l2专题

【机器学习 sklearn】模型正则化L1-Lasso,L2-Ridge
#coding:utf-8from __future__ import divisionimport sysreload(sys)sys.setdefaultencoding('utf-8')import timestart_time = time.time()import pandas as pd# 输入训练样本的特征以及目标值,分别存储在变量X_train与y_train之中。

【Python机器学习】核心数、进程、线程、超线程、L1、L2、L3级缓存
如何知道自己电脑的CPU是几核的,打开任务管理器(同时按下:Esc键、SHIFT键、CTRL键) 然后,点击任务管理器左上角的性能选项,观察右下角中的内核:后面的数字,就是你CPU的核心数,下图中我的是16个核心的。 需要注意的是,下面的逻辑处理器:32 表示支持 32 线程(即超线程技术) 图中的进程:和线程:后面的数字代表什么 在你上传的图片中,“进程:180” 和 “线程:3251”

ASTER L2 表面反射率 SWIR 和 ASTER L2 表面反射率 VNIR V003
ASTER L2 Surface Reflectance SWIR and ASTER L2 Surface Reflectance VNIR V003 ASTER L2 表面反射率 SWIR 和 ASTER L2 表面反射率 VNIR V003 简介 ASTER 表面反射率 VNIR 和 SWIR (AST_07) 数据产品 (https://lpdaac.usgs.gov/documen

NASA:ASTER L2 表面辐射率(E(辐射率)和 T(地表温度)) V003数据集
ASTER L2 Surface Emissivity V003 ASTER L2 表面辐射率 V003 简介 ASTER L2 地表发射率是一种按需生成的产品((https://lpdaac.usgs.gov/documents/996/ASTER_Earthdata_Search_Order_Instructions.pdf)),利用 8 至 12 µm 光谱范围内的五个热红外(TIR)

【Arm Cortex-X925】 -【第九章】-L2 内存系统
9. L2 内存系统 Cortex®-X925 核心的 L2 内存系统通过 CPU 桥接器将核心与 DynamIQ™ Shared Unit-120 连接。它包括私有的 L2 缓存。 L2 缓存是统一的,并且对集群中的每个 Cortex®-X925 核心都是私有的。 以下表格显示了 L2 内存系统的特点。 9.1 L2 缓存 集成的 L2 缓存处理来自指令和数据侧的指令和数据请求,以及
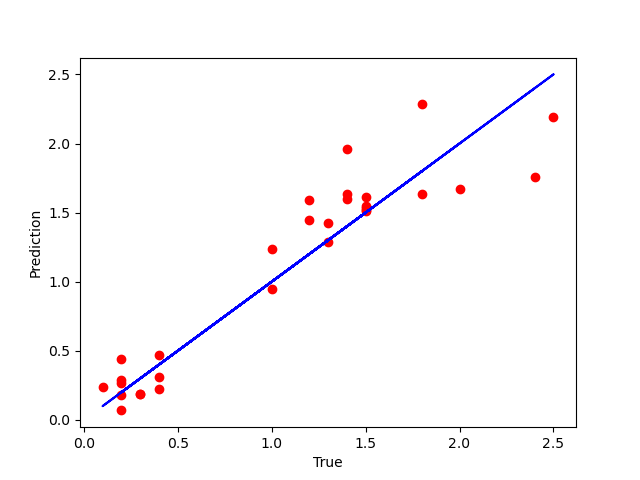
第L2周:机器学习-线性回归
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目标: 学习简单线性回归模型和多元线性回归模型通过代码实现:通过鸢尾花花瓣长度预测花瓣宽度 具体实现: (一)环境: 语言环境:Python 3.10 编 译 器: PyCharm 框 架:scikit-learn (二)具体步骤: 造个数据集,内容格式如下: 导入库 import pandas as p

【书生大模型实战】L2-茴香豆:企业级知识问答工具实践闯关任务
一、关卡任务 基础任务(完成此任务即完成闯关) 在 InternStudio 中利用 Internlm2-7b 搭建标准版茴香豆知识助手,并使用 Gradio 界面完成 2 轮问答(问题不可与教程重复,作业截图需包括 gradio 界面问题和茴香豆回答)。知识库可根据根据自己工作、学习或感兴趣的内容调整,如金融、医疗、法律、音乐、动漫等(优秀学员必做)。 如果问答效果不理想,尝试调整正反例

机器学习(5)--正则化之L1和L2正则化
文章目录 正则化一、正则化的基本原理二、L1正则化(Lasso)三、L2正则化(Ridge)四、L1与L2正则化的比较 总结 正则化 正则化是一种在机器学习和深度学习中常用的技术手段,旨在提高模型的泛化能力,减少过拟合现象。它通过向模型的损失函数中添加一个正则化项来实现,这个正则化项是对模型复杂度的惩罚。L1正则化和L2正则化是两种最常用的正则化方法,它们各有特点和适用场景。
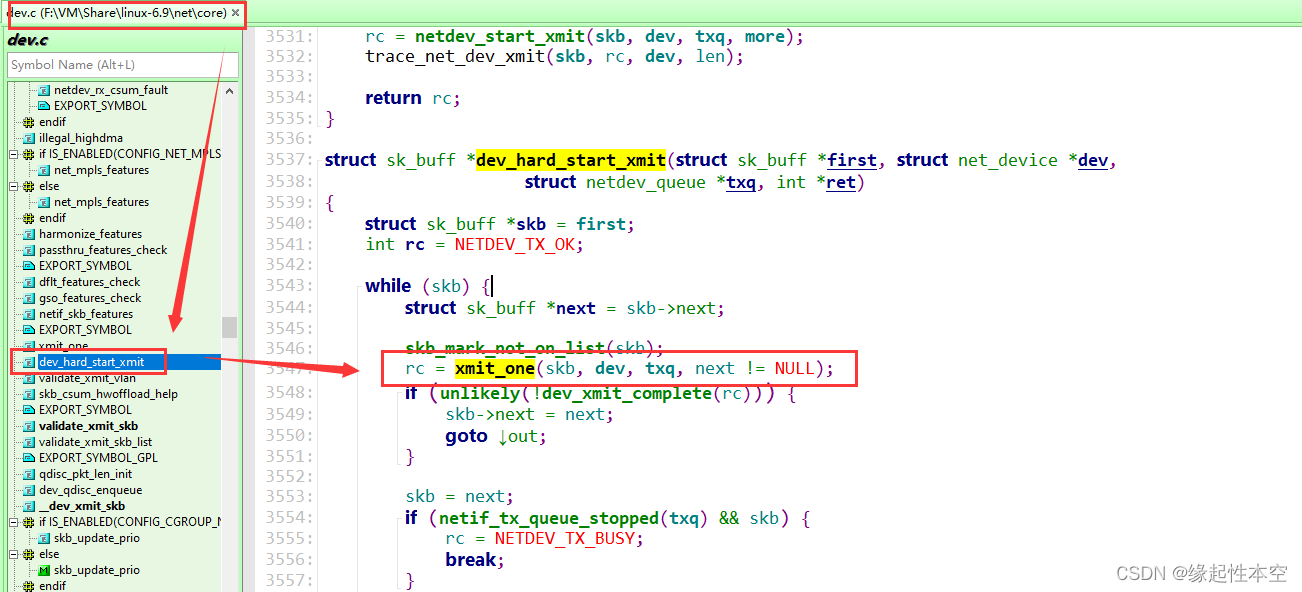
【linux】内核源码TCP->IP->L2层函数调用继续摸索中
日志打印的时候,把行数也打印了: 登录 - Gitee.comhttps://gitee.com/r77683962/linux-6.9.0/commit/b847489a9910f68b9581fd8788807c697c82cdbd 上回基于应用层wget操作找到TCP调用的一些接口,并且已经到IP层的一些接口,当前基于TCP的这根藤一直往下摸瓜,当前测试到L2层,但是不知道是不是正确

Walrus:去中心化存储和DA协议,可以基于Sui构建L2和大型存储
Walrus是为区块链应用和自主代理提供的创新去中心化存储网络。Walrus存储系统今天以开发者预览版的形式发布,面向Sui开发者征求反馈意见,并预计很快会向其他Web3社区广泛推广。 通过采用纠删编码创新技术,Walrus能够快速且稳健地将非结构化数据块编码成较小的分片,这些分片会分布存储在一个存储节点网络中。即使多达三分之二的分片丢失,也可以使用部分分片快速重构原始数据块。这在保持复制因子仅

l0-Norm, l1-Norm, l2-Norm, … , l-infinity Norm
I’m working on things related to norm a lot lately and it is time to talk about it. In this post we are going to discuss about a whole family of norm. What is a norm? Mathematically a norm is a tota
Why is L1 regularization supposed to lead to sparsity than L2?
Just because of its geometric shape: Here is some intentionally non-rigorous intuition: suppose you have a linear system Ax=b for which you know there exists a sparse solution x∗ , and that

StarkNet架构之L1-L2消息传递机制
文章目录 StarkNet架构之L1-L2消息传递机制L2 → L1消息L2 → L1消息结构L2 → L1消息哈希L1 → L2消息L1 → L2消息取消L1 → L2报文费用L1 → L2哈希额外资源 StarkNet架构之L1-L2消息传递机制 原文地址:https://docs.starknet.io/architecture-and-concepts/network-
OVN L2、L3层功能介绍
参考文献: https://tonydeng.github.io/sdn-handbook/ovs/ovn-internal.html 一、OVN L2 功能包括: L2 switchL2 ACLSupports software-based L2 gatewaysSupports TOR (Top of Rack) based L2 gateways that implement the h

L2-002 链表去重(C++)
给定一个带整数键值的链表 L,你需要把其中绝对值重复的键值结点删掉。即对每个键值 K,只有第一个绝对值等于 K 的结点被保留。同时,所有被删除的结点须被保存在另一个链表上。例如给定 L 为 21→-15→-15→-7→15,你需要输出去重后的链表 21→-15→-7,还有被删除的链表 -15→15。 输入格式: 输入在第一行给出 L 的第一个结点的地址和一个正整数 N(≤105,为结点总数)。
颜色恒常性L2规范化思考
颜色恒常性L2规范化思考 背景是否正确思考原因新的思考 背景 最近在做硕士毕业论文,关于颜色恒常性。在对源码进行解读的时候发现,对光源ground truth的规范化中,使用了L2方法,对应的,模型的输出光源也使用L2归一化,然后再计算角度误差。 由于之前的研究多为颜色相关,所以直觉考虑有些奇怪,因为CIE中定义色度是有色光加色法决定的,即L1,因此,如果颜色恒常性算法的最终目

sk-learn实现L2岭回归,对线性回归正则化
岭回归算法: from sklearn.datasets import load_bostonfrom sklearn.externals import joblibfrom sklearn.linear_model import Ridge, RidgeCVfrom sklearn.metrics import mean_squared_errorfrom sklearn.m
L2-039 清点代码库(STL的map,pair的排序)
#include <iostream>#include <cstring>#include <algorithm>#include<vector>#include<map>#define x first#define y secondusing namespace std;const int N = 100010;int n,m;map<vector<int>,int>cnt;//
2024-05-24 问AI: 在深度学习中,什么是L1 正则化和L2 正则化?
文心一言 在深度学习和机器学习中,正则化是一种用于防止模型过拟合的技术。它通过向损失函数添加一个惩罚项来实现,这个惩罚项与模型的复杂度有关。正则化项可以看作是对模型参数的约束,使得模型在训练时不仅关注于最小化训练误差,还要尽量使模型参数的值较小,从而降低模型的复杂度,提高模型的泛化能力。 L1 正则化和 L2 正则化是两种常见的正则化方法,它们之间的主要区别在于惩罚项的形式和效果。 L1 正

Covalent Network(CQT)长期数据设施,支持基于 “blob” 方案、总锁仓价值达 54 亿美元的头部EVM L2
Covalent Network(CQT)是领先的历史数据可用性网络,通过其在 Web3 中超过 225 个区块链上的结构化数据基础设施,为数千名客户和开发人员提供支持。Covalent Network(CQT)正在与未来以太坊的进步需求相匹配,尤其是考虑到以太坊改进提案 4844(EIP-4844)的情况下。凭借强大的基础设施,用户和开发人员可以从不断增长的数据库中获取大量可验证的结构化数据

KNN cifar-10 L1 L2距离 交叉验证
K-NN k-Nearest Neighbor分类器 之前的近邻算法(NN)是仅仅选择一个最近的图像标签,K-NN是选出K个差值最小的图像标签,然后看那个标签的数量多就选用那个标签作为预测值,这样就提高了泛化能力。 交叉验证。 有时候,训练集数量较小(因此验证集的数量更小)。如果是交叉验证集,将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1

机器学习-L1正则/L2正则
机器学习-L1正则/L2正则 目录 1.L1正则 2.L2正则 3.结合 1.L1正则 L1正则是一种用来约束模型参数的技术,常用于机器学习和统计建模中,特别是在处理特征选择问题时非常有用。 想象一下,你在装备行囊准备去旅行,但你的行囊有一个限制:只能带一定数量的东西。现在,你得在限定数量内选择最重要的物品来装备,这样才能在旅途中轻松愉快。 L1正则就像是给你的行囊

linux网络协议栈(四)链路层 (6)L2隧道(eoip)
4.7、L2隧道(eoip): 隧道,就是走捷径,使转发速度更快,L2隧道就是说高层报文在链路层即被转发了,而无需走高层协议栈再转发,比如这里要说的eoip(Ethernet over ip),就是说IP报文在以太网就被转发出去了。 对于eoip,linux内核源码没有其实现,是raisecom根据开源代码实现的,在2.10代码树的rcios/eoip/目录下的eoip.c文件,下图是eoip
C 看看L1是不是L2的子链
//结构体typedef struct Node {ElementType data;struct Node * next;} LNode, * LinkNode;//看看L1是不是L2的一个子串Status isChildStr(LinkNode L1, LinkNode L2){//L2出个前驱和当前,L1出个当前LinkNode nodel1 = L1->next;LinkNode p

Themis新篇章:老牌衍生品协议登陆Blast L2,探索全新经济模型
本文将深入分析 Themis 的最新经济模型,探讨其核心概念和机制、优势与创新之处、风险与挑战。 一、引言 随着区块链技术的不断发展,DeFi 衍生品项目逐渐成为市场的焦点。而用户体验的革新,进一步的金融创新,去中心化治理方案的优化,新的流动性挖矿和激励机制的实施,使去中心化衍生品交易进入快速发展期。行业的快速发展离不开合适的契机,太早或者太晚都是一种错误!基础
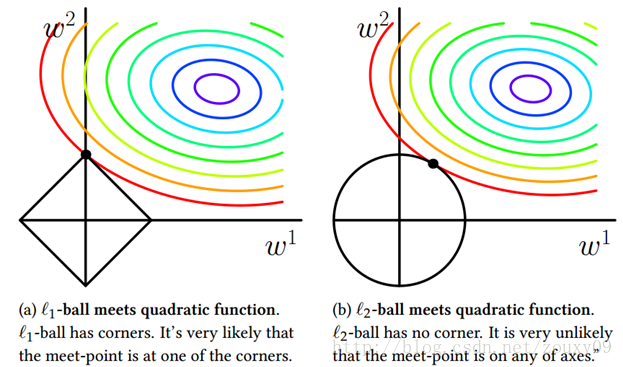
LASSO与redge回归区别 L1 L2范数之间的区别
转载自:http://blog.csdn.net/sinat_26917383/article/details/52092040 一、正则化背景 监督机器学习问题无非就是“minimizeyour error while regularizing your parameters”,也就是在规则化参数的同时最小化误差。最小化误差是为了让我们的模型拟合我们的训练数据, 而规