本文主要是介绍【论文阅读笔记】RISE: Robust Wireless Sensing Using Probabilistic and Statistical Assessments,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RISE: Robust Wireless Sensing Using Probabilistic and Statistical Assessments
翟双娇
MobiCom 2021
阅读于 2021.11.04
ABSTRACT
-
无线感知存在的问题:感知鲁棒性和性能容易收到环境变化的影响
-
RISE:提高基于学习的无线感知在环境变化时的感知鲁棒性和精度
-
RISE结果:在11种感知方法上进行评估,识别潜在的错误分类精度为92%,有助于感知技术在动态环境下保持性能
INTRODUCTION
-
无线信号,WiFi、RFID和声音 传感媒介 智能家具、跌倒监测、情绪监测、生命体征监测
-
机器学习在无线感知中优于基于模型的方法。机器学习的关键点:训练和测试样本要是 独立同分布(iid,independently identically distribution) 的。但是在实际中,由于环境中物体的移动或者活动位置的变化,测试数据的分布偏离训练样本的分布,导致预测精度变差。此称之为数据漂移 data drift
-
现有方法针对数据漂移的提高系统鲁棒性的应对方法:①数据增强 :合成虚拟训练样本or宠用多个感知任务数据,提高机器学习模型的泛化性。但是这样并不能覆盖所有的环境变换。 ②找到一组对环境具有健壮性的特征:
-
本文方法:基于拒绝的分类:通过识别、跟踪、减轻漂移来应对数据漂移现象。自适应地使用漂移样本更新模型、或者拒绝可能导致作物预测的漂移点、或者选择一个能够处理给定输入的替代模型
-
本文方法的关键:如何快速确定何时、如何对数据漂移进行应对。也就是我们怎么确定一个测试样本是否存在数据偏移,感知模型会对这个偏移的测试样本进行错误的预测。
-
RISE利用在分类过程中产生的概率分布。一个漂移样本可能会导致类标签的偏态分布,从而导致错误的高置信度。RISE寻找统计特征来评估预测的可信度:利用共型预测理论conformal prediction theory来量化测试样本和训练样本的奇异性。我们的直觉是,如果测试样本与训练分布有显著的不同,预测模型将难以做出正确的预测,因为它在训练过程中没有获得正确的知识
-
为了找出潜在的错误预测(漂移样本),本文蒋概率和统计评估结果结合,输入到SVM异常检测器中异常检测器根据评估结果接受或拒绝感知结果。
-
RISE有效地支持两种策略来增强感知鲁棒性。①增量学习②专家混合(集成) ①增量学习:利用在环境中收集的漂移样本对传感模型进行重新训练,RISE引导开发人员的注意力在偏移样本上 ②专家混合:同构采用多个预测模型(专家) ,并且只使用具有高可信度的预测
-
Results 在11种基于学习的感知方法中聘雇RISE:包括感知、手势识别、手指输入识别,包括WiFi、RFID、声音、振动、传感器数据。包括多种机器学习、深度学习。 经验上基于学习的感知方法时不鲁棒的,环境的微小变化会造成糟糕的性能。 RISE在检测漂移样本方面:成功识别了平均92%的偏移样本 RISE可以将在动态环境中的感知性能提高到在静态环境中获得的性能。 RISE只需要标记前三个预测的漂移样本,并使用这些漂移样本来更新传感模型,提高传感模型在面对数据漂移时的鲁棒性和性能
-
Contributions:
-
本文首先在部署过程中利用拒绝分类来增强基于学习的感知鲁棒性;
-
采用共型预测和异常检测来检测数据位移(第3节);
-
将增量和集成学习和异常检测相结合,以提高感知性能(第3.4节
BACKGROUND AND MOTIVATION
Problem Scope
本文的方法重点在于提高基于学习的无线感知在环境变化时的鲁棒性和性能
Impact of Environmental Changes
环境变化的影响 WiFi手势识别:使用了不同的预测模型技术和无线信道特征
-
WiG:
-
WiAG:使用虚拟样本提高感知模型的泛化性的数据增强方法
-
手势:6个:“push and pull”, “draw a circle”, “throw”, “slide”, “sweep” and “draw zigzag”.
-
实验场景:暗室:射频无回声室内的控制环境中
-
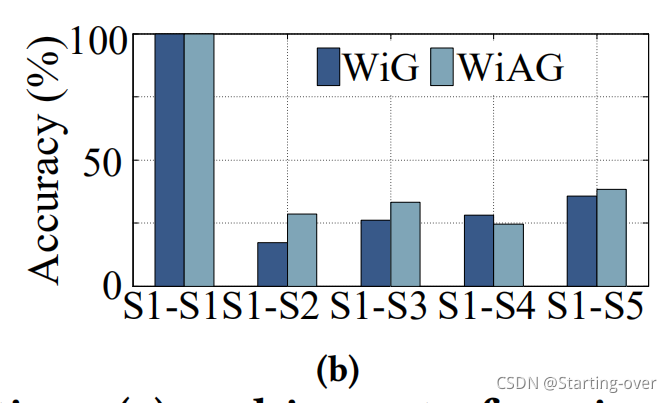
实验部署:3个活动位置S1,S2,S3,2个环境变化点S4,S5(放椅子,模拟由于环境变化而导致的多路径) fig1(a)
-
实验对象:可编程机械臂模拟人执行目标手势
-
实验过程:使用从S1收集的数据来训练感知模型,并将学习的模型应用于每种实验部署获得的样本。还使用了WiAG的方法来生成从S2到S5的虚拟样本。结果如fig1(a)

8. 实验结果:从S1的训练模型应用到S1的测试时100%的精度。S1模型应用于S2-S5,精度40%。说明环境的变化会对感知性能产生严重的影响 fig1(b)
Evaluating Model Credibility
模型可信度评估 举例:二分类问题:感知模型需要预测输入是否属于两类。在进行预测的时候,模型会估计输入属于每个类的概率得到r1,r2(表示输入属于类1和类2的概率)。如果在训练阶段没有观察到该输入模式,该模型可能会对这个输入给出一个较低的概率分数r1趋近于0,这将导致另一类r2趋近于1(r1+r2恒等于1)。这样就会导致r2被动的有了一个很高的概率值 为了评估模型输出的概率的可信度,需要一种方法来评估输入样本是否在模型的训练样本知识范围内。如果我们可以实现这个,就可以在上面那个例子中给两个类分配一个低可信度的分数
OUR APPROACH
RISE的核心就是量化分类结果的可信度,然后将评估结果输入到异常检测器中,来确定我们是否应该接受感知结果。 RISE不需要改变底层的感知模型,RISE将感知模型产生的概率作为输入 fig2 基于概率的机器学习分类器RISE的框架图

Probability Assessment
概率评价 为了评估基于分类的感知模型对给定输入的置信度,计算概率显著性probability significance 。所选类相对于其他类的概率差别越显著,分类器的可信度就越高。 举例: 一个基于分类的感知模型对样本a和样本b的分类概率输出分别为{0.51、0.48、0.003、0.003、0、0.004}和{0.51、0.12、0.12、0.12、0.13}。ab两个样本都将被归为类1,但是观察概率分布a样本的概率差(0.51vs0.48)不如b样本的概率差显著(0.51vs0.12) 根据这一观察结果,我们使用概率分布来估计模型在进行预测时的置信度。为此,我们将底层分类器给出的概率向量提供给异常检测器,以将概率分布与预测置信度相关联
Statistical Assessment
统计评价 评估模型的可信度:共型预测CP理论:通过使用过去的经验来解释数据漂移来计算预测的可信度水平 Conformal prediction 共型预测CP理论
一个分类器g,一个显著性水平ε,CP产生一个预测区域:一个候选标签集,保证包含概率不超过1-ε 为了生成标签集,CP使用来自g的不一致性度量 nonconformity measure来量化测试样本和之前的训练样本的不同。 如果一个输入样本越偏离训练集,那么模型预测的可信度越低。因此低的可信度说明输入样本存在漂移,这样的样本有被错误分类的风险
Nonconformity measures.
不一致性度量 使用一个不一致函数f来评估样本s和之前的样本的不同。B = s_1,s_2, . . .,s_n, Nonconformity measures NCM a_s= f(B,s).。NCM越大,s与B中其他样本的相似性越小
Compute the p-value
计算p值 构建一个共型评估器来决定接受或者拒绝一个不属于训练集B的测试(输入)样本 使用不一致函数f来计算一个p值,p作为评估新样本和训练集中样本的相似性
使用不一致函数f离线计算一组不一致评分 其中a_1y,a_2y,...,a_ny分别表示对于训练集中的每个实例到其标签y的不一致评分 测试的时候,需要计算第n+1个,也就是新输入的测试样本的不一致得分a_(n+1)y_p,然后根据下面的式子计算p值
计算比例标签为y_p的样本的不一致分数大于或等于样本s属于y_p标签类的训练样本的比例 如果p值很小,说明新样本与训练集中的而样本非常不同 如果p值很大,说明新样本与训练集中标签为y_p的样本十分相似
The statistical vector
统计向量 对于给定的一个测试样本,我们计算这个样本对于每个类的p值从而得到一组p值,称为统计向量
Detect Shifting Samples
检测漂移样本 将概率向量和统计向量作为异常检测器(SVM)的输入,来检测漂移样本 异常检测的关键时检测边界外的样本。在特征空间中确定一个边界,边界外的样本就被认为时离群值,也就是漂移样本
-
在RISE中就是将概率向量和统计向量输入到SVM分类其中,SVM学习出一个超平面异常检测模型来。
-
使用超平面异常检测模型来对测试样本进行判断,看测试样本是在超平面边界内还是边界外。如果在超平面边界外,那就是一个漂移样本。
工作过程 训练:
十折交叉训练一个n类{c1,c2,c3,...,cn}的感知模型m和n个单类SVM异常检测器Mc1、Mc2、···、Mcn(感知模型用9份,异常检测器用1份)
得到训练样本的概率向量{r1,r2,...,rn}
根据共型理论得到统计向量{p1,p2,...,pn}
将概率向量和统计向量共2n个点输入到一个2分类的SVM异常检测器中,SVM的输出为:接受还是拒绝感知模型的分类结果
使用k-fold交叉验证计算每个训练样本的概率向量和统计向量,然后使用同一标签的训练样本的概率向量和统计向量对单类SVM进行训练
测试
测试样本st
得到感知模型m对st样本的预测结果c_st
得到测试样本的概率向量{r_st1,r_st2,...,r_stn}
得到测试样本的统计向量{p_st1,p_st2,...,p_stn}
根据c_st选择对应的Mcst来得到样本st的结果c_st是可接受的还是要被拒绝的。
本文只做到检测,至于如何补救or纠正漂移样本,还没说
Improve Sensing Robustness
提高感知鲁棒性 增量学习提高感知模型的性能 集成学习提高感知模型的鲁棒性
Incremental learning
上面说到RISE可以检测出漂移样本,通过手动标记漂移样本并将其添加到现有的训练数据集中,我们可以重新训练感知模型,并更新新样本上的异常检测器。
Ensemble learning
集成学习:训练一组分类器,并聚合不同分类器给出的结果 RISE使用异常检测器过滤掉低置信度的预测,然后再使用多数投票产生最终的分类
Implementation
实验
EXPERIMENTAL SETUP
Case Studies
将RISE应用于这11种具有代表性的基于学习的感知技术
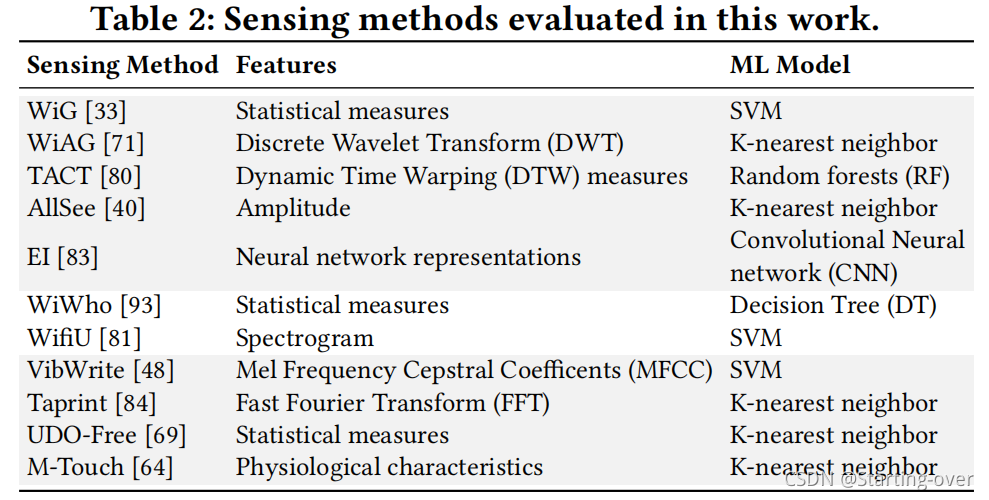
包括通用的无线感知,机器学习算法和特征,数据增强方法等 复现这些方法,并对比了使用RISE和未使用RISE的结果
Testing Environments
在暗室和日常环境中收集原始的无线信号


Sensing Tasks and Notations
Device Setup
Environmental Changes
图5中可以看出,从同一环境中收集的数据点位于投影区域附近,来自不同设置的样本倾向于分组为单独的集群。这表明,所引入的环境变化确实影响了无线样本的数据分布
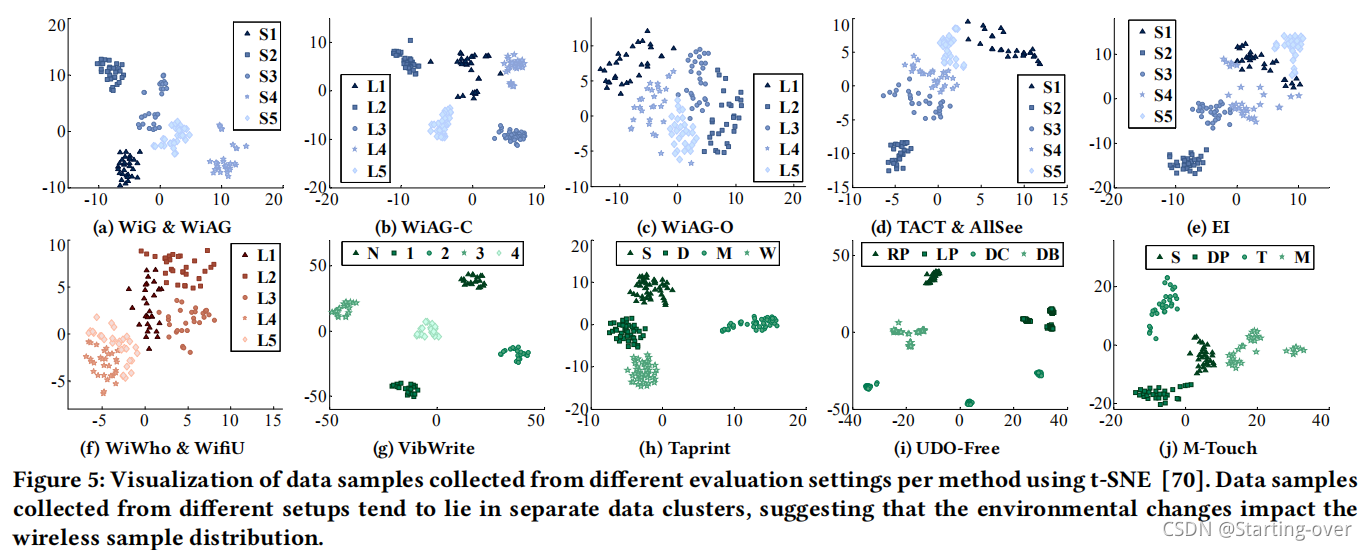
Evaluation Methodology
评估两个方面:
-
RISE能否有效过滤漂移样本
-
RISE是否可以提高已部署的传感模型的鲁棒性
Model evaluation
两个训练测试场景:静态的和动态的。
-
在静态环境中,训练和测试样本来自相同的设置。
-
在动态设置中,我们混合了来自不同设置的数据样本,包括用于收集感知模型训练数据和来自其他环境设置的数据样本。
Metrics
-
Accuracy
-
Precision (P)
-
Recall (R)
-
F1-score
EXPERIMENTAL RESULTS
评估两个方面:
-
RISE能否有效过滤漂移样本——RISE可以识别出92.3%的漂移样本
-
RISE是否可以提高已部署的传感模型的鲁棒性——RISE平均将已部署模型的性能提高21%
Overall Results
图6显示了在静态和动态环境下的传感精度。Rise可以帮助滤掉漂移样本,并通过增量学习保持感知性能

-
在静态环境下,所有传感方法的预测精度均在93%以上。
-
在动态设置中性能受到影响,我们观察到预测精度平均下降22%。漂移样本的无线信号对WiFi和超声波的影响也很明显,我们看到预测精度下降了40%以上
-
通过应用RISE滤掉漂移样本,并使用少量标记漂移样本来更新传感模型,可以将相关方法的精度保持在接近其在静态环境中性能的水平。我们还看到,无论底层的机器学习或无线信号如何,Rise的性能都是稳定的
Detecting Shifting Samples
图7显示了RISE对预测漂移样本的性能

-
对于大多数(80%)的传感方法,Rise给出的平均精度为92%(至少89%),对于给定方法的平均精度为96%(至少94%)
-
总的来说,Rise给出了94.5%的准确率和92.3%,平均为92.3%。结果转化为假阳性率为1.8%,假阴性率(即缺失错误预测)为7.7%。
-
Rise允许开发人员配置我们的CP模型的重要级别,ε,以控制需要手动检查的样本的数量。由于置信度计算为1-ε,一个较小的ε将导致更频繁的假阳性,但这可以减少错误预测的影响。在这项工作中,我们通过对校准数据集应用交叉验证,将ε设置为0.1。
Improving Sensing Methods
我们已经证明了上升在检测漂移样品方面是有效的。我们现在演示了两种使用Rise来提高感知性能和鲁棒性的方法
Incremental learning
图8显示了需要来自部署环境中的多少个新示例来更新模型,以在静态环境中实现其95%的性能。

-
w/RISE :Rise平均只需要在预测会漂移的样本中标记1.12(通常只有一个)。这意味着需要用户干预的测试样本减少了89%。Rise的一个关键好处是,它可以自动检测何时需要模型更新。这种能力减少了人力的努力,只有在数据漂移发生时才寻求用户的参与
-
Random:首先随机选择测试样本来贴标签,然后将标记的样本添加到现有的训练数据集中,以更新已部署的模型。这种随机策略通过要求用户或系统开发人员确认或标记底层模型可以成功处理的活动来缺乏用户体验或较高的维护成本
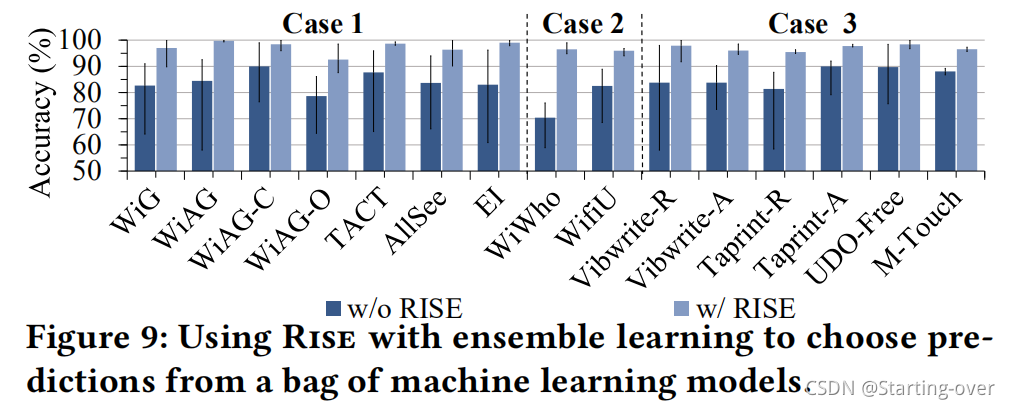
Ensemble learning
在这个实验中,我们使用相同的训练数据集来训练单个分类模型,然后使用我们的异常检测器来选择前5个预测(第3.4节)对结果进行投票
从图9中可以看出,基于集成学习的方法可以通过使用单片模型来提高感知性能。这一观察结果与之前的研究[96]一致
通过过滤掉糟糕的模型预测,Rise进一步提高了平均13%的集成性能。这表明,RISE和集成学习可以结合在一起,以提高感知的鲁棒性
Individual Case Studies
Case Study
Model Analysis
Measures for anomaly detection
图14显示了仅使用概率(3.1)或统计向量(3.2)时检测漂移样本的性能

Choices of anomaly detectors
单类SVM性能最好

Runtime overhead
测量测试样本的置信度和可信度分数的时间很小,不到20毫秒(ms)。异常检测的开销也可以忽略不计,在我们的评估过程中小于5ms
DISCUSSIONS
RELATED WORK
CONCLUSIONS
这篇关于【论文阅读笔记】RISE: Robust Wireless Sensing Using Probabilistic and Statistical Assessments的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







