本文主要是介绍(论文阅读-优化器)Selectivity Estimation using Probabilistic Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
摘要
一、简介
二、单表估计
2.1 条件独立Condition Independence
2.2 贝叶斯网络Bayesian Networks
2.3 查询评估中的贝叶斯网络
三、Join选择性估计
3.1 两表Join
3.2 概率关系模型
3.3 使用PRMs的选择性估计
四、PRM构建
4.1 评分标准
4.2 参数估计
4.3 结构选择
4.3.1 评分审视
4.3.2 模型空间
4.3.3 搜索算法
五、实验结果
六、总结
摘要
对于涉及多个属性选择和多个关系连接的复杂查询,其结果大小的估计是数据库查询处理中一项困难而又基本的任务。它出现在基于成本的查询优化、查询分析和近似查询回答中。在本文中,我们展示了如何有效地使用概率图形模型作为跨多个关系的多个属性联合频率分布的精确和紧凑的逼近来完成这项任务。概率关系模型(Probabilistic Relational Models, PRMs)是最近的一项发展,它将图形统计模型(如贝叶斯网络)扩展到关系领域。它们表示表中属性之间以及跨外键连接的属性之间的统计依赖关系。我们提供了一种从数据库构建PRM的有效算法,并展示了如何使用PRM对广泛的查询类计算选择性估计。这项工作的主要贡献之一是为涉及选择和外键连接操作的查询的时间确定提供了统一的框架。此外,我们的方法并不局限于回答一小部分预先确定的查询;可以使用单个模型有效地估计跨多个表的大量潜在查询集合的大小。我们在几个真实的数据库上展示了我们的方法的结果。对于单表多属性查询和一般的select-join查询,我们的方法使用可对比的空间和时间,比标准的选择性估计方法产生更准确的估计。
一、简介
概率图模型是一类用图形模式表达基于概率相关关系的模型的总称。概率图模型结合概率论与图论的知识,利用图来表示与模型有关的变量的联合概率分布。近10年它已成为不确定性推理的研究热点,在人工智能、机器学习和计算机视觉等领域有广阔的应用前景。 [1]
基本的概率图模型包括贝叶斯网络、马尔可夫网络和隐马尔可夫网络。
基本的Graphical Model 可以大致分为两个类别:贝叶斯网络(Bayesian Network)和马尔可夫随机场(Markov Random Field)。它们的主要区别在于采用不同类型的图来表达变量之间的关系:贝叶斯网络采用有向无环图(Directed Acyclic Graph)来表达因果关系,马尔可夫随机场则采用无向图(Undirected Graph)来表达变量间的相互作用。这种结构上的区别导致了它们在建模和推断方面的一系列微妙的差异。一般来说,贝叶斯网络中每一个节点都对应于一个先验概率分布或者条件概率分布,因此整体的联合分布可以直接分解为所有单个节点所对应的分布的乘积。而对于马尔可夫场,由于变量之间没有明确的因果关系,它的联合概率分布通常会表达为一系列势函数(potential function)的乘积。通常情况下,这些乘积的积分并不等于1,因此,还要对其进行归一化才能形成一个有效的概率分布——这一点往往在实际应用中给参数估计造成非常大的困难。
概率图模型有很多好的性质:它提供了一种简单的可视化概率模型的方法,有利于设计和开发新模型;用于表示复杂的推理和学习运算,可以简化数学表达。 [3]
准确估计查询结果的大小对于数据库管理系统(DBMS)的几个查询处理组件来说是至关重要的。基于成本的查询优化器使用中间结果大小估计来选择最优的查询执行计划。查询分析器在查询设计阶段通过预测资源消耗和查询结果的分布向DBMS用户提供反馈。精确的选择性估计还允许在多处理器系统上实现高效的并行连接负载平衡。选择性估计还可用于近似地回答计数(聚合)查询。
对多个属性的选择查询的结果大小由这些属性值的联合频率分布决定。联合分布对所有属性值组合的频率进行编码,因此随着属性和值的增加,精确地表示它的方案变得不可行。大多数商业系统通过采用几个关键假设来近似联合分布;这些假设允许快速计算选择性估计,但是,正如许多人注意到的,估计可能是非常不准确的。
第一个常见的假设是属性值独立假设(attribute value independence assumption),在该假设下,单个属性的分布是相互独立的,联合分布是单属性分布的产物。然而,真实的数据往往包含违背这一假设的属性之间的强相关性,导致非常不准确的近似。例如,一个普查数据库可能包含高度相关的属性,如Income和Home-owner。属性值独立性假设会导致对请求低收入房主的查询结果大小的高估。
第二个常见的假设是连接一致性假设(join uniformity assumption),它表示来自一个关系的元组与来自第二个关系的任何元组连接的可能性相等。同样,在许多情况下,这一假设是违反的。例如,假设我们的人口普查数据库有一个用于在线购买的第二个表。高收入人群通常会比平均水平网购更多。因此,购买表中的元组更有可能与高收入个人的元组连接,从而违反了连接一致性假设。如果我们考虑一个针对高收入个人购买的查询,使用连接一致性假设的估计过程很可能会大大低估查询的大小。
为了放宽这些假设,我们需要一种更精细的方法,考虑多个属性的联合分布,而不是单独考虑属性的分布。最近提出了几种联合分布近似的方法,也称为数据约简;请参阅[2]以获得该领域的优秀摘要。这些工作的大部分集中在评估单个表中选择操作的选择性的任务上。一种简单的近似查询大小的方法是通过随机抽样。在这里,生成一组样本,然后通过计算相对于采样数据的实际查询结果大小来估计查询结果大小。然而,精确估计所需的数据量可能相当大。最近,提出了几种方法,试图更直接地获取属性的联合分布。其中最早的是Poosala和Ioannidis的多维直方图方法[23,25]。它们为构造多维直方图的方法分类提供了广泛的探索,并研究了不同技术的有效性。文中还提出了一种基于奇异值分解的方法,该方法仅适用于二维场景。一种新的方法是使用小波wavelets来逼近潜在的联合分布[21,27,6]。
在估计连接的选择性方面所做的工作要少得多。商业DBMS通常做出统一连接的假设。建议的一种方法是基于随机抽样:对两个表进行随机抽样,并计算它们的连接。这种方法在几个方面有缺陷,一些工作致力于以更有针对性的方式生成样本的替代方法[20]。最近另一种替代方法是Acharya等人[1]关于连接概要的工作,它维护一些不同连接的统计信息。据我们所知,目前还没有对现实世界中同时包含select和join操作的查询支持选择性估计的方法进行研究。
在本文中,我们基于概率图模型领域的技术[17,24],提出了一种选择性估计问题的替代方法。正如我们将展示的,我们的方法有几个重要的优点。首先,它为选择选择估计和外键连接选择估计提供了统一的框架,并引入了一种系统的方法来估计这两种操作符的查询大小。其次,我们的方法不局限于回答一小部分预先确定的查询;可以使用单个统计模型对数据库中任何一组表和属性有效地估计任何查询(选择外键连接)的大小。
概率图形模型是一种用于紧表示高维空间中复杂联合分布的语言。它们基于图形表示法,对分布中属性之间的条件独立性进行编码。当两个属性是相关的,但相互作用是通过一个或多个其他变量中介时,就会出现条件独立性。例如,在人口普查数据库中,教育程度与收入相关,有房者身份与收入相关。因此,教育与有房者地位相关,但仅通过收入水平间接相关。这种类型的交互在实际领域中非常常见。概率图形模型利用了存在于域中的条件依赖关系,从而允许我们紧凑地指定高维空间上的联合分布。
在本文中,我们提供了一个使用概率图模型估计关系数据库中查询选择性的框架。正如我们所展示的,贝叶斯网络(bn)可以用来表示单个表中属性之间的交互,提供table中的属性上的联合分布的高质量估计。概率关系模型[18](PRMs)将贝叶斯网络扩展到关系设置。正如我们所展示的,PRM允许我们表示表之间连接概率的倾斜,以及通过外键连接的元组属性之间的相关性。因此,它们允许我们评估涉及多个表上的选择和连接的查询的选择性。
与大多数选择性估计算法一样,我们的算法由两个阶段组成。脱机阶段offline phase,在脱机阶段中,从数据库构建PRM。这个过程是自动的,完全基于数据和分配给统计模型的空间。第二个阶段(在线阶段online phase)是对特定查询的选择性估计。选择性估计器selectivity estimator接收一个查询和一个PRM作为输入,并输出查询结果大小的估计。注意,同样的PRM用于估计数据库中任何属性子集的查询的大小;我们不需要事先获得关于查询工作负载的信息。
在本文中,我们做了两个重要的假设。首先,外键遵守引用完整性。这个关于数据库的假设在构建PRM时是必需的。其次,所有连接都是外键和主键之间的相等连接。做这个假设纯粹是为了便于表示。虽然外键连接的查询从我们提出的概率模型中获益最大,但我们的方法并不局限于处理这些查询,我们在第6节中描述了如何将我们的方法扩展到更广泛的连接类。
本文其余部分的结构如下。在第2节中,我们考虑在单个表上选择操作的选择性估计。我们定义了贝叶斯网络,并展示了如何使用它们来近似表中所有属性集合上的联合分布。在第3节中,我们将讨论对多个表进行查询的更复杂的情况。我们介绍了PRM框架,它将贝叶斯网络推广到关系情况,并展示了我们如何使用PRM在单个框架中完成选择和连接选择估计。在第4节中,我们提出了一个从关系数据库自动构造PRM的算法。在第5节中,我们提供了我们的方法的经验验证,并将其与一些最常见的现有方法进行比较。我们展示了在几个真实世界领域的实验,表明我们的方法提供了比以前的方法更高的准确性(在给定的空间量),在非常合理的计算成本,包括离线和在线。
二、单表估计
我们首先考虑对单个关系上的选择查询的结果大小进行估计。对于本节的大部分内容,我们将注意力限制在每个属性的值数量相对较少(最多50个)的域,以及使用attribute = value形式的相等谓词的查询。这些限制都不是我们方法的根本限制;在本节的最后,我们将讨论如何将我们的方法应用于具有较大属性值空间的域和范围查询。
让R来代表一些table;我们使用R.*来表示表示R中属性A1, ..., An的值(非key)。我们将A1, ..., An的联合频率分布表示为FD(A1, ..., An)。它便于处理归一化频率分布PD(A1, ..., An):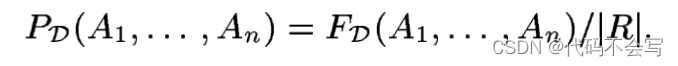
这样的转换允许我们将PD(A1, ..., Ak)作为一个概率分布处理。我们同样可以将这个联合分布看作是一个虚构的过程产生的,在这个过程中,我们从一个R中采样出一个元组r,然后选择r A1,…,an的值作为r中A1,…,r.An的值(请注意,我们并不是建议在实践中执行用于定义PD的取样过程。我们只是用它来作为一种定义PD的方法)。
现在,我们来考虑一个基于一组属性A1,...,Ak⊆R.*之上的查询Q,它是一组格式为Ai=vi的选择的组合。假设IQ是为Q中对r能使等式成立的事件。显然query Q的结果大小为:
其中FD(Q)是满足Q的元组数量,PD(IQ)是概率,相对于D,事件Q。为了简化符号,我们经常会简单地使用PD(Q)。由于relation的大小是一直的,联合概率分布包含了查询大小估计所需要的全部信息。因此,我们重点关注联合概率分布。
不幸的是,这种联合分布的条目数量随着属性数量呈指数级增长,因此明确表示这个联合分布几乎总是棘手的。有人提出了几种方法,通过使用更紧凑的结构来逼近联合分布(或联合分布的投影)来绕过这个问题[25,21]。我们也建议使用统计模型来近似完全联合分布。但是为了以紧凑的方式表示分布,我们探索了经常会在真实世界数据中的联合分布中具备的条件独立condition independence。通过将联合分布的表示法分解成能捕获域中独立性的因子,我们得到了该分布的一个紧凑表示法。
2.1 条件独立Condition Independence
考虑在一个简单relation R中的三个值属性,其每个值域都展示在括号中:Education(hight-school, college, advancd-degree)、Income(low, medium, hight)和Home-owner(false, true)。为了方便,我们使用每个名称的首字母来代表它,对属性使用大写字母,对于属性的特定值使用小写字母。我们使用P(A)来代表属性A可能的值的概率分布,P(a)代表事件A=a的概率。
假设在一个数据库中的属性值的联合概率分布如Fig.1(a)所示。使用这个联合分布,我们可以计算出来基于E,I和H上的的任意查询的选择率selectivity。为了方便,我们使用Qeih来代表一个格式为E=e, I=i, H=h的选择查询。然后会得到sizeQeih[D] = |R| * PD(e,i,h)。然而,为了精确表示这个联合分布,我们需要存储18个数值,其中每一个代表属性值可能的组合。(实际上,我们可以只使用17个数值,因我们我们知道联合分布中的和一定为1)。
然而,在许多上场景下,我们的数据将会以一种特定的结构展示,来允许我们(近似地)使用一种更紧凑的格式来代表分布。直觉上,某些属性之间的关联可能是间接的,由其他属性推导。例如,教育对拥有住房的影响可能通过收入来调节:一个高中辍学生拥有一家成功的互联网创业公司,比一个受过高等教育的海滩流浪汉更有可能拥有住房——收入是主导因素,而不是教育。这一断言可以以这样的描述来格式化表示:基于给定Income,Home-owner条件独立于Education。即,对于每一个h,e,i的组合来说,我们可以获得: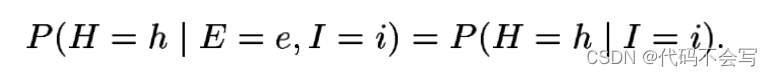
这个假设适用于Fig.1中的分布。
条件独立假设允许我们以分解的形式来更紧凑地表示联合分布。我们会展示:Education的边缘分布 - P(E);给定Education下的Income条件分布 - P(I|E);和一个给定Income下Home-owner的条件分布 - P(H|I),而不是直接展示P(E,I,H)。我们可以很容易证明,如果条件独立假设成立,这样的表示包含了原始联合分布中的所有信息:
最后一个等式是由和给定的条件独立性推导出来的。在我们的例子中,联合分布可以用Fig.1(b)所示的三个表来表示。很容易验证它们编码的联合分布与Fig.1(a)完全相同。
拆解后的存储要求好像和之前是一样的:3+9+6=18。实际上,如果我们考虑到有些参数是多余的,因为这些数字加起来必须等于1,我们将获得 2 + 6+ 3 = 11,对于与完全联合的17。虽然这种情况下的节省似乎不是特别令人印象深刻,但只要直接依赖项的数量保持有限,节省就会随着属性数量的增加呈指数增长。
注意,条件独立性假设是完全不同于标准属性独立性假设。在这种情况下,例如,三个属性的一维直方图(即边缘分布)如图1(c)所示。很容易看出,在这种情况下,我们从属性独立性假设中得到的联合分布与真正的潜在联合分布非常不同。同样重要的是要注意,我们的条件独立假设与在这个分布中存在的房屋所有者和教育之间的强相关性是相容的。因此,条件独立性是一个比标准(边际)独立性弱得多且更灵活的假设。
2.2 贝叶斯网络Bayesian Networks
贝叶斯网络是高维联合分布的紧凑图形表示。它探索了域的底层结构-事实上,只有域的几个少数方面会直接相互影响。我们将概率空间定义为relation R中的属性集合A1,...,An的集合的可能赋值集合。贝叶斯网络BNs可以通过利用可以捕获属性之间的条件独立的结构,来紧凑地表示在A1,...,An之上的联合分布,从而利用概率影响的“局部性”。
一个贝叶斯网络β由两个组件组成。第一个组件,G,是一个有向无环图,其节点对应于属性A1,...,An。图中的边表示一个属性Ai和它的父Parents(Ai)的直接依赖。这个图结构将一组条件独立假设进行编码:每个节点Ai条件地独立于其父节点的非后代节点。
Fig.2(a)显示了使用美国人口普查局的数据提取系统从1993年当前人口调查中获得的数据(自动)构建的贝叶斯网络。在这个场景中,table包含12个属性:Age, Worker-Class, Education, Marital-Status, Industry, Race, Sex, Child-Support, Earner,Children, Income, and Employment-Type. 这些属性的域大小分别为:18, 9, 17, 7, 24, 5, 2, 3, 3, 42, 和 4。我们可以看到,举例来说,Children属性(代表家庭中是否有children)只通过属性Income、Age和Marital-Status依赖其他的属性。因此,Children在给定的Income、Age和Marital-Status下条件独立于其他的属性。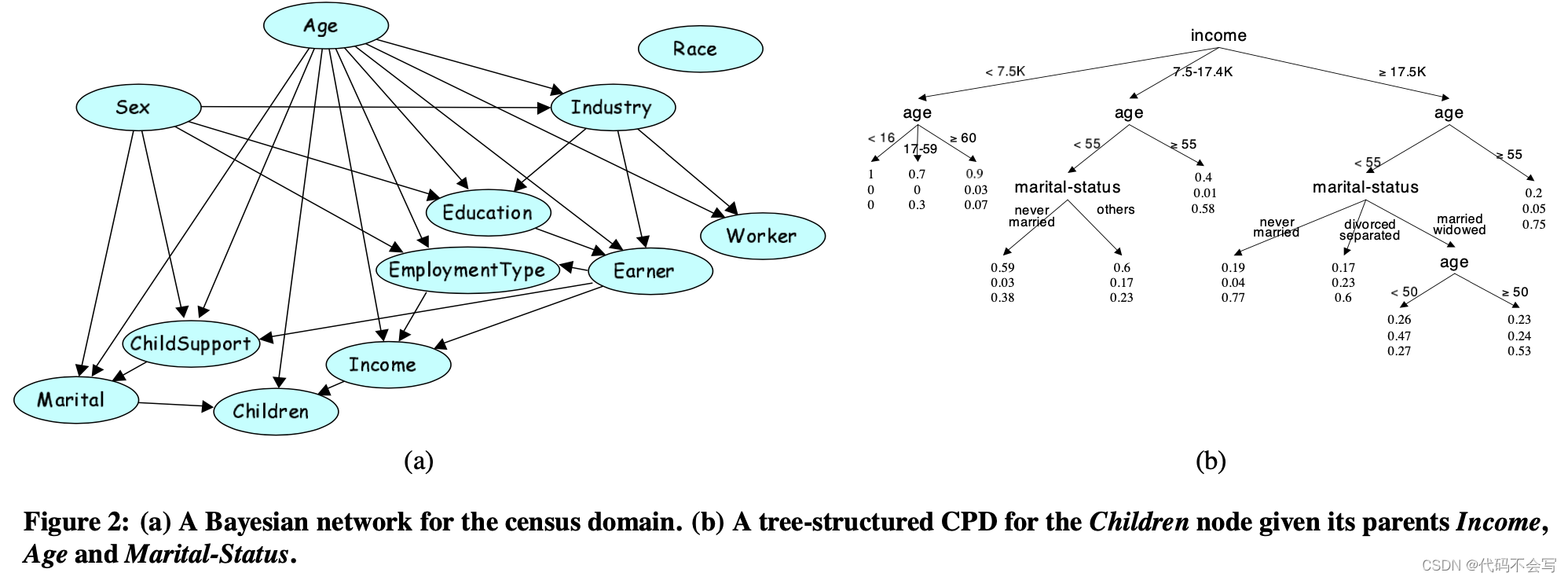
贝叶斯网络的第二个组件是每个节点和它的parents节点之间的统计关系statistical relationship。它由一个每个属性的条件概率分布(conditional probability distribution,CPD)Pβ( Ai | Parents(Ai) )组成,这个条件概率分布指定了在其parents的任意可能的赋值条件下的Ai分布。这个CPD可能会有多种表示方式。它可以表示为一个表,就像我们前面的例子一样。或者,它可能会表示为一棵树,其中内部顶点代表Ai的某个父结点的分割,叶子节点包含Ai值的分布。在这个表达式中,我们发现在通过沿着树中合适的路径达到叶子节点的方式,在给定其parents特定值Ak1=a1, ..., Akl = al的情况下,Ai的条件分布:当我们在某个变量桑遇到split时,我们沿着对应值aj的分支往下走;然后使用存储在叶子节点上的分布。Fig.2(a)中网络中的Children属性的CPD tree展示在Fig.2(b)中。这个属性的可能值为N/A,Yes和No。我们可以看到,例如,基于给定条件Income≥17.5K,Age<55和Marital-Status = nerver-married的Children的分布是(0.19,0.04,0.77);基于给定条件Income≥17.5K,Age<50和Marital-Status = married的Children的分布是(0.26,0.47,0.27),这也是给定条件Income≥17.5K,Age<50和Marital-Status = widowed的分布:这两个实例化会导致相同的诱导路径。
和BN β相关的条件独立假设,以及和节点相关的CPD,一起通过链式法则唯一确定了属性上的联合概率分布:
这种形式与我们在2.1章中简单例子中使用公式2形式完全相似。因此,我们可以从紧凑的模型中恢复出联合分布,不需要明确地表示和存储联合概率分布。在我们上面的案例中,完全联合分布的元组数量大概在70亿,同时我们的BN中的参数数量是951-一个极大的缩小!
2.3 查询评估中的贝叶斯网络
我们的条件独立性断言对应于数据库表中联合分布的等式约束。当然,一般来说,这些等式很少完全成立。事实上,即使数据是由满足条件独立性(甚至无条件独立性)假设的分布中独立生成的随机样本生成的,从我们数据中的频率导出的分布也不会满足这些假设。然而,在许多情况下,我们可以很好地使用具有恰当数据结构的贝叶斯网络来逼近分布。我们推迟到第4节再讨论这个问题。
一个贝叶斯网络是一个完全联合分布的压缩表示。因此,它隐式地包含了对一组属性赋值概率的任何查询的答案。因此,如果我们构建一个逼近PD的贝叶斯网络BN β,我们可以很轻松地用它来估算基于relaiotn R的任意查询Q的PD(Q)。假设我们的查询Q有这样的格式:r.A = a(这里我们使用向量表示法来缩写多维选择)。然后我们可以计算: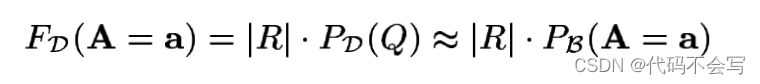
当然,生成完全联合分布Pβ的计算代价是非常昂贵的,并且在通常估计查询大小的运行时设置中几乎总是不可行的。因此,我们需要一个更高效的算法来计算Pβ(A=a)。尽管计算这个概率的问题在最坏的场景下是NP-hard,对于实际遇到的网络结构,BN推断通常是非常有效的。标准的BN推理算法[19]使用了特殊用途的基于图的算法,利用了网络的图形结构。这些算法的复杂性取决于与图的连通性相关的某些自然参数。对于大多数真实世界的模型,这些参数通常很小,这使得对具有数百个或更多节点的许多网络进行非常有效的推断[16,26]。
在本节的开始,我们做了几个假设。我们现在描述如何放宽这些假设。首先,我们假设我们只用等式谓词选择操作。通过计算属性赋值落在该范围内的概率,可以直接扩展我们刚才描述的计算一组属性赋值概率的技术来处理范围查询。我们简单地对满足范围限制的所有潜在赋值求和。。虽然乍一看,这可能听起来相当昂贵,但上面描述的BN推断算法可以很容易地适应计算这些值,而不增加任何计算复杂度。我们所做的第二个重要假设是,属性的域很小到中等大小。我们可以通过使用已开发的用于域值离散化的技术来解除对bn的这一限制[12,22]。在域值不是序数的情况下,我们可以使用特征层次结构(如果它们是可用的[9]),或者我们可以使用许多聚类算法中的任何一种。一旦我们在离散或抽象的属性值空间上构建了BN,我们现在必须修改查询估计技术,以提供对基本级别值上的查询的估计。这样做的一种方法是简单地计算抽象查询的选择性估计selectivity estimate,它将基本级别的值映射到适当的离散或抽象值,然后通过假设结果内的均匀分布来计算基本级别查询的估计。
三、Join选择性估计
在上一节中,我们将注意力限制在对单个表的查询上。在本章中,我们将方法扩展为处理多个表上的查询。我们只关注满足引用完整性的数据库:假设R是一个table,F是R中的一个外键,它指向一些table S的外键K上;对于每一个元组r∈R,必定会有一些元组s∈S满足r.F = s.K。通过本文,我们将注意力限定在外键join上-即按照r.F=s.K的方式执行的join。我们将使用术语keyjoin作为这种连接的简写。
3.1 两表Join
考虑一个医药数据库中的两个tables:Patient,包含TB数量的patients信息;和Contact,包括与病人有过接触的人,以及可能感染或不感染这种疾病的人。我们可能对回答涉及这两个表之间连接的查询感兴趣。例如,我们可能对以下查询感兴趣:“patient.Age = 60+ and contact.Patient = patient.Patient-ID and contact.Contype = roommate”,即查找所有60岁以上与室友有过接触的患者。
这个问题的一个简单方案可以按如下方式处理:根据引用完整性,Contact中的每个tuple一定会和Patient中的正好一个元组进行join。因此,join后relation的大小,在进行select之前,正好是|Contact|。然后我们再计算 patient.Age = 60+ 的概率p和contact.Contype = roommate的概率q,并推断出查询结果的大小为 |Contact| * p * q。
这种天真的方法在两个方面存在缺陷。首先,两个不同tables中的属性通常是相关的。一般来说,外键通常用于连接在语义上相关的不同表中的元组,因此通过外键连接相关的元组的属性通常是相关的。例如,患者的年龄与他们接触的类型之间有明显的相关性;事实上,有室友的老年患者非常罕见,这种天真的方法会高估他们的数量。第二,两个元组相互连接的概率也可以与各种属性相关。例如,中年病人通常比老年病人有更多的接触。因此,虽然在选择患者年龄之前,这两个表的连接大小是|Contact|,但患者超过60岁的连接元组的百分比低于患者表中全部超过60岁的患者的总百分比。
我们通过提供这两个表联合分布的更精确模型来解决这些问题。考虑两个tables R和S,其中R.F指向S.K。我们通过一个虚构的抽样过程在R和S之上定义一个联合概率空间,这个抽样过程会随机从R中抽样一个元组r,并独立第从S抽样一个元素s。这两个元组可能会,也可能不会互相join上。我们引入了一个新的连接指示符变量join indicator variable来对这个事件建模。这个变量,Jf,是一个二进制值,当r.F=s.K时它为true,否则为false。
采样过程引入了一个分布,基于连接指示符join indicator Jf,和值属性R.* = {A1, ..., An} 和S.* = B1, ..., Bn。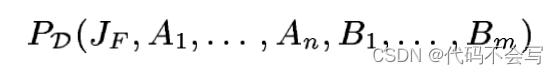
现在,考虑在R和S之上的一个select-keyjoin查询Q:r.A = a,s.B = b,r.F = s.K(我们用向量表示法来缩写多维选择)。我们可以很容易得出Q的结果大小为: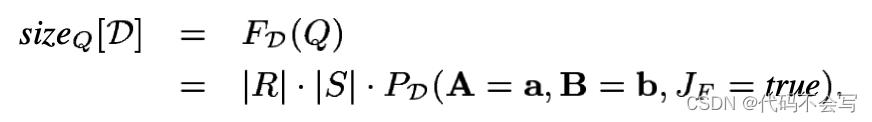
换句话说,我们可以使用抽样过程定义的联合分布来估计这种形式的任何查询的结果大小。正如我们现在展示的,第2节中技术的扩展允许我们使用概率图形模型来估计这个联合分布。
3.2 概率关系模型
概率关系模型(Probabilistic relational models, PRMs)扩展了贝叶斯网络到关系设置中。它们不仅允许我们对同一元组的属性之间的相关性建模,还允许我们对不同表中相关元组的属性之间的相关性建模。作为属性的父级R.A,这个扩展是通过允许具有外键的另一个关系S中的属性S.B来实现的 。我们还可以允许relation中属性的依赖通过一个更长的join链关联到R;为了简化符号,我们省略了描述。我们的TB域的PRM如图3(A)所示。例如,接触者的类型取决于患者的年龄age和性别gender。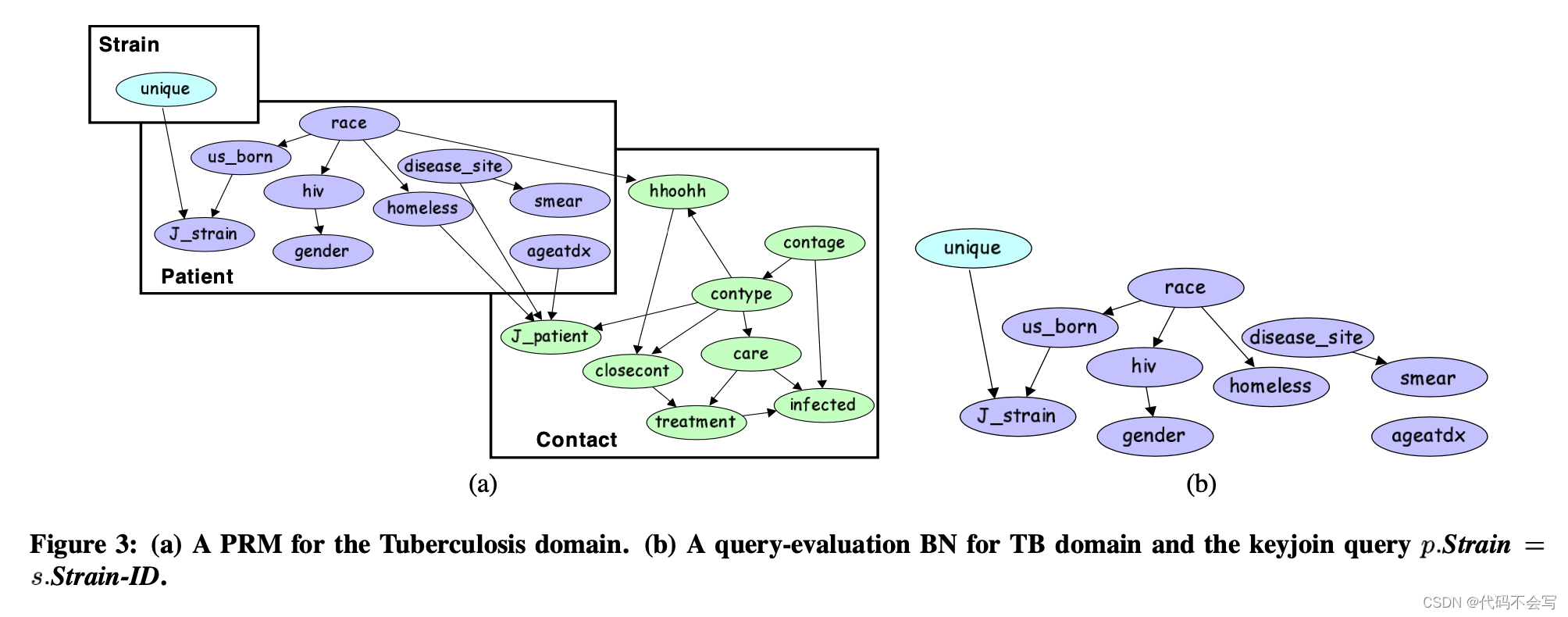
Definition 3.1:一个关系数据库的概率关系模型(PRM)是一个对(S, θ),它为下面的每一个变量都指定了一个local概率模型:
-
对每一个table R和每一个属性A∈R.*a的变量R.A
-
对于R到S的每一个外键F,一个布尔连接指示器变量R.Jf
对于每个R.X格式的变量:
-
S指定了一组parents Parents(R.X),其中每个parent都有这样的格式R.B或是R.F.B,其中F是R到某个表S中的外键,B是S的一个属性
-
θ指定了一个条件概率分布CPD P(R.X | Parents(R.X))
这个框架允许一个属性r.A概率依赖于一个属性s.B。这种依赖仅仅会在s通过一些外键依赖关联到r上时才有意义:我们的PRM对一个r和s独立随机选择的分布进行建模;它们的属性没有理由相互关联,除非它们之间有某种联系。因此,我们限制PRM模型仅仅在r.F=s.K时才允许r.A依赖于s.B。更准确来说,我们要求如果R.F.B是R.A的一个parent,那么R.Jf必须也是R的一个parent。我们同样要求R.A的条件概率分布CPD只针对R.Jf=true的场景定义;换句话说,在R.A的CPD树中,R.Jf是tree的根节点,并只会在R.Jf=true的场景下分叉。
注意连接指示符变量join indicator variable同样有parents和一个CPD。考虑我们TB域的PRM。连接指示符变量Patient.Jstrain的parents有Patient.USBorn和Strain.Unique,它说明了strain(毒株)在人群中是独一无二的,还是在多个patient中出现中。基本上有三种情况:对于一个非独特的strain和一个出生在US之外的patient,join的概率是0.001;对于一个非独特的strain和一个出生在US的patient,概率是0.0029,几乎是前者的3倍;对于一个独特的strain,不考虑patient的出生地,概率是0.004。因此,与在外国出生的patient相比,我们更有可能让美国出生的patient join非独特strain。 (原因是外国出生的患者经常移民到美国,他们已经感染了这种疾病;这些患者通常具有他们所在地区的独特菌株。另一方面,美国出生的患者更有可能感染这种疾病通过从当地人那里捕获它,因此会出现在感染群中。)
3.3 使用PRMs的选择性估计
现在我们希望描述PRM模型和数据库之间的关系。在贝叶斯网络BNs的案例中,连接是直连的:BD βr是一个对频率分布Pd的近似。在PRMs中,这个问题更加微妙,由于PRM没有独立描述一个单表的分布。一个属相的概率分布可以依赖于在其他由外键关联的元组中的属性。因此我们需要去定义一个元组的概率分布,带有它所依赖的所有元组。为了保证我们必须考虑的元组集合是有限的,我们对PRM模型设置了分层限制。
Definition 3.2:假设![]() 是我们数据库中表上的一个部分排序。我们说一个关联到S上的外键R.F是和
是我们数据库中表上的一个部分排序。我们说一个关联到S上的外键R.F是和![]() 一致的,如果S
一致的,如果S![]() R。一个PRM是(table)分层的,如果存在一个部分排序
R。一个PRM是(table)分层的,如果存在一个部分排序![]() ,只要R.F.B是一些R.A的parent(其中F是到S的一个外键),就满足S
,只要R.F.B是一些R.A的parent(其中F是到S的一个外键),就满足S![]() R。
R。
我们现在可以定义一个查询Q的最小扩展。让Q作为一个在元组变量r1,...,rk上的keyjoin查询(可能或可能不会来源于同样的tables)。
Definition 3.3:假设Q是一个keyjoin查询,我们定义upward closure Q+,使Q成为满足以下两个条件的最小查询:
-
Q+包含Q中所有的join操作
-
对于每一个r,如果存在一个属性R.A和其parent R.F.B,其中R.F指向S,那么在Q+中有一个唯一的元组变量s,其中Q+包含连接r.F=s.K
我们可以为任何查询构造upward closure,并且这个集合是有限的。例如,在TB域中的查询Q是针对来自Contact表中的一个元组变量c的,那么Q+就是基于三个元组变量c,p,s之上的,其中p是Patient中的元组变量,s是Strain中的元组变量。注意,Contact中的属性和Strain中的属性没有直接依赖关系,但是对Patient有依赖关系,元组变量p的引入反过来也需要元组变量s的引入。注意,如果我们考虑一个已经包含一个约束为c.Patient =p.Patient-ID的元组变量p的keyjoin查询Q',那么Q'和Q的闭包是等价的;即,如果已经存在一个相应的元组变量,进程将不会引入一个新的元组变量。我们可以以一种显而易见的方式将向上闭包的定义扩展为select-keyjoin查询:select子句与向上闭包的概念无关。
向上闭包的查询不会改变结果大小:
Proposition 3.4:假设Q为查询,Q+为它的upward closure,那么sizeQ[D] = sizeQ+[D]。
这个结果直接来源于引用完整性。
假设Q为keyjoin查询,Q+是它的upward closure。假设r1, ..., rk是Q+中的元组变量。假设Pd(r1, ..., rk)是通过对每个元组r1, ..., rk进行独立采样获取的分布。那么针对任意扩展Q+的查询Q',PRM允许我们来近似![]()
,准确地来说是估计查询选择性所需的数量。我们可以使用下面简单的构造方法来计算PRM股计算:
Definition 3.5:假设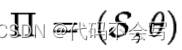
是D上的一个PRM,Q为一个keyjoin查询。我们将查询-评估贝叶斯网络![]()
定义为一个BN,如下所示:
-
Q+中对每一个r∈Q+和属性A∈R.*都有一个节点r.A,同样对于每一个条件r.F=s.K都有一个节点r.Jf
-
对于每一个变量r.X,节点r.X在S都有对应指定的parents Parents(r.X):如果R.B是R.A的parent,那么r.B就是r.A的parent;如果R.F.B是R.A的一个parent,那么s.B就是r.A的一个parent。其中s是Q+符合条件r.F=s.K中的唯一元组变量。
-
r.X的CPD被定义为θ
举例,Fig.3(b)中展示了对于upwardly closed keyjoin查询p.Strain=s.Strain-ID的查询评估BN。
现在我们可以使用贝叶斯网络来为任意查询估计选择绿了。考虑一个扩展了keyjoin查询Q的select-keyjoin查询Q'。我们可以通过计算![]()
来确定Pd(Q')。例如,为了评估查询p.Age=60+,我们可以使用Fig.3(b)(和它的upward closure p)中的BN,并且计算(p.Age = 60+, p.Strain = s.Strain-ID)的概率。实际上,我们不需要在闭包Q+中的所有节点上构造BN;只包括查询到的属性和它们在![]()
中的祖先节点就足够了 。
四、PRM构建
前两节展示了一旦有了捕获数据分布中显著统计相关性的PRM,我们如何执行查询大小估计。本章则关注如何从关系数据库中自动构建这样一个模型的问题。本节中的许多想法都是对之前关于该主题的工作的简单改写:从数据(如[15])学习贝叶斯网络的工作,以及最近将该学习框架扩展到PRMs [11]。
构造算法的输入由两部分组成:关系schema,它指定域中的基本词汇表——表的集合、与每个表相关的属性,以及元组之间可能的外键连接;以及数据库本身,它指定每个表中包含的实际元组。
在构造算法中,我们的目标是找到一个PRM(S,θ)。这最好地代表了数据中的依赖性。为了为这项任务提供一个正式的规范,我们首先需要定义一个适当的“best”概念。给定这个准则,算法将试图找到优化它的模型。我们的优化问题有两个部分。参数估计问题parameter estimation problem为给定的依赖结构S寻找最佳参数集θ。结构选择问题structure selection problem是在我们对模型的空间约束下,找到参数选择最优、得分最大的依赖结构。
4.1 评分标准
为了提供模型质量的正式定义,我们利用信息论中的基本概念。模型的质量可以通过它对数据的总结程度来衡量。换句话说,如果我们有了模型,使用最佳编码,需要多少位来表示数据。模型提供的信息越多,编码数据所需的比特就越少。
众所周知,给定模型的数据集的最优香农编码使用的比特数是给定模型的数据概率的负对数。换句话来说,我们使用如下的类log函数来定义一个模型(S, θ)的分数:
因此,我们可以将模型构建任务表述为找到给定数据的具有最大对数似然性的模型。
我们注意到这一准则不同于从数据中学习概率模型的标准公式。在后者中,我们通常选择一个评分函数,以权衡数据与模型复杂性的匹配程度。这种折衷使我们能够避免过于紧密地拟合训练数据,从而降低我们预测不可见数据的能力。在本例中,我们的目标非常不同:我们不想泛化到新数据,而只是总结现有数据中的模式。关注差异是如何激发我们对于评分函数的选择。
4.2 参数估计
我们首先考虑给定依赖结构的参数估计任务。换句话说,在选择了确定每个属性的父属性集的依赖结构S之后,我们必须“填写”参数化它的数字θ。参数估计任务是结构选择步骤中的一个关键子程序:为了评估一个结构的分数,我们必须首先对其进行参数化。也就是说,得分最高的模型就是最佳参数化得分最高的结构。
众所周知,给定结构S的最高似然参数化是精确匹配数据中的频率的参数化。更确切地来说,考虑在table R中的一些属性A,并让X成为A在S中的parents。我们的模型对A中的每一个值a和X的每一个赋值x,都包含一个参数θa|x。这个参数代表了条件概率P(R.A=a | X=x)。这个参数的最大似然值只是R.A=a在全部X=x场景下的相对频率。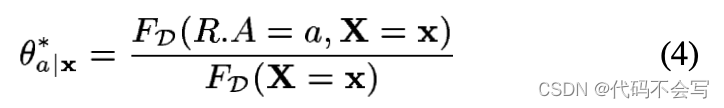
在这个表达式中使用的这个频率,或是计数,在统计学习文献中被称为充分统计sufficient statistics。
如果属性和它的父属性在同一个表中,这种计算是非常简单的。例如,为了在我们的TB模型中计算和Patient.Gender相关的CPD,我们简单地对Gender和HIV执行一个计数count和分组查询group-by query,它为我们提供了这两个属性的所有可能值的计数。这些计数立即为我们提供了整个CPD分子和分母的充分统计数据。这种计算需要对数据进行线性扫描。
一个属性的一些父属性出现在不同表中的情况稍微复杂一些。回想一下,我们将元组之间的依赖关系限制为使用外键连接的关系。换句话说,我们只有在r.F=s.K,且F是R中的一个外键同时是S中的主键时,才能有r.A依赖于s.B的关系。
因此,为了计算依赖于S.B的R.A的CPD,我们只需要在R和S之间执行一个foreign-key join,并在结果集上使用同样的计数count和分组查询group-by query。例如,在我们的TB模型中,Contact.Age的parent有Contact.Contype和Contact.Patient.Age。为了计算完全统计,我们只需要将Patient和Contact以Patient.Patient-ID=Contact.Patient进行join,然后适当地执行groupby和count。
我们对R.A仅依赖于单一“foreign”属性S.B的情况进行了分析。但是,讨论显然扩展到了对多个属性的依赖关系,可能存在于不同的表中。我们只需要做所有必要的foreign-key joins,对R.A和它的所有parents X生成一个结果表,并计算完全统计。
虽然这个过程乍一看可能很昂贵,但它可以非常高效地执行。回想一下,我们只允许通过外键连接进行依赖。将这个限制与我们的引用完整性假设放在一起,我们知道每个元组r将精确地与单个元组s连接。因此,结果连接中的元组数量正好是R的大小。当多个表中有父表时,同样的观察结果也成立。假设我们在键上有一个很好的索引结构(例如哈希索引),那么执行连接操作的成本是线性的。
现在我们还需要描述对于一个连接指示符变量join indicator variable Jf的CPD计算。在这个场景下,我们必须从R随机选择一个元组和从S中随机选择一个元组s,它们满足r.F=s.K的概率。join时间的概率依赖于r和s中的属性值,例如,r.A和s.B的值。在我们的TB域内,Patient和Strain的join indicator依赖于Patient表中的USBorn和Strain表中的Unique。为了计算P(Jf | r.A, s.B)的完全统计,我们需要计算r.A=a, s.B=b的所有场景的数量,以及在r.F=s.K条件下的总数。幸运的是,这个计算同样也很简单。第一个值是Fd(R.A=a) * Fd(S.B=b)。后者是Fd(R.A=a, S.B=b, R.F=S.K),可以通过将两个表进行join,然后执行count和group-by query实现。这个操作的cost(假设有合适的索引结构)同样也是R和S中元组数量的线性值。
4.3 结构选择
我们的第二个任务是结构选择任务:找到达到最高log似然分数的依赖结构。这里的问题是在超指数级的众多可能的依赖结构中找到最佳的依赖结构。这是一个组合优化问题,已知是NP-hard。因此,我们提供了一个算法,使用简单的启发式技术找到一个良好的依赖结构;尽管不能保证产生最优的依赖结构,但该算法在实际应用中表现良好。
4.3.1 评分审视
对数似然函数可以以一种既有利于模型选择任务,又使其效果更容易理解的方式重新表述。我们首先需要以下基本定义:
Definition 4.1:假设Y和Z是两个属性集合,考虑在它们的并集之上的一些联合分布P。我们可以定义Y和Z相对于P的互信息为: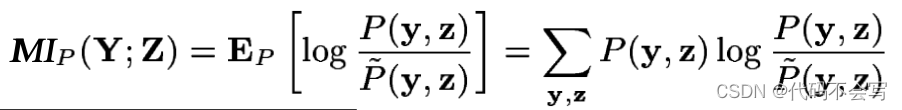

期望Ep中的元素是P(y,z)和一个是的y和z互相独立的近似值![]()
之间的相对误差的对数,但维护了每一个的概率。整个表达式只是一个分布相对误差的加权平均值,其中权重是事件y,z的概率。直觉上很清楚,互信息是衡量Y和Z在P中的相关程度。如果它们是独立的,那么互信息为零。否则,互信息总是正的。相关性越强,互信息就越大。
考虑一个特定的结构S。我们在前一节中的分析指定了S的参数化的最佳选择(根据可能性)。我们用θs来表示这组参数。让Pd表示数据库中的分布,如上所示。我们现在可以根据互信息来改革对数似然分数: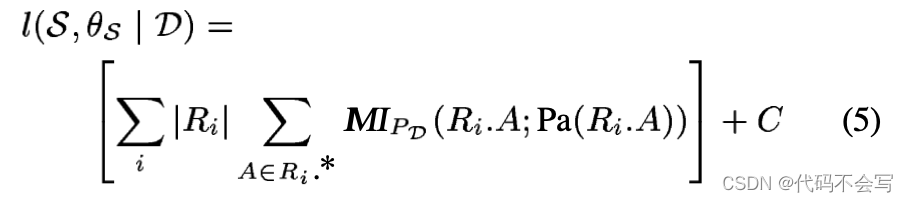
其中C是一个常量,它不依赖于结构的选择。因此,一个结构的总得分被分解为一个总和,其中每个成员都是属性及其父属性的局部值。局部分数直接依赖于结构中一个节点和它的parents的互信息。因此,我们的评分函数会更倾向于和其parents强相关的属性。我们使用scorel(S:D)来代表l(S, θs|D)。
4.3.2 模型空间
一个重要的设计决策是我们允许算法考虑的依赖结构的空间。模型的语义对我们施加了几个约束。贝叶斯网络和PRMs只在依赖结构是非循环的情况下定义一个相干的概率分布,也就是说,从属性到它本身不存在有向路径。因此,我们把注意力限制在有向无环图的依赖结构上。此外,我们对表间依赖项提出了一定的要求:只有当S.K是R中的一个外键,并且连接指示器变量Jf也是R.A的父变量,并且在CPD树中扮演适当的角色时,才允许R.A依赖于S.B。最后,我们要求将依赖关系结构按表分层,如上所述。
计算考虑隐含了第二组约束。数据库系统通常会对用于指定统计模型的空间量设置一个界限。因此,我们对由我们的算法构造的模型的大小设置了一个界限。在我们的示例中,大小通常是CPDs中用于不同属性的参数数量,加上指定结构所需的少量参数。第二个计算方面的考虑是为构造结构中CPDs而构造的中间group-by表的大小。如果这些表变得非常大,存储和操作它们的成本可能会很高。因此,我们通常选择为每个节点的父节点数量设置一个界限。
4.3.3 搜索算法
给定一组合法的候选结构,以及一个允许我们评估不同结构的评分函数,我们只需要提供一个在我们的空间中寻找高分假设的程序。最简单的启发式搜索算法是贪婪爬坡搜索greedy hill-climbing search,使用随机步长来逃避局部极大值。我们保持我们当前的候选结构S,并不断改进它。在每次迭代中,我们考虑对该结构的一组简单的局部转换。对于每个产生的候选后继者S',我们检查它是否满足我们的约束条件,并选择最好的一个。我们将注意力限制在简单的转换上,例如添加或删除一条边,以及添加或删除CPD树中的一条分叉。这个过程一直持续到所有可能的后继结构S'的分数都不高于S。此时,算法可以采取一些随机步骤,然后恢复爬坡过程。在这种形式的一些迭代之后,算法停止并输出在整个过程中发现的最佳结构。
一个需要考虑的重要问题是如何在给定结构S的可能继任者结构S'中进行选择。最显而易见的方法是简单地选择提供最大score改进的S',即最大化
![]()
![]()
。然而,这个方法是非常目光短浅的,因为它忽略了在增加结构数量方面的转换成本。我们现在提出一个新的方法来解决这个问题。
第一种方法是基于这个问题和加权背包问题之间的类比:我们有一组物品,每个物品都有一个值和一个体积,还有一个背包有一个固定的体积;我们的目标是选择适合背包的物品的最大价值集。我们的目标非常相似:我们引入模型的每条边都有一定的分数价值和一定的空间成本。背包问题的一个标准启发式方法是贪婪地将物品添加到背包中,不是最大价值,而是最大价值与体积比。在我们的例子中,我们可以类似地选择通过额外空间要求对其似然改进进行归一化的边,要求其值最大化:
我们将这种评分方法称为存储大小规范化(SSN)。
第二种方法是使用一种名为MDL(最小描述长度)的方法对数似然评分函数进行修改。这个评分函数是由信息和编码理论的思想驱动的。它不仅对给定模型的数据进行编码所需的位数取反,还使用对模型本身进行编码所需的位数对模型进行评分。这个分数的形式是: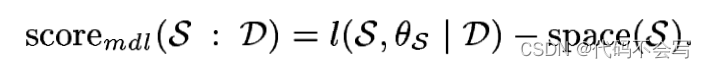
我们定义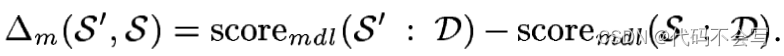
我们已经实验性地将原始的方法与上文两种想法在2.2节中的Census dataset进行了比较。在一个固定数量的空间下,SSN和MDL评分都比原始方法获得了更高的对数似然分数。事实上,SSN和MDL在整个分配空间范围内的表现几乎相同,没有明显的赢家。
这三种方法都包含了对于![]()
的计算。4.3.1小节中的公式5为提高该计算的效率提供了一个重要的思路。如我们所见,分数分解为一个和,每个和只与结构中的节点及其父节点相关联。因此,如果我们只修改单个属性的父集或CPD,则分数中对应于其他属性的项保持不变[15]。因此,要计算一个稍微修改过的结构对应的分数,我们只需要为一个依赖模型已经改变的属性重新计算本地分数。进一步,在完成搜索中的一个step后,前面迭代中的大部分工作都可以复用。
为了理解这个思想,假设当前的结构是S。为了执行搜索,我们评估了一些列对S的改动,并选择了能够给我们最大提升的一个。假设我们选择了为R.A(它的父集或是它的CPD树)更新本地模型。得到的结构是S'。现在,我们正在考虑S'可能的局部改变。关键是,与另一个属性S.B对应的分数组件没有改变。因此,对S.B的更改所导致的分数变化在S和S'中是相同的,我们可以简单地重用这个数字,而不改变。只有更改需要在移动到之后重新评估。
五、实验结果
略
六、总结
在本文中,我们提出了一种利用概率图模型估计查询选择性的新方法——贝叶斯网络及其关系扩展。我们的方法利用概率图模型,它利用表中不同属性之间的条件独立关系,以允许在属性值上对数据库的联合分布进行紧凑表示。我们已经在多个领域(医疗、金融和社会)的几个真实数据库上测试了我们的算法。我们的方法在所有这些数据集上的成功表明,我们的方法所利用的结构类型是非常常见的,而且我们的方法对于许多现实世界的数据库是可行的选择。
我们的方法有几个重要的优点。据我们所知,它在单一统一框架中处理select和join操作符的能力是独一无二的,从而为涉及多个select和join操作的复杂查询提供估计。第二,我们的方法规避了与多维直方图相关的维度问题。多维直方图,随着表的维度增长,要么增长得很明显,要么变得越来越不准确。我们的方法利用一组低维条件分布来估计高维联合分布,每个条件分布都有很高的精确度。正如我们看到的,我们可以把这些条件分布放在一起来得到整个联合分布的一个很好的近似。因此,我们的模型不局限于回答恰好出现在一个直方图中的一小组预定属性的查询;它可以用于回答对数据库中任意一组属性的查询。
在这篇论文中,有几个重要的主题我们还没有充分阐述。一种是在数据库更改时对PRM进行增量维护。可以直接扩展我们的方法,随时间调整PRM的参数,保持结构固定。为了调整结构,我们可以应用[13]方法的变体。我们还可以跟踪模型的分数,如果分数急剧下降,我们可以重新学习结构。
我们还没有讨论的另一个重要主题是非键属性上的连接。在我们的演示和实验中,查询只使用外键连接。虽然这类查询从我们提出的概率模型中受益最大,但我们的方法更一般化。我们可以通过对连接属性的可能值求和来计算连接非键属性的查询的估计值,而且我们的估计值可能比不为元组之间的任何依赖关系建模的方法更准确。然而,需要进行实证调查来评估我们对这类查询的方法。
我们的方法有许多有趣的扩展,我们打算在未来的工作中进行研究。首先,我们希望扩展我们的技术来处理更大的数据库;我们相信,对数据的一次初始传递可以用于“归位”在一个更小的候选模型集上,然后可以在批处理模式中非常有效地计算出足够的统计数据。更有趣的是,我们的技术在近似查询回答任务中有明显的应用,包括OLAP查询和一般数据库查询(甚至涉及连接的查询)。
致谢我们要感谢Chris Olsten和Vishy Poosala的有用反馈。这项工作得到了DARPA HPKB项目下ONR合同N66001-97-C-8554的支持,并得到了斯隆基金会和鲍威尔基金会的慷慨资助。
这篇关于(论文阅读-优化器)Selectivity Estimation using Probabilistic Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





