quantization专题

网络压缩之参数量化(parameter quantization)
参数量化(parameter quantization)。参数量化是说能否只 用比较少的空间来储存一个参数。举个例子,现在存一个参数的时候可能是用64位或32位。 可能不需要这么高的精度,用16或8位就够了。所以参数量化最简单的做法就是,本来如果 存网络的时候,举例来说,我们是16个位存一个数值,现在改成8个位存一个数值。储存空 间,网络的大小直接就变成原来的一半,而且性能不会掉很


论文阅读笔记:Instance-Aware Dynamic Neural Network Quantization
论文阅读笔记:Instance-Aware Dynamic Neural Network Quantization 1 背景2 创新点3 方法4 模块4.1 网络量化4.2 动态量化4.3 用于动态量化的位控制器4.4 优化 5 效果 论文:https://openaccess.thecvf.com/content/CVPR2022/papers/Liu_Instance-Awar

【模型量化】——LSQ-Net: Learned Step Size Quantization论文
亮点:ICLR2020 论文:https://arxiv.org/pdf/1902.08153.pdf code:非官方实现 摘要 在推理时以低精度操作运行的深层网络具有比高精度替代方案更强大的功耗和空间优势,但是需要克服随着精度降低而保持高精度的挑战。在这里,我们提出了一种用于训练此类网络的方法,即“学习步长量化”,该方法可以在使用模型时在ImageNet数据集上实现迄今为止最高的准确性
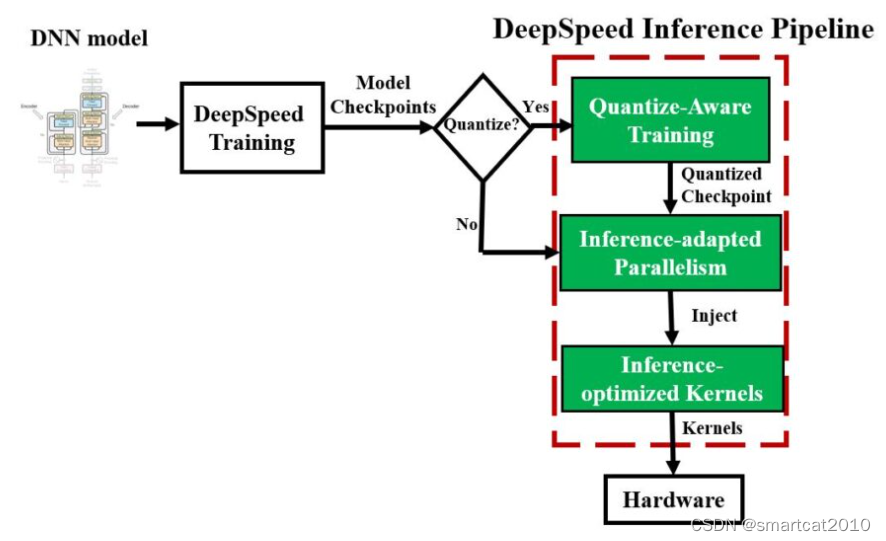
DeepSpeed Mixture-of-Quantization (MoQ)
属于QAT (Quantization-Aware Training)的一种,训练阶段用量化。 特点是: 1. 从16-bit INT开始训练,逐渐减1bit,训练一些steps就减1bit,直至减至8bit INT; 2. (可选,不一定非用)多久减1bit,这个策略,使用模型参数的二阶特征来决定,每层独立的(同一时刻,每层的特征值们大小不一致,也就造成bit减少速度不一致,造成bit数目
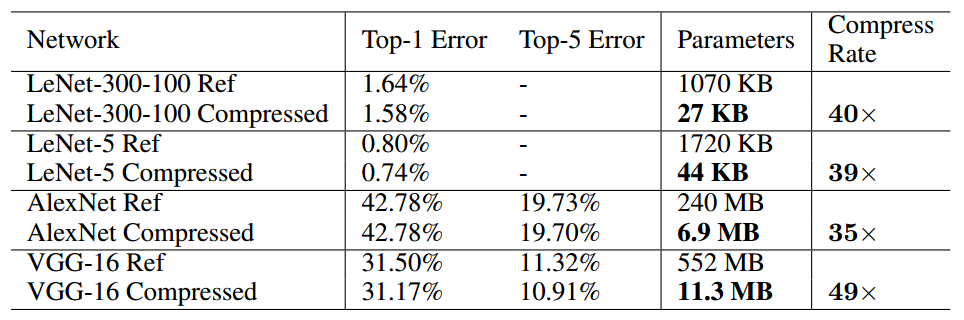
Compression Deep Neural Networks With Pruning, Trained Quantization And Huffman Coding
本次介绍的方法为“深度压缩”,文章来自2016ICLR最佳论文 《Deep Compression: Compression Deep Neural Networks With Pruning, Trained Quantization And Huffman Coding 转自:http://blog.csdn.net/shuzfan/article/details/51383809 (内含多

HuggingFace团队亲授大模型量化基础: Quantization Fundamentals with Hugging Face
Quantization Fundamentals with Hugging Face 本文是学习https://www.deeplearning.ai/short-courses/quantization-fundamentals-with-hugging-face/ 这门课的学习笔记。 What you’ll learn in this course Generative AI mo

TfLite: TensorFlow模型格式和Post-training quantization
TensorFlow的模型格式 TensorFlow的模型格式有很多种,针对不同场景可以使用不同的格式,只要符合规范的模型都可以轻易部署到在线服务或移动设备上,这里简单列举一下。 Checkpoint: 用于保存模型的权重,主要用于模型训练过程中参数的备份和模型训练热启动。GraphDef:用于保存模型的Graph,不包含模型权重,加上checkpoint后就有模型上线的全部信息。SavedM
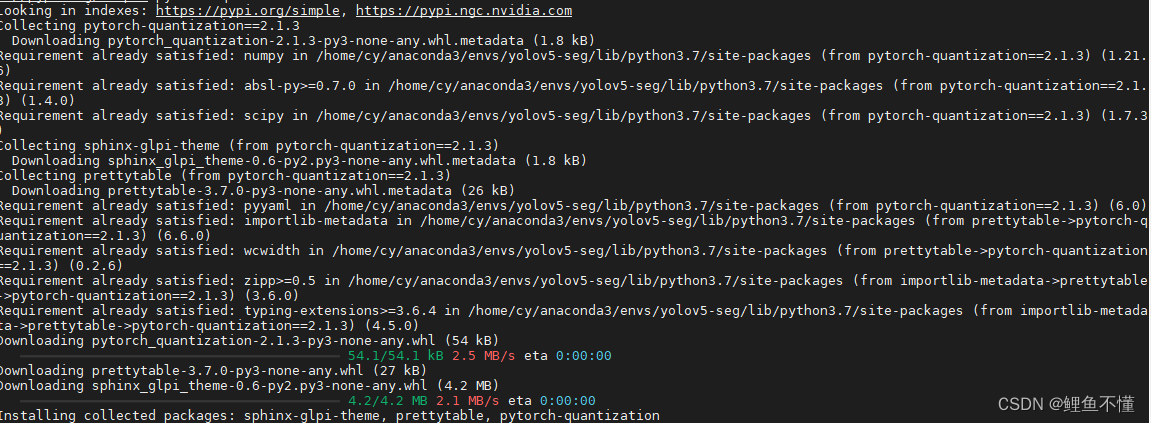
pip install pytorch-quantization error
一 报错信息 最近安装pytorch-quantization报错,安装失败报错信息如下: Looking in indexes: https://pypi.org/simple, https://pypi.ngc.nvidia.comCollecting pytorch-quantizationDownloading pytorch-quantization-2.2.1.tar.gz (6
PQ(product quantization) 算法---(二)
PQ(productquantization)算法:乘积量化,这里的乘积为笛卡尔积;从字面理解包括了两个过程特征的分组量化过程和类别的笛卡尔积过程。它属于ANN(approximatenearest neighbor)算法。与它相关的算法有E2LSH(EuclideanLocality-SensitiveHashing), KD-trees,K-means。 假设有一个数据集: 由n个D维向量组
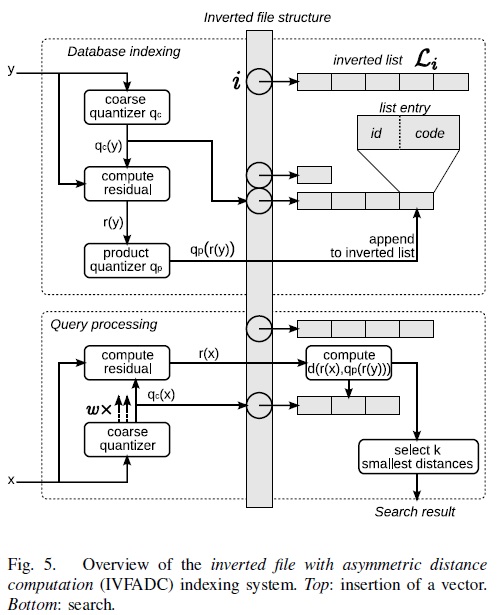
PQ(product quantization) 算法---(一)
转自:http://vividfree.github.io/ 1. 引言 Product quantization,国内有人直译为乘积量化,这里的乘积是指笛卡尔积(Cartesian product),意思是指把原来的向量空间分解为若干个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化(quantization)。这样每个向量就能由多个低维空间的量化code组合表示。为简洁描

TensorRT模型优化模型部署(七)--Quantization量化(PTQ and QAT)(二)
系列文章目录 第一章 TensorRT优化部署(一)–TensorRT和ONNX基础 第二章 TensorRT优化部署(二)–剖析ONNX架构 第三章 TensorRT优化部署(三)–ONNX注册算子 第四章 TensorRT模型优化部署(四)–Roofline model 第五章 TensorRT模型优化部署(五)–模型优化部署重点注意 第六章 TensorRT模型优化部署(六)–Quanti
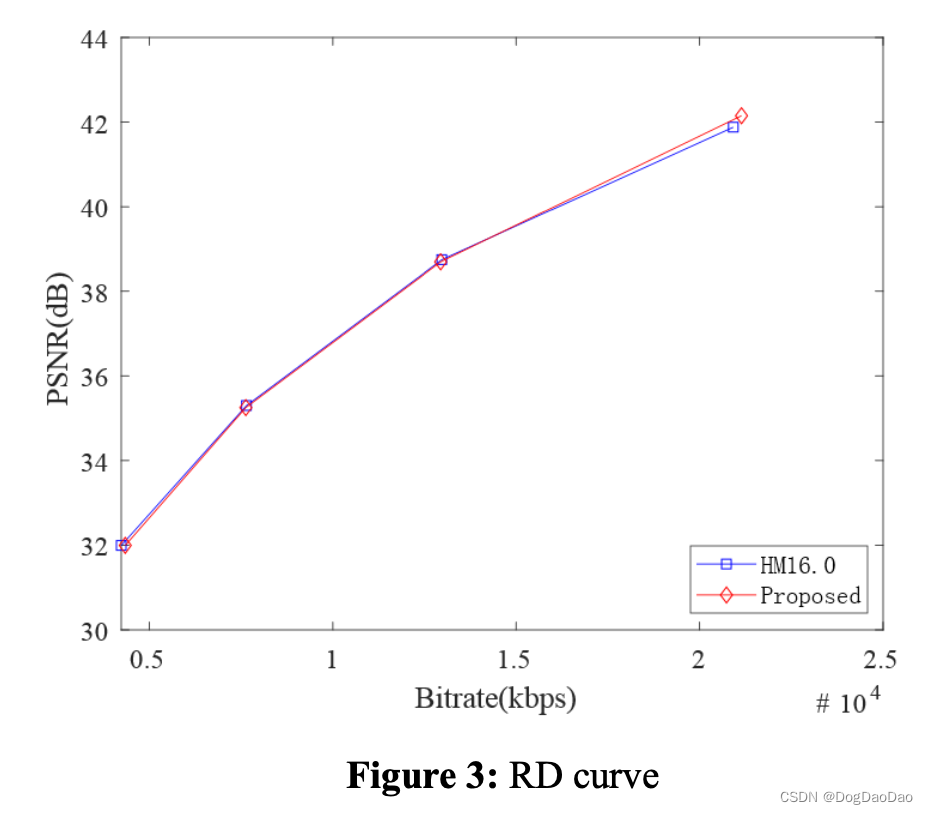
【论文解读】CNN-Based Fast HEVC Quantization Parameter Mode Decision
时间:2019 年 级别:SCI 机构:南京信息工程大学 摘要 随着多媒体呈现技术、图像采集技术和互联网行业的发展,远程通信的方式已经从以前的书信、音频转变为现在的音频/视频。和 视频在工作、学习和娱乐中的比例不断提高,高清视频越来越受到人们的重视。由于网络环境和存储容量的限制,原始视频必须进行编码才能高效地传输和存储。高效视频编码(HEVC)需要大量的编码时间 递归遍历自适应量化过程中编码单

【读点论文】A Survey of Quantization Methods for Efficient Neural Network Inference
A Survey of Quantization Methods for Efficient Neural Network Inference Abstract 一旦抽象的数学计算适应了数字计算机的计算,在这些计算中如何有效地表示、处理和传递数值的问题就出现了。与数字表示问题密切相关的是量化问题:一组连续的实值数应该以何种方式分布在一组固定的离散数字上,以最小化所需的位数,并最大化随之而来的计
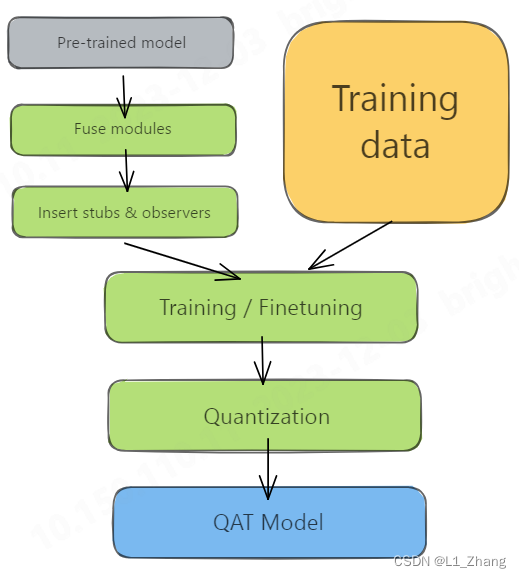
pytorch 模型量化quantization
pytorch 模型量化quantization 1.workflow1.1 PTQ1.2 QAT 2. demo2.1 构建resnet101_quantization模型2.2 PTQ2.3 QAT 参考文献 pytorch框架提供了三种量化方法,包括: Dynamic QuantizationPost-Training Static Quantization(PTQ)Qua
pytorch 模型量化quantization
pytorch 模型量化quantization 1.workflow1.1 PTQ1.2 QAT 2. demo2.1 构建resnet101_quantization模型2.2 PTQ2.3 QAT 参考文献 pytorch框架提供了三种量化方法,包括: Dynamic QuantizationPost-Training Static Quantization(PTQ)Qua
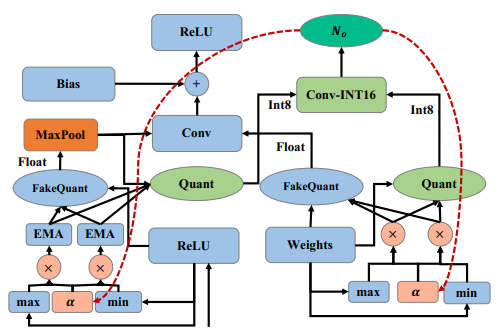
Overflow Aware Quantization
Overflow Aware Quantization Framework N o _o o是 amount of arithmetic overflow 辅助信息 作者未提供代码

faiss(2):理解product quantization算法
近几年,深度学习技术被广泛用于图像识别、语音识别、自然语言处理等领域,能够把每个实体(图像、语音、文本)转换为对应的embedding向量。如这里千人千面智能淘宝店铺背后的算法研究登陆人工智能顶级会议AAAI 2017。而对于推荐、搜索或者广告投放问题,都可以描述为从大规模候选中给用户提供有限的展现结果。那么,这里就会涉及到向量检索的问题。 向量检索最简单的想法是暴力穷举法,如果全部实体的个数是
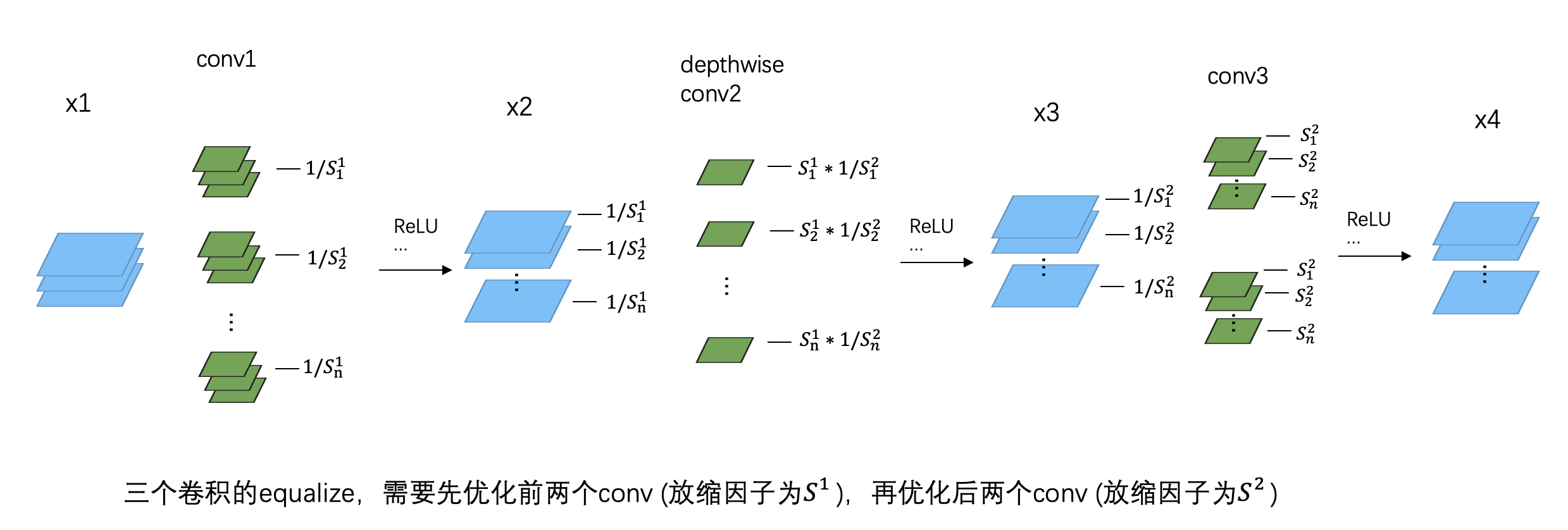
Data-Free Quantization,我踩的那些坑
(本文首发于公众号,没事来逛逛) 上一篇文章介绍了高通 Data-Free Quantization 的基本思想,但我在代码实现的时候发现有个问题没有解决,因此这篇文章对前文打个补丁 (果然没有落实到代码层面都不能说自己看懂了论文)。 Depthwise Conv如何equalize 在前面的文章中,我给出了 weight equalize 的简单实现: def equalize(weigh
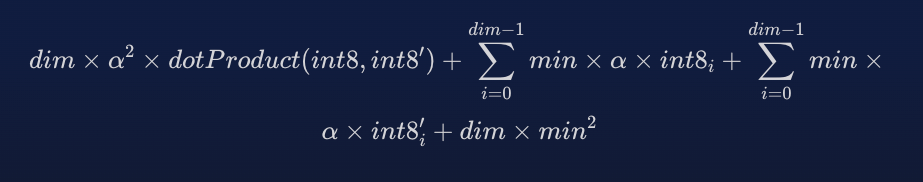
Elasticsearch:标量量化 101 - scalar quantization 101
作者:BENJAMIN TRENT 什么是标量量化以及它是如何工作的? 大多数嵌入模型输出 float32 向量值。 虽然这提供了最高的保真度,但考虑到向量中实际重要的信息,这是浪费的。 在给定的数据集中,嵌入永远不需要每个单独维度的所有 20 亿个选项。 对于高维向量(例如 386 维及更高维)尤其如此。 量化允许以有损方式对向量进行编码,从而稍微降低保真度并节省大量空间。 桶里的

TensorRT量化实战课YOLOv7量化:pytorch_quantization介绍
目录 前言1. 课程介绍2. pytorch_quantization2.1 initialize函数2.2 tensor_quant模块2.3 TensorQuantizer类2.4 QuantDescriptor类2.5 calib模块 总结 前言 手写 AI 推出的全新 TensorRT 模型量化实战课程,链接。记录下个人学习笔记,仅供自己参考。 该实战课程主要基于手写

Additive Powers-of-Two (APoT) Quantization:硬件友好的非均匀量化方法
Additive Powers-of-Two Quantization:硬件友好的非均匀量化方法 摘要方法Additive Powers-of-Two量化 (APoT)量化表示均匀量化表示Powers-of-Two (PoT) 量化表示Additive Powers-of-Two(APoT)量化表示 参数化Clipping函数 (RCF)权重归一化APoT量化伪代码 实验结果CIFAR-10
如何解决报错 ModuleNotFoundError: No module named ‘torch.ao.quantization‘
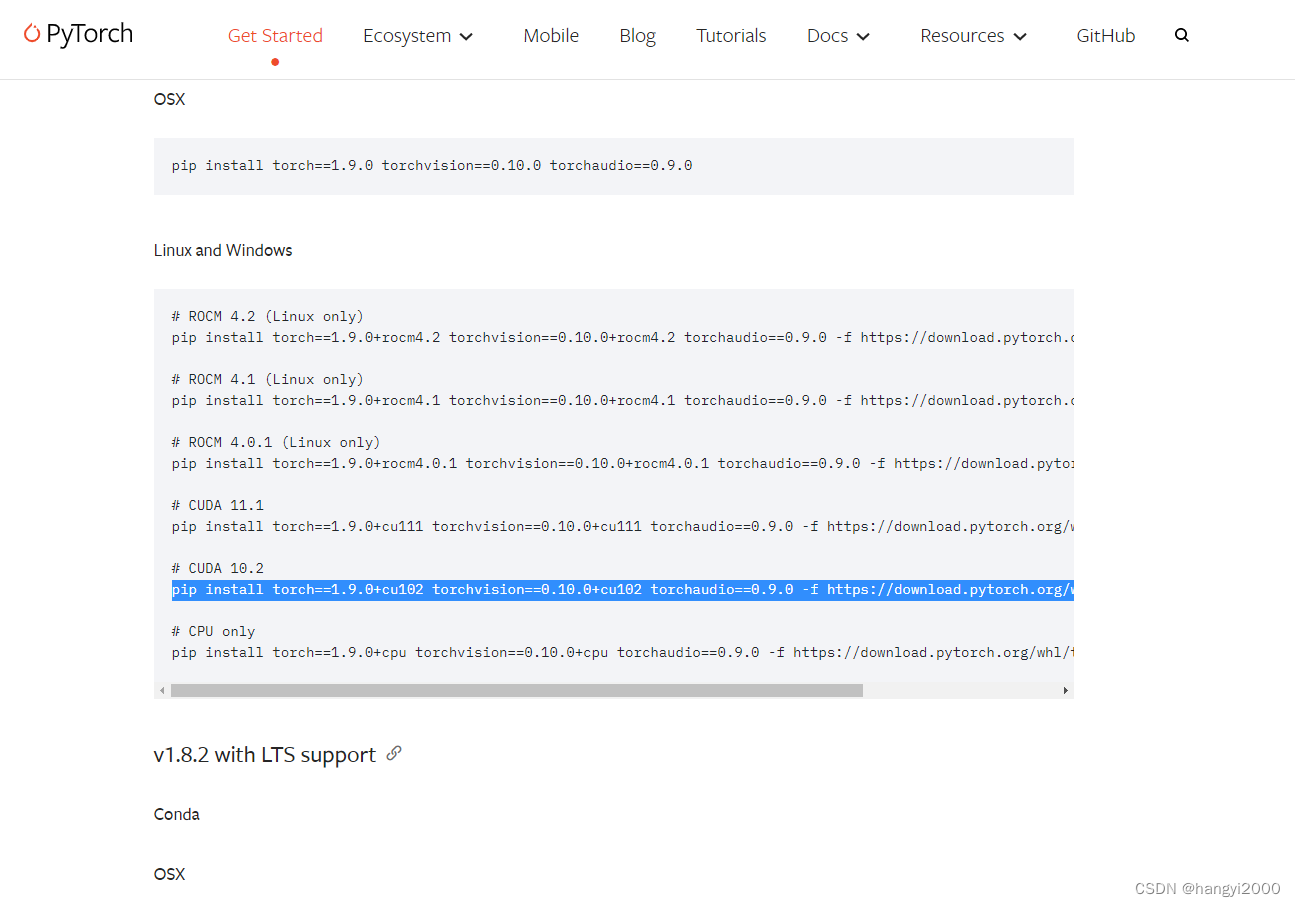
环境与报错 1. 环境安装版本 torch 1.9.0+cu102torchaudio 0.9.0torchvision 0.13.1a0 2. 出错的代码行 import torchvision 3. 报错 File "/usr/local/miniconda3/envs/***/lib

pytorch_quantization安装
官方安装步骤: pip install nvidia-pyindexpip install pytorch-quantization 直接安装pytorch-quantization会找不到,需要首先安装 nvidia-pyindex 包, nvidia-pyindex是一个 pip 源,用来连接英伟达的服务器下载需要的包。 如果pip install nvidia-pyindex安装失败
pytorch_quantization安装
官方安装步骤: pip install nvidia-pyindexpip install pytorch-quantization 直接安装pytorch-quantization会找不到,需要首先安装 nvidia-pyindex 包, nvidia-pyindex是一个 pip 源,用来连接英伟达的服务器下载需要的包。 如果pip install nvidia-pyindex安装失败

Learning-Based Just-Noticeable-Quantization- Distortion Modeling for Perceptual Video Coding
基于学习的恰可察觉量化 - 失真建模用于感知视频编码 摘要 - 传统的基于预测视频编码的方法正在达到其潜在的编码效率改进的极限,因为计算复杂性严重增加。作为替代方法,感知视频编码(PVC)已经尝试通过消除感知冗余来实现高编码效率,使用实时可观失真(JND)定向的PVC。先前的JND通过将白高斯噪声或特定信号模式添加到原始图像中来建模,这不适合于由于能量减少的失真而找到JND阈值。在本文中,我们提