probabilistic专题

Liver Segmentation in CT based on ResUNet with 3D Probabilistic and Geometric Post Process
一、摘要 本文提出了使用具有3D概率和几何后期处理功能的ResUNet的新型肝分割框架。 我们的语义分割模型ResUNet在U-Net的上采样和下采样部分添加了残差单元和批处理规范化层,以构建更深的网络。 为了快速收敛,我们提出了一种新的损失函数DCE,该函数由Dice损失和交叉熵损失线性组合。 我们使用连续的几个CT图像作为训练和测试的输入,以探索更多的上下文信息。 基于ResUNet的初始分割
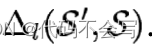
(论文阅读-优化器)Selectivity Estimation using Probabilistic Models
目录 摘要 一、简介 二、单表估计 2.1 条件独立Condition Independence 2.2 贝叶斯网络Bayesian Networks 2.3 查询评估中的贝叶斯网络 三、Join选择性估计 3.1 两表Join 3.2 概率关系模型 3.3 使用PRMs的选择性估计 四、PRM构建 4.1 评分标准 4.2 参数估计 4.3 结构选择 4.3.1
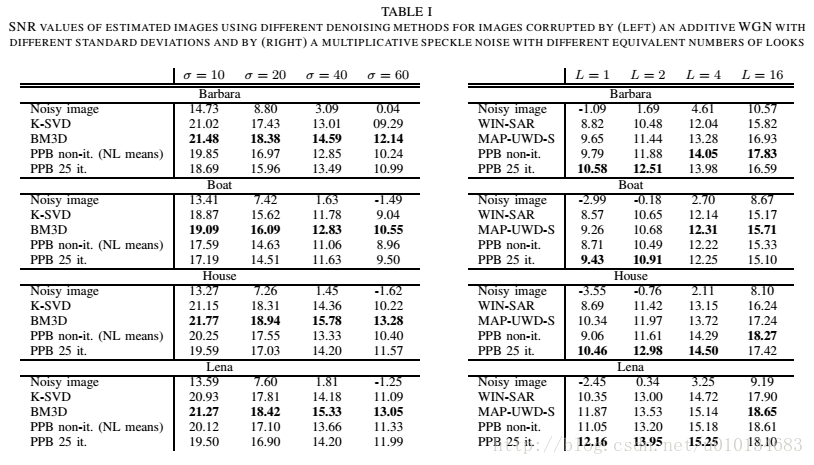
20170301笔记-iterative weighted maximum likelyhood denoising with probabilistic patch-based weight
实验结果。 搜索窗口|W|=21*21,相似窗口|△|=7*7。非迭代PPB h的设置,使α=0.88,迭代PPB参数设置:α=0.92,T=0.20|△|。25次迭代,确保收敛。 加性WGN,对比了 K-SVD, BM3D ,NL-means(non-iterative PPB) ,iterative PPB。乘性GSN,对比了WIN-SAR filter(Wavelet-based Ima

Introduction to Probabilistic Topic Models
此文为David M. Blei所写的《Introduction to Probabilistic Topic Models》的译文,供大家参考。 摘要:概率主题模型是一系列旨在发现隐藏在大规模文档中的主题结构的算法。本文首先回顾了这一领域的主要思想,接着调研了当前的研究水平,最后展望某些有所希望的方向。从最简单的主题模型——潜在狄立克雷分配(Latent Dirichlet Allocatio

Latent Diffusion Transformer for Probabilistic Time Series Forecasting
Latent Diffusion Transformer for Probabilistic Time Series Forecasting 摘要:多元时间序列的概率预测是一项极具挑战性但又实用的任务。本研究提出将高维多元时间序列预测浓缩为潜在空间时间序列生成问题,以提高每个时间戳的表达能力并使预测更易于管理。为了解决现有工作难以扩展到高维多元时间序列的问题,我们提出了一种称为潜在扩散变换器(L

【论文阅读】Probabilistic Imputation for Time-series Classification with Missing Data
Probabilistic Imputation for Time-series Classification with Missing Data 论文链接:https://icml.cc/virtual/2023/poster/23522 作者:SeungHyun Kim · Hyunsu Kim · EungGu Yun · Hwangrae Lee · Jaehun Lee · Juho
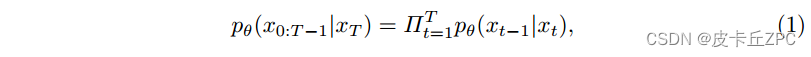
MedSegDiff: Medical Image Segmentation withDiffusion Probabilistic Model 论文阅读
论文地址:[2211.00611] MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model (arxiv.org) 代码:GitHub - KidsWithTokens/MedSegDiff: Medical Image Segmentation with Diffusion Model 摘要。扩散概率

李宏毅机器学习笔记(四)Classification: Probabilistic Generative Model
分类。概率生成模型 binary二进制 理想的做法 二分:大于0和小于0越好 损失函数 :错误次数越少 现有函数: perceptron感知机 SVM支持向量机 用回归来做二分不好的原因 数据偏移大时 结果不好分类 生成概率模型(GenerativeModel) 高斯分布 (Gaussian distribution
![[NNLM]论文实现:A Neural Probabilistic Language Model [Yoshua Bengio, Rejean Ducharme, Pascal Vincent]](https://img-blog.csdnimg.cn/9d892cdb8578462895e354e22f12e9c6.png)
[NNLM]论文实现:A Neural Probabilistic Language Model [Yoshua Bengio, Rejean Ducharme, Pascal Vincent]
A Neural Probabilistic Language Model 一、完整代码1.1 Python 完整程序 二、论文解读2.1 目标 三、过程实现3.1 Tensorflow模型3.2 数据准备3.3 数据训练和预测 四、整体总结 论文:A Neural Probabilistic Language Model 作者:Yoshua Bengio; Rejean Du

3D GAN:Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling
论文地址 一.Abstract 1.提出了一个新的框架,即3D生成对抗网络(3D- gan),它利用体卷积网络和生成对抗网络的最新进展,从概率空间生成三维对象. 2.首先,使用对抗准则代替传统的启发式准则,使生成器能够隐式地捕获对象结构,并同步大小相同的高质量3D对象. 3.生成器G建立了一个从低维概率空间到三维对象空间的映射,使我们可以在没有参考图像或CAD模型的情况下对对象进行采样,并探索
![[机器学习入门] 李宏毅机器学习笔记-5(Classification- Probabilistic Generative Model;分类:概率生成模型)](https://img-blog.csdn.net/20170602200424799?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc291bG1lZXRsaWFuZw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[机器学习入门] 李宏毅机器学习笔记-5(Classification- Probabilistic Generative Model;分类:概率生成模型)
[机器学习] 李宏毅机器学习笔记-5(Classification: Probabilistic Generative Model;分类:概率生成模型) Classification How to do Classification Ideal Alternatives

简单基础入门理解Denoising Diffusion Probabilistic Model,DDPM扩散模型
阅前须知:文中存在少许已证实/尚未证实的描述错误,建议结合评论区分析共同理解。 I. 作者的话 最近非常不巧的要研究什么diffusion…然而目前网上能找到的资料完全是设计给非常熟练数学的人看的(哪怕对于许多所谓的"入门教程",基本就是纯数学劝退教程),对于我这种高数概率论约等于挂科的人来说根本没法看。因此希望写一篇尽量通俗易懂,在尽量避免「概率论」的情况下,能把diffusion讲明白
MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
摘要 Diffusion probabilistic model (DPM) recently becomes one of the hottest topic in computer vision. Its image generation application such as Imagen, Latent Diffusion Models and Stable Diffusion h

MedSegDiff: Medical Image Segmentation withDiffusion Probabilistic Model
MedSegDiff:基于扩散概率模型的医学图像分割 摘要: 扩散概率模型(Diffusion probabilistic model, DPM)是近年来计算机视觉研究的热点之一。它在Imagen、Latent Diffusion Models和Stable Diffusion等图像生成应用中表现出了令人印象深刻的生成能力,引起了社区的广泛讨论。最近的许多研究还发现,它在许多其他视觉任务中也很
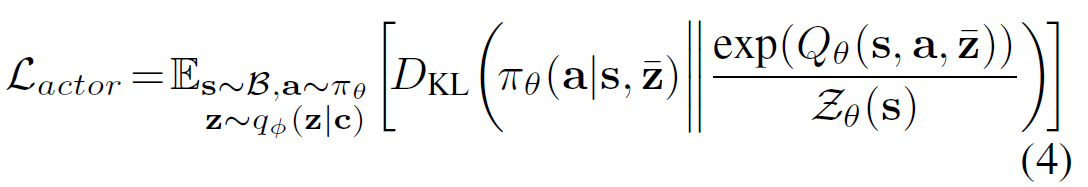
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
Abstract \quad 深度RL算法需要大量经验才能学习单个任务。原则上,元强化学习(meta-RL)算法使智能体能够从少量经验中学习新技能,但一些主要挑战阻碍了它们的实用性。当前的方法严重依赖于同策经验,从而限制了其采样效率。在适应新任务时,也缺乏推断任务不确定性的机制,从而限制了它们在稀疏奖励问题中的有效性。在本文中,我们通过开发一种异策元RL算法来解决这些挑战,该算法可以分离
14-----Hourly Probabilistic Forecasting of Solar Power
太阳能逐时概率预报 概率预测方法没看懂,图文基本无参考 随机森林(RF)。需要在RF中设置三个参数,数字树木- B(森林大小),M -预测因子的数量 Three parameters are required to be set in RF, the number of trees - B (forest size), m - the number of predictors out o
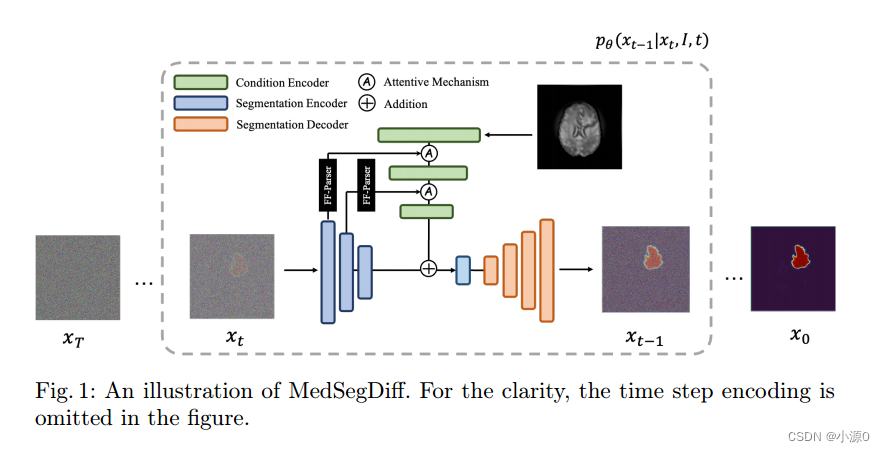
论文阅读:MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
论文标题: MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model 翻译: MedSegDiff:基于扩散概率模型的医学图像分割 名词解释: 高频分量(高频信号)对应着图像变化剧烈的部分,也就是图像的边缘(轮廓)或者噪声以及细节部分。 1. 动态条件编码 在大多数条件DPM中,条件先验是一个唯一的给定

【论文笔记】Denoising Diffusion Probabilistic Models
Pre Knowledge 1.条件概率的一般形式 P ( A , B ) = P ( B ∣ A ) P ( A ) P(A,B)=P(B|A)P(A) P(A,B)=P(B∣A)P(A) P ( A , B , C ) = P ( C ∣ B , A ) P ( B , A ) = P ( C ∣ B , A ) P ( B ∣ A ) P ( A ) P(A,B,C)=P(C|B,A

DeepAR:Probabilistic forecasting with autoregressive recurrent network
DeepAR:Probabilistic forecasting with autoregressive recurrent network 一般的时间序列预测方法是做点预测,即预测未来某个时间点的具体值。但对于一些具体业务比如预测销量来说预测一个概率区间更加易于决策。DeepAR是一个做概率预测的方法,同时也可以做点预测。 首先简单介绍一下时间序列和常见的处理方法 一、方法介绍 Deep

论文笔记5:Integrating Probabilistic Extraction Models and Data Mining to Discover Relations and Patterns
使用条件随机场抽取信息,抽取实体间的二元关系 一、论文要解决的问题 在信息抽取系统中,为了获得较好的性能,必须包含数据本身固有的关系模式,但是手工编写这些规则费时费力俄而且不可能编写全部规则。而且数据中存在一些隐藏的关系模式,这对提供信息抽取性能很有帮助。 二、论文使用的方法和亮点 2.1 亮点 提出一个集成机器学习模型,能够学习上下文关系和关联关系模式来抽取实体之间的关系,并使用线性链

PARIS: Probabilistic Alignment of Relations, Instances, and Schema笔记
该论文建立了一个概率模型,对关系、实体、类之间的概率进行建模,不需要任何参数即可完成实体对齐任务。其中,一部分公式借鉴了《Some entities are more equal than others: statistical methods to consolidate Linked Data》,但效果更出色,并且可以应用在大规模数据上。由于对这方面工作不了解,不清这项工作是否是state-o
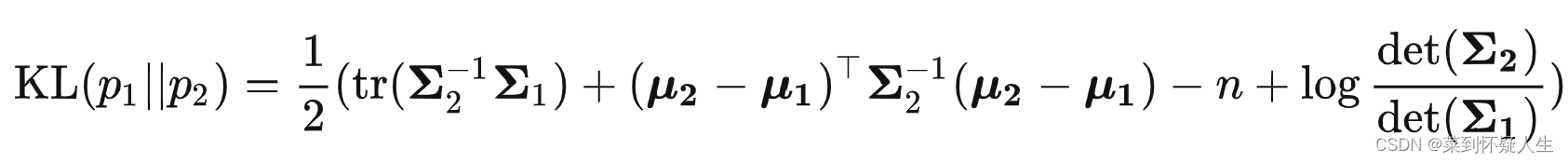
深度学习(生成式模型)——DDPM:denoising diffusion probabilistic models
文章目录 前言DDPM的基本流程前向过程反向过程DDPM训练与测试伪代码 前向过程详解反向过程详解DDPM损失函数推导结语 前言 本文将总结扩散模型DDPM的原理,首先介绍DDPM的基本流程,接着展开介绍流程里的细节,最后针对DDPM的优化函数进行推导,以让读者明白DDPM参数估计的原理。 本文不会对扩散模型的motivation进行讲解,作者有点鬼才,完全想不到他是怎么想出这

【论文阅读笔记】RISE: Robust Wireless Sensing Using Probabilistic and Statistical Assessments
RISE: Robust Wireless Sensing Using Probabilistic and Statistical Assessments 翟双娇 MobiCom 2021 阅读于 2021.11.04 ABSTRACT 无线感知存在的问题:感知鲁棒性和性能容易收到环境变化的影响 RISE:提高基于学习的无线感知在环境变化时的感知鲁棒性和精度 RISE结果:在11种