本文主要是介绍机器学习-L1正则/L2正则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
机器学习-L1正则/L2正则
目录
1.L1正则
2.L2正则
3.结合
1.L1正则
L1正则是一种用来约束模型参数的技术,常用于机器学习和统计建模中,特别是在处理特征选择问题时非常有用。
想象一下,你在装备行囊准备去旅行,但你的行囊有一个限制:只能带一定数量的东西。现在,你得在限定数量内选择最重要的物品来装备,这样才能在旅途中轻松愉快。
L1正则就像是给你的行囊设定了一个最大重量限制。它强制模型尽可能地少用特征,让模型变得更简单,更容易解释。换句话说,它促使模型只挑选出最重要的特征来做决策,而把不那么重要的特征抛弃掉,就像你只选择了最重要的东西来装备行囊一样。
这种约束对于避免过拟合特别有效,因为它阻止了模型对训练数据中噪声和不必要的特征过度拟合。而且,使用L1正则的模型通常更具有稀疏性,也就是说,大部分参数都会被设为零,只有少数参数对模型的预测起到关键作用,就像你行囊里只有几样重要的物品一样。这让模型更加简洁、高效,也更容易理解和解释。
总的来说,L1正则就像是给模型的行囊设定了一个明确的限制,让模型更加精简、高效,帮助我们更好地理解数据并做出准确的预测。
岭回归取出的向量不容易为零

2.L2正则
L2正则跟L1正则有些类似,但又有自己独特的特点。让我用一个简单的比喻来解释一下。
想象一下,你是一位艺术家,正在创作一幅画作。但你发现自己的画笔太自由了,导致画面上出现了太多的杂乱笔触,使得整幅画显得有些混乱。
L2正则就像是给你的画笔加上一根轻微的铁链,稍微限制了你的画笔运动。这样一来,你仍然可以自由地创作,但是笔触会更加平滑,更加统一,画面也会更加清晰。
在机器学习中,L2正则也是一种约束模型参数的技术,它的作用是使模型的参数保持较小的数值,避免出现过于复杂的模型,从而减少过拟合的风险。它通过向模型的损失函数添加一个惩罚项,使得模型在训练过程中更倾向于学习较小的参数值。
相比于L1正则,L2正则更注重于平滑模型参数的值,而不是将参数压缩为零。这样一来,L2正则对于处理高维度数据和多重共线性(即特征之间存在相关性)的情况更为有效。
总的来说,L2正则就像是给模型的画笔加上了一根铁链,使得模型的参数更加平滑,避免了过度复杂和杂乱,让我们的模型更具有泛化能力,更能应对各种数据情况。
LASSO回归取出的向量容易取零

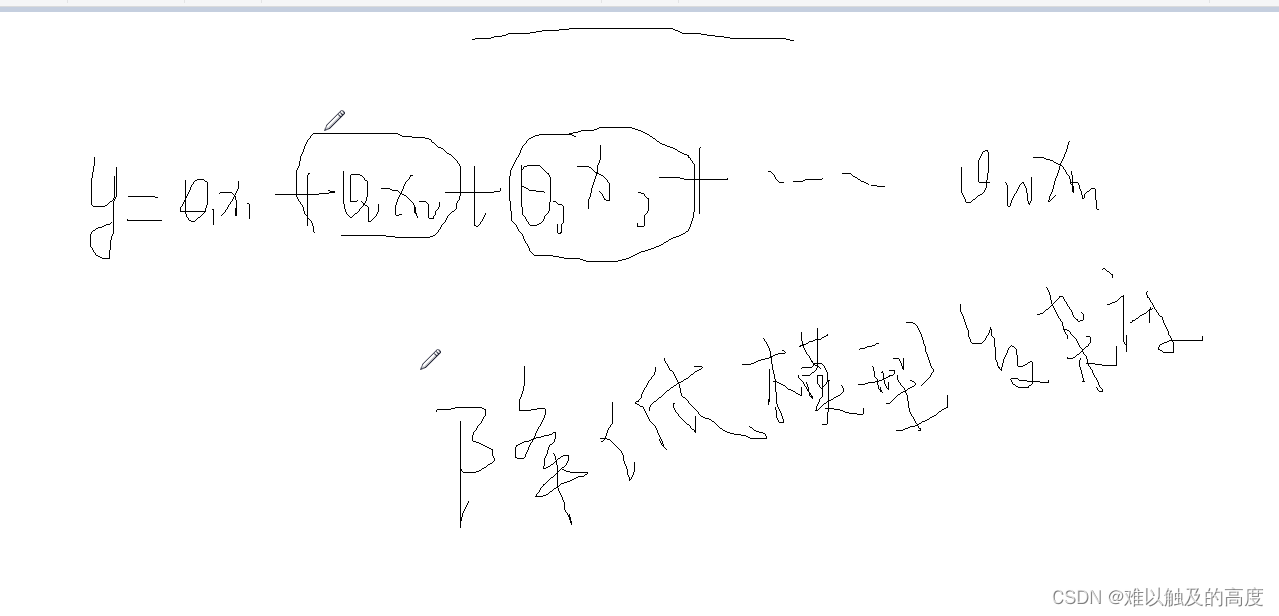
3.结合
那么 我们如何结合一下L1正则和L2正则的优点呢

这篇关于机器学习-L1正则/L2正则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








