUTION REGULARIZATION FOR SPEECH ENHANCEMENT》论文阅读
ABSTRACT 现存的语音增强方法有时域和频域的方法,但是这些方法啊没有关注过带噪信号里面的语义信息。这篇论文,作者希望借用语义信息能够使得增强的效果更好。因而,提出了一个音素级分布正则化模块PbDr,将帧级语义信息作为条件整合到增强网络里面。频域上不同的音素导致不同的特征分布,通过因素分类模块产生了一个参数对,尺度和偏置。这个参数对不只包括帧级,也包括频域级,能够有效的将特征