本文主要是介绍Train/Dev/Test sets的比例选择;防止过拟合的两种方法:L2 regularization和Dropout;梯度消失和梯度爆炸的概念和危害;梯度初始化;梯度检查,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Train/Dev/Test sets的比例选择
一般地,我们将所有的样本数据分成三个部分:Train/Dev/Test sets。Train sets用来训练你的算法模型;Dev sets用来验证不同算法的表现情况,从中选择最好的算法模型;Test sets用来测试最好算法的实际表现,作为该算法的无偏估计。
在样本数量不是很大的情况下,例如100,1000,10000:常设置Train sets和Test sets的数量比例为70%和30%。如果有Dev sets,则设置比例为60%、20%、20%,分别对应Train/Dev/Test sets。
如果数据量很大的时候:对于100万的样本,Train/Dev/Test sets的比例通常可以设置为98%/1%/1%,或者99%/0.5%/0.5%。样本数据量越大,相应的Dev/Test sets的比例可以设置的越低一些。
最后提一点的是如果没有Test sets也是没有问题的。Test sets的目标主要是进行无偏估计。我们可以通过Train sets训练不同的算法模型,然后分别在Dev sets上进行验证,根据结果选择最好的算法模型。这样也是可以的,不需要再进行无偏估计了。如果只有Train sets和Dev sets,通常也有人把这里的Dev sets称为Test sets,我们要注意加以区别。
Bias和Variance,分别对应着欠拟合和过拟合
Train set error体现了是否出现bias,Dev set error体现了是否出现variance(正确地说,应该是Dev set error与Train set error的相对差值)。
假设Train set error为1%,而Dev set error为11%,即该算法模型对训练样本的识别很好,但是对验证集的识别却不太好。这说明了该模型对训练样本可能存在过拟合,模型泛化能力不强.
假设Train set error为15%,而Dev set error为16%,虽然二者error接近,即该算法模型对训练样本和验证集的识别都不是太好。这说明了该模型对训练样本存在欠拟合。
假设Train set error为15%,而Dev set error为30%,说明了该模型既存在high bias也存在high variance(深度学习中最坏的情况)。
再假设Train set error为0.5%,而Dev set error为1%,即low bias和low variance,是最好的情况。
减少high bias和high variance的方法:
减少high bias的方法通常是增加神经网络的隐藏层个数、神经元个数,训练时间延长,选择其它更复杂的NN模型等。
减少high variance的方法通常是增加训练样本数据,进行正则化Regularization或者Dropout,选择其他更复杂的NN模型等。
防止过拟合的两种方法:L2 regularization和Dropout
L2 regularization:
L1、L2 regularization中的λ就是正则化参数(超参数的一种)。可以设置λ为不同的值,在Dev set中进行验证,选择最佳的λ。顺便提一下,在python中,由于lambda是保留字,所以为了避免冲突,我们使用lambd来表示λ。
L1的在微分求导方面比较复杂。所以,一般L2 regularization更加常用。
在深度学习模型中,L2 regularization的表达式为:

Dropout:
Dropout有不同的实现方法,接下来介绍一种常用的方法:Inverted dropout。假设对于第l层神经元,设定保留神经元比例概率keep_prob=0.8,即该层有20%的神经元停止工作。dl为dropout向量,设置dl为随机vector,其中80%的元素为1,20%的元素为0。在python中可以使用如下语句生成dropout vector:
dl = np.random.rand(al.shape[0],al.shape[1])<keep_prob然后,第l层经过dropout,随机删减20%的神经元,只保留80%的神经元,其输出为:
al = np.multiply(al,dl)最后,还要对al进行scale up处理,即:
al /= keep_prob以上就是Inverted dropout的方法。之所以要对al进行scale up是为了保证在经过dropout后,al作为下一层神经元的输入值尽量保持不变。假设第l层有50个神经元,经过dropout后,有10个神经元停止工作,这样只有40神经元有作用。那么得到的al只相当于原来的80%。scale up后,能够尽可能保持al的期望值相比之前没有大的变化。
其他正则化方法:
我们可以对已有的训练样本进行一些处理来“制造”出更多的样本,称为data augmentation。例如图片识别问题中,可以对已有的图片进行水平翻转、垂直翻转、任意角度旋转、缩放或扩大等等。
还有另外一种防止过拟合的方法:early stopping。一个神经网络模型随着迭代训练次数增加,train set error一般是单调减小的,而dev set error 先减小,之后又增大。也就是说训练次数过多时,模型会对训练样本拟合的越来越好,但是对验证集拟合效果逐渐变差,即发生了过拟合。因此,迭代训练次数不是越多越好,可以通过train set error和dev set error随着迭代次数的变化趋势,选择合适的迭代次数,即early stopping。
与early stopping相比,L2 regularization可以实现“分而治之”的效果:迭代训练足够多,减小J,而且也能有效防止过拟合。而L2 regularization的缺点之一是最优的正则化参数λ的选择比较复杂。对这一点来说,early stopping比较简单。总的来说,L2 regularization更加常用一些。
标准化输入:

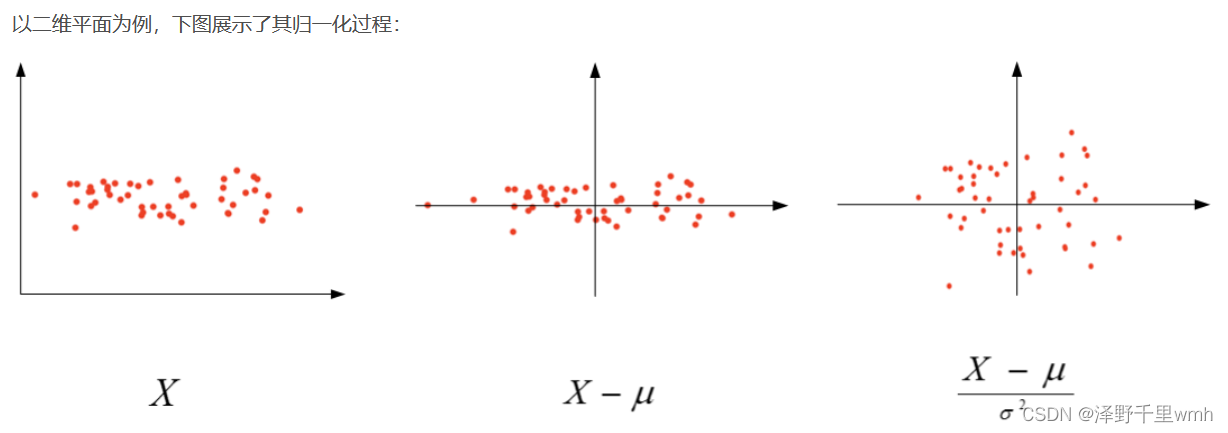
然而,如果进行了标准化操作,x1与x2分布均匀,w1和w2数值差别不大,得到的cost function与w和b的关系是类似圆形碗。对其进行梯度下降算法时,α可以选择相对大一些,且J一般不会发生振荡,保证了J是单调下降的。如下右图所示。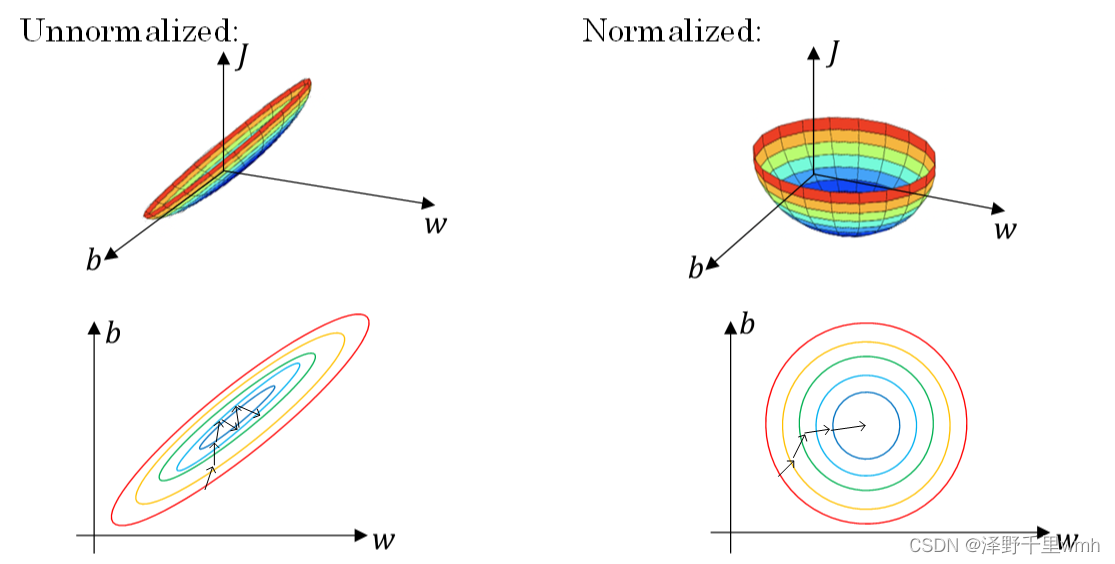
梯度消失和梯度爆炸的概念和危害
梯度消失和梯度爆炸。意思是当训练一个 层数非常多的神经网络时,计算得到的梯度可能非常小或非常大,甚至是指数级别的减小或增大。这样会让训练过程变得非常困难。
梯度初始化
这里忽略了常数项b。为了让z不会过大或者过小,思路是让w与n有关,且n越大,w应该越小才好。这样能够保证z不会过大。一种方法是在初始化w时,令其方差为1/n。相应的python伪代码为:

梯度检查

在进行梯度检查的过程中有几点需要注意的地方:
不要在整个训练过程中都进行梯度检查,仅仅作为debug使用。
如果梯度检查出现错误,找到对应出错的梯度,检查其推导是否出现错误。
注意不要忽略正则化项,计算近似梯度的时候要包括进去。
梯度检查时关闭dropout,检查完毕后再打开dropout。
随机初始化时运行梯度检查,经过一些训练后再进行梯度检查(不常用)。
这篇关于Train/Dev/Test sets的比例选择;防止过拟合的两种方法:L2 regularization和Dropout;梯度消失和梯度爆炸的概念和危害;梯度初始化;梯度检查的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




