presto专题

presto ,hive 区别
Presto是由Facebook开发的,是一个运行在多台服务器上的分布式查询引擎,本身并不存储数据,但是可以接入多种数据源(Hive、Oracle、MySql、Kafka、Redis等),并且支持跨数据源的级联查询,比如: select * from a join b where a.id=b.id;,其中表a可以来自Hive,表b可以来自Mysql。 优势(相对于Hive): Presto是一

Presto:Facebook的分布式SQL查询引擎
背景 Facebook是一家数据驱动的公司。 数据处理和分析是Facebook为10亿多活跃用户开发和交付产品的核心所在。 我门拥有世界上最大的数据仓库之一,存储了大约 300PB 以上的数据。 这些数据被一系列不同种类的程序所使用, 包括传统的数据批处理程序、基于图论的数据分析[1]、机器学习、和实时性的数据分析。 分析人员、数据科学家和工程师需要处理数据、分析数据、不断地
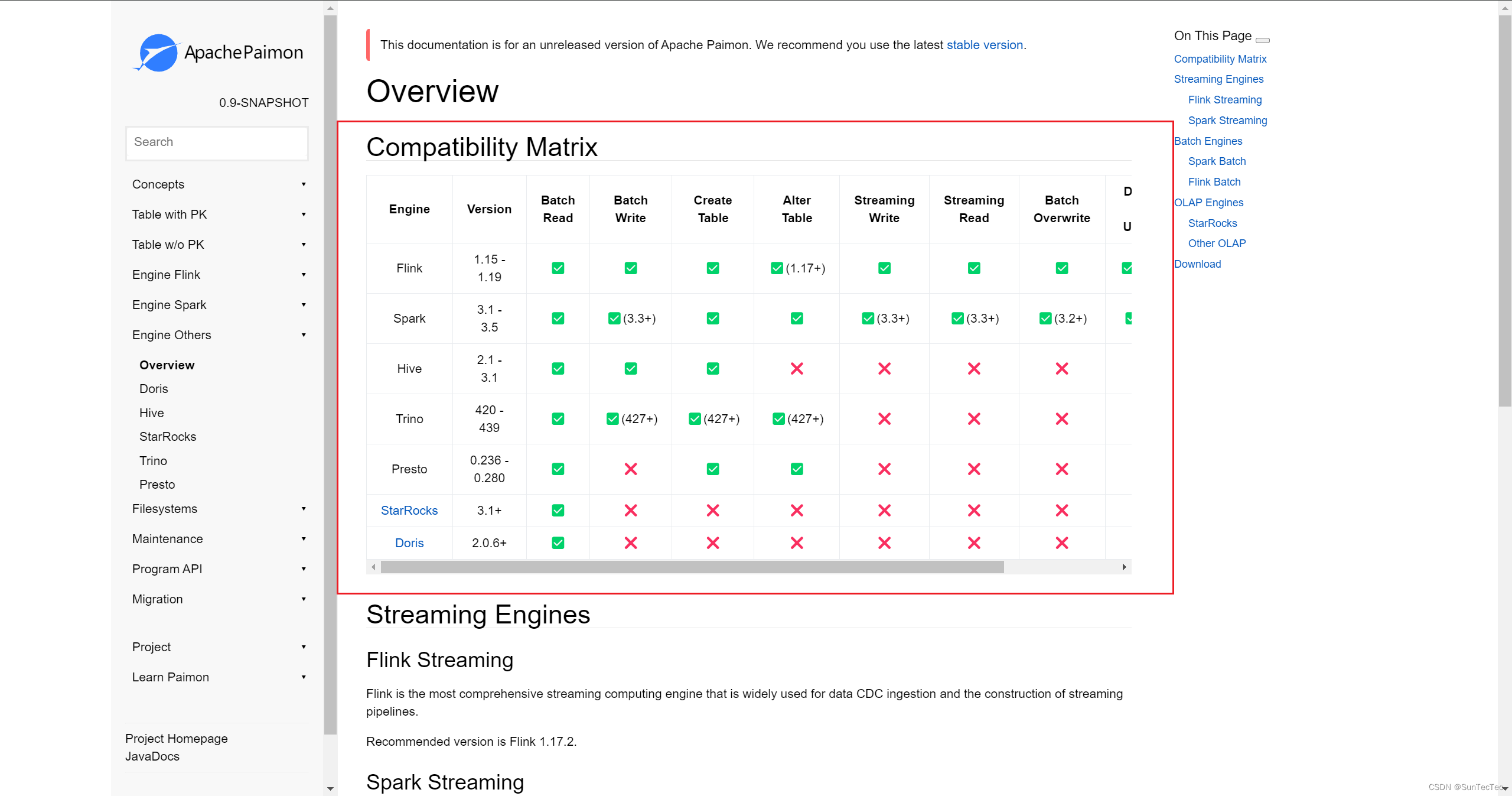
Paimon Trino Presto的关系 分布式查询引擎
Paimon支持的引擎兼容性矩阵: Trino 是 Presto 同项目的不同版本,是原Faceboo Presto创始人团队核心开发和维护人员分离出来后开发和维护的分支,Trino基于Presto,目前 Trino 和 Presto 都仍在继续开发和维护。 参考:

DataGrip 连接 presto数据库
最近项目中有用到presto数据库了,为了方便的操作presto,想要通过安装插件的方式用DataGrip连接presto(毕竟DataGrip这位老朋友用起来是如此顺手)。 1、下载presto jcdc连接jar包(https://prestodb.io/download.html) 2、打开老朋友(DataGrip),添加自定义的 Driver 选择刚才下载的JAR文件
Hive、Presto、PostgroSQL 时区、日期、时间转换(昨天、周)
UTC转GMT+0800(东八区) select from_utc_timestamp(cast(regexp_replace(regexp_replace('2019-07-12T09:01:59.056Z','T',' '),'Z','') as timestamp),"GMT+0800") 【重点在于】: from_utc_timestamp(‘1970-01-01 08:00:00’,
[喵咪大数据]Presto查询引擎
如果大家正在按照笔者的教程尝试使用大数据组件还是之前有使用过相关的组件,大家会发现一个问题HIVE在负责的查询下调用Mapreduce会很慢,在这个场景下就涌现出很多查询引擎来优化,比如大家熟悉的Spark-SQL,Impala,kilin已经今天的主角Presto, Presto以速度和极强的扩展性取得了胜利,不仅能够提高对HIVE数据查询速度还能和异构数据库进行关联查询,比如HIVE和My
Scroll生态项目Penpad,再获Presto Labs的投资
Penpad是Scroll生态的LaunchPad平台,其整计划像收益聚合器以及RWA等功能于一体的综合性Web3平台拓展,该平台在近期频获资本市场关注,并获得了多个知名投资者/投资机构的支持。 截止到本文发布前,Penpad已经获得了包括Scroll联合创始人Sandy Peng、知名加密投资机构Gate Labs、Animoca Brands的投资,并获得了这些投资伙伴的诸多市场资源倾斜
Penpad再获 Presto Labs 投资,Scroll 生态持续扩张
Penpad 是 Scroll 生态的 LaunchPad 平台,其整计划像收益聚合器以及 RWA 等功能于一体的综合性 Web3 平台拓展,该平台在近期频获资本市场关注,并获得了多个知名投资者/投资机构的支持。 截止到本文发布前,Penpad 已经获得了包括 Scroll 联合创始人 Sandy Peng、知名加密投资机构 Gate Labs、 Animoca Brands 的投资,并获

Presto 来自Facebook的开源分布式查询引擎
Presto是一个分布式SQL查询引擎, 它被设计为用来专门进行高速、实时的数据分析。它支持标准的ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。下图中展现了简化的Presto系统架构。客户端(client)将SQL查询发送到Presto的协调员 (coordinator)。协调员会进行语法检查、分析和规划查询计划。
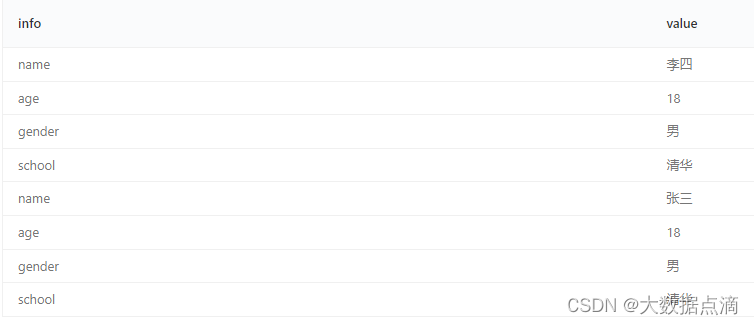
列转行(spark 与presto语法)
一、Presto 语法 原始数据: 期望数据: 代码: SELECT info, valueFROM ( select '张三' as name,'18' as age,'男' as gender,'清华' as schoolunion allselect '李四' as name,'18' as age,'男' as gender,'清华' as school) as

Presto 下载安装部署
1.1 Presto 是什么 Presto(或 PrestoDB)是一种开源的分布式 SQL 查询引擎,设计之初用于对任何规模的数据进行快速分析查询。支持关系型数据【Mysql、PostgreSQL等】及非关系型数据库【Hadoop分布式文件系统(HDFS)、HBase、MongoDB等】。Presto的一大优点是:Presto 设计采用了存储抽象化思想,构建可插入的连接器,可在

Hive,Presto,Spark 共性
Hive、Presto 和 Spark 都是大数据处理工具,都属于大数据处理技术栈,都需要集群环境支持,都可以进行数据处理和分析。 都可以进行数据处理:Hive、Presto、Spark 都可以用 SQL 语句进行数据处理,也可以用它们的语言(Hive 的 HQL、Presto 的 SQL、Spark 的 Scala/Java/Python)进行复杂的数据处理。 都需要集群环境:Hive、P
Presto Player 2.0 – 引人入胜的视频播放列表
Presto Player 2.0 引入了一项令人惊叹的新功能:视频播放列表。 将其与类似 Netflix 的新体验相结合,您将发现一款流畅的视频播放器,其功能在市场上任何其他工具中都找不到。 让我们看看 Presto Player 2.0 如何将您的内容提升到新的参与度! 目录 隐藏 Presto Player 2.0 有哪些新增功能? 美丽的播放列表 开始使用 Presto P

面经:Presto/Trino高性能SQL查询引擎解析
作为一名专注于大数据技术的博主,我深知Presto(现更名为Trino)作为一款高性能SQL查询引擎,在现代数据栈中的重要地位。本文将结合我个人的面试经历,深入剖析Trino的核心特性和应用场景,分享面试必备知识点,并通过代码示例进一步加深理解,助您在求职过程中游刃有余地应对与Trino相关的技术考察。 一、面试经验分享 在与Trino相关的面试中,我发现以下几个主题是面试官最常关注的:
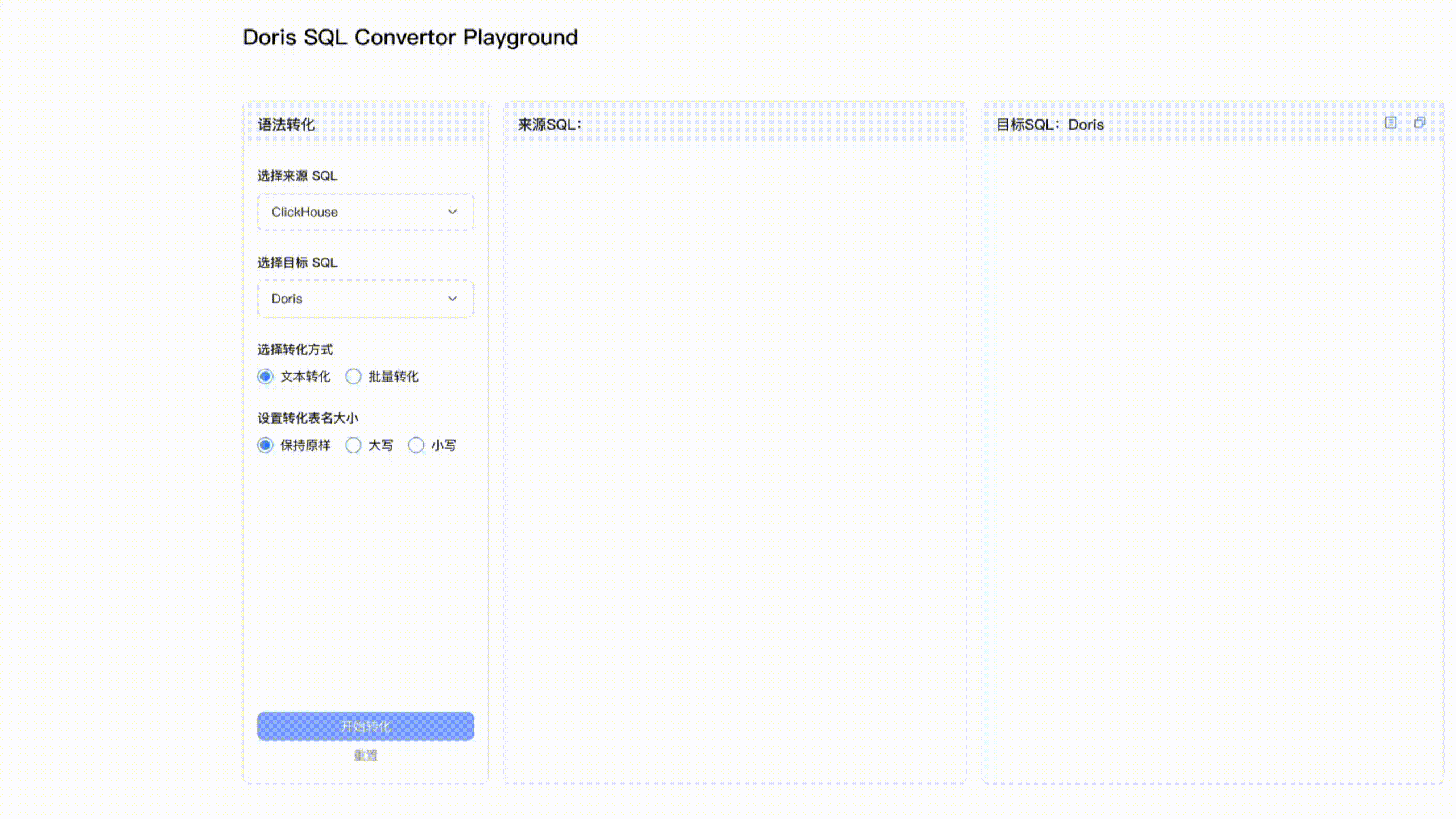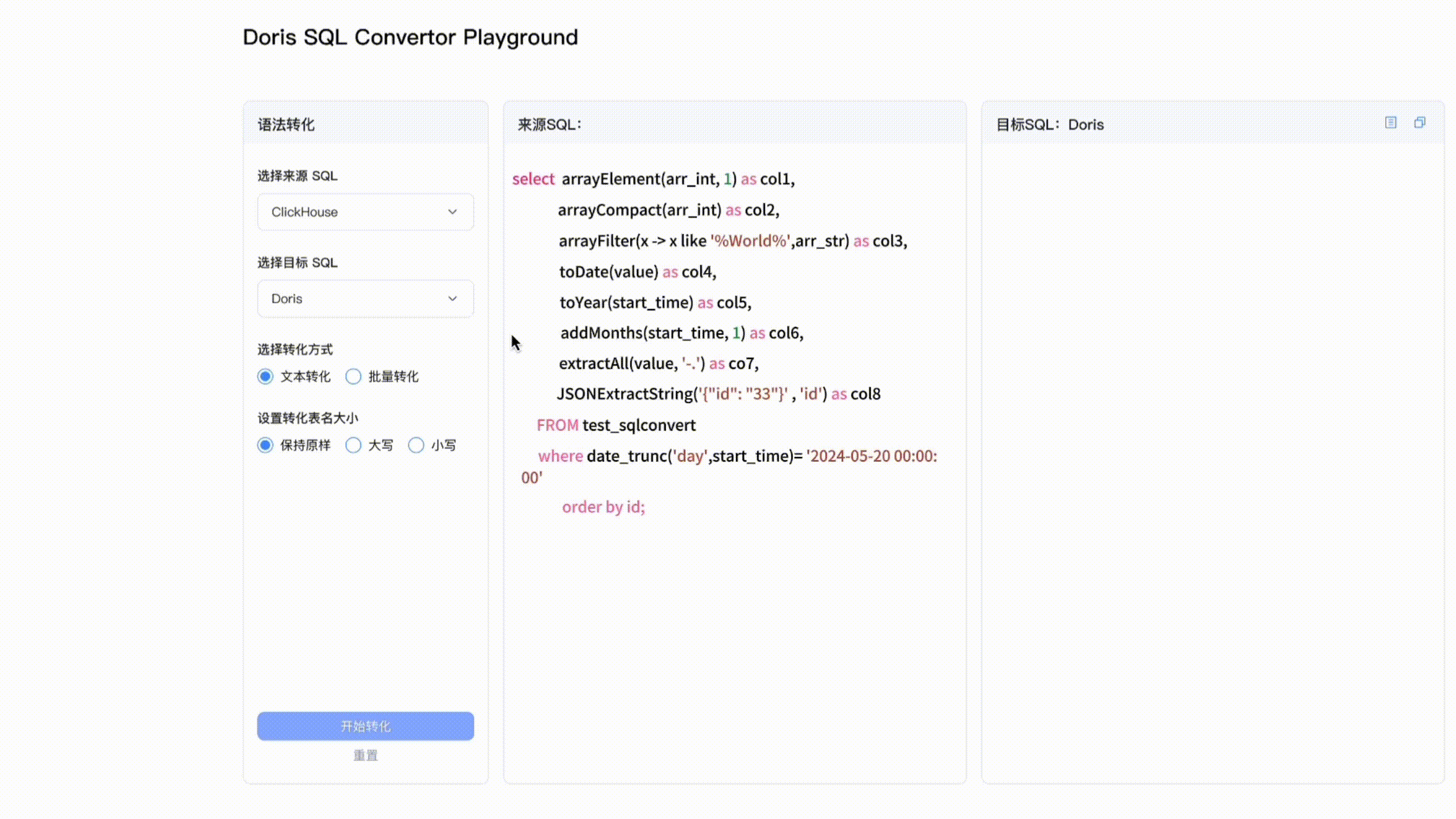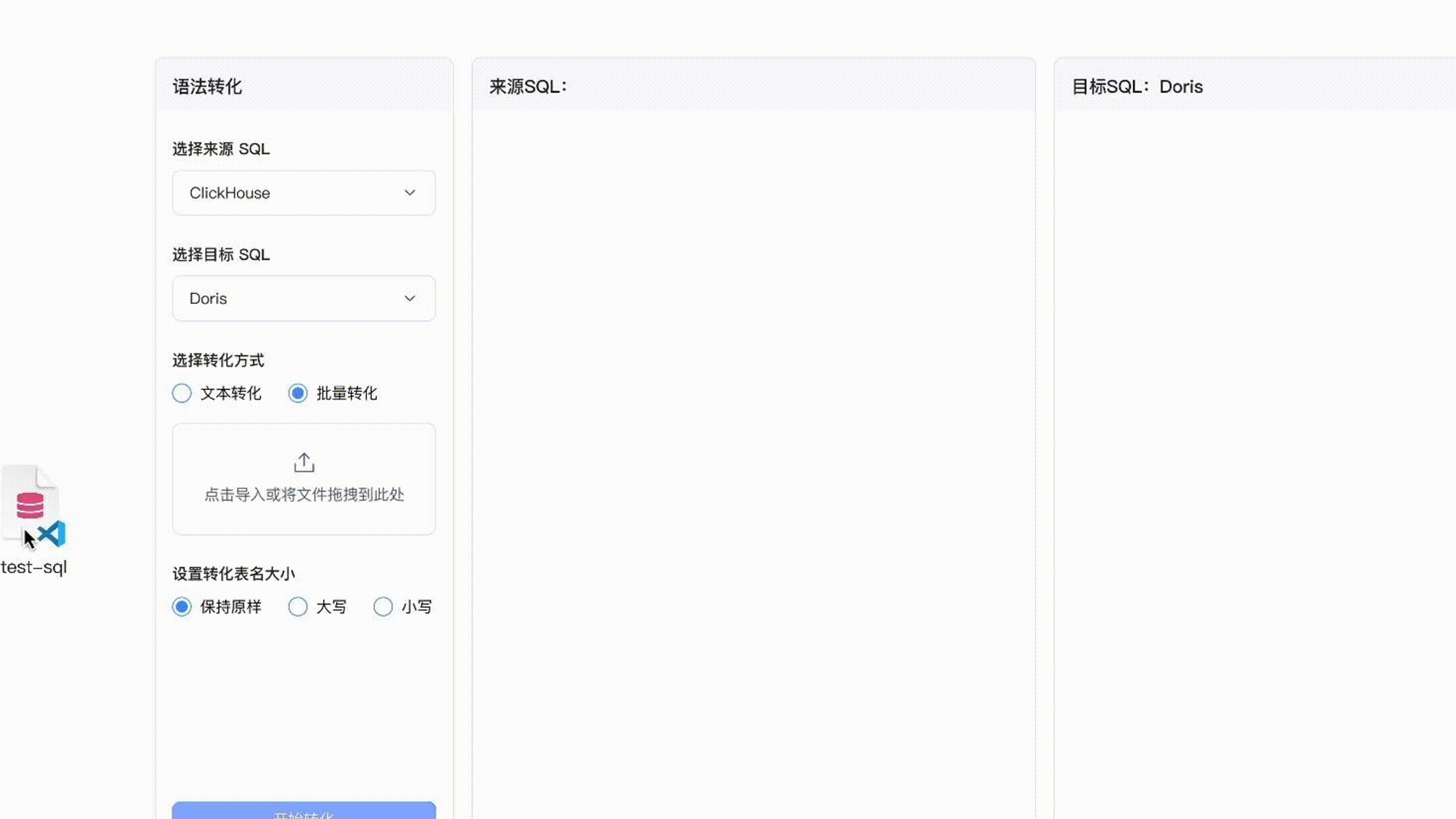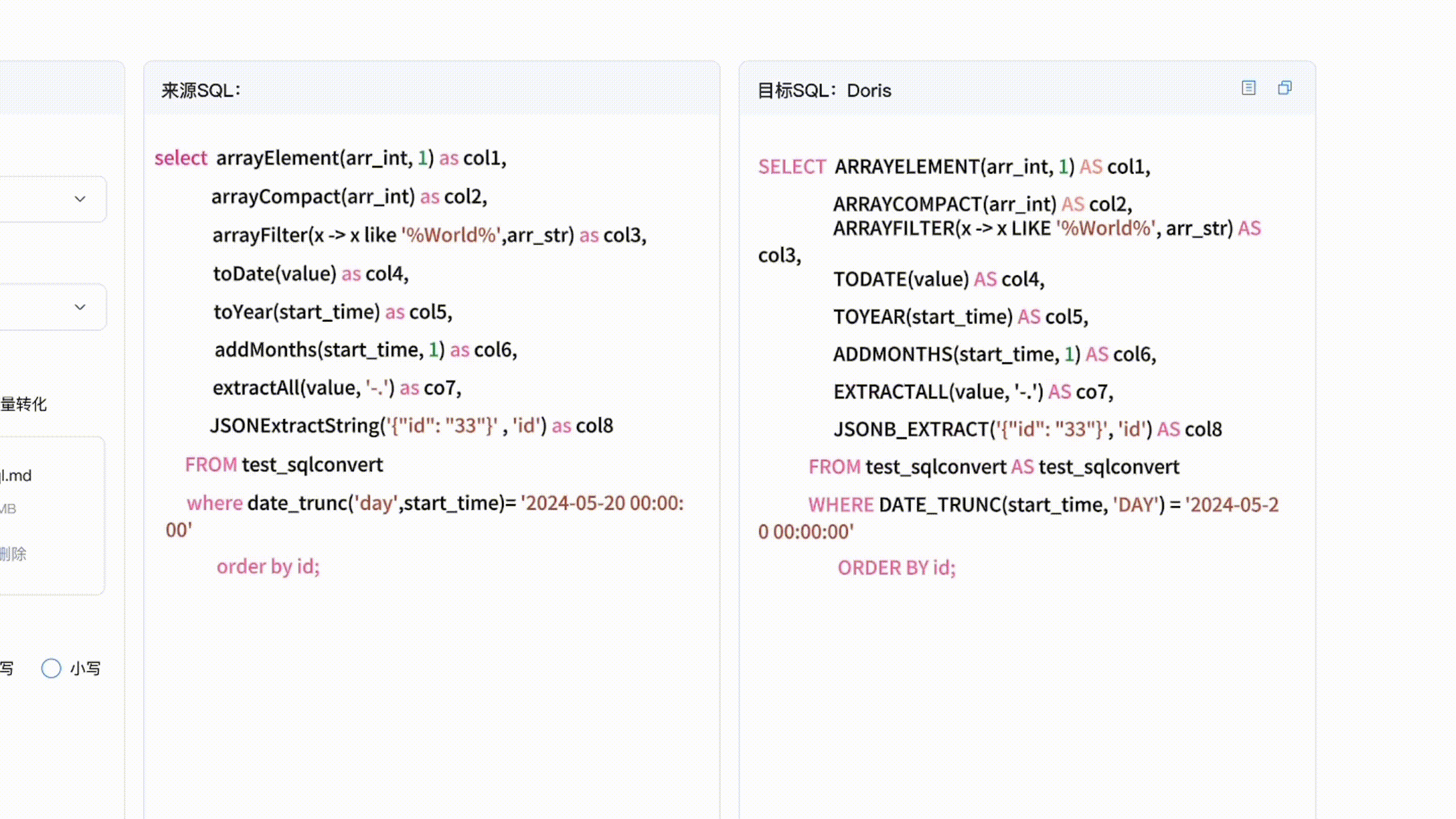
兼容 Presto、Trino、ClickHouse、Hive 近 10 种 SQL 方言,Doris SQL Convertor 解读及实操演示
随着版本迭代,Apache Doris 一直在拓展应用场景边界,从典型的实时报表、交互式 Ad-hoc 分析等 OLAP 场景到湖仓一体、高并发数据服务、日志检索分析及批量数据处理,越来越多用户与企业开始将 Apache Doris 作为统一的数据分析产品,以解决多组件带来的数据冗余、架构复杂、分析时效性低、运维难度大等问题。 然而在架构统一和升级的过程中,由于部分大数据分析系统有自己的 SQL
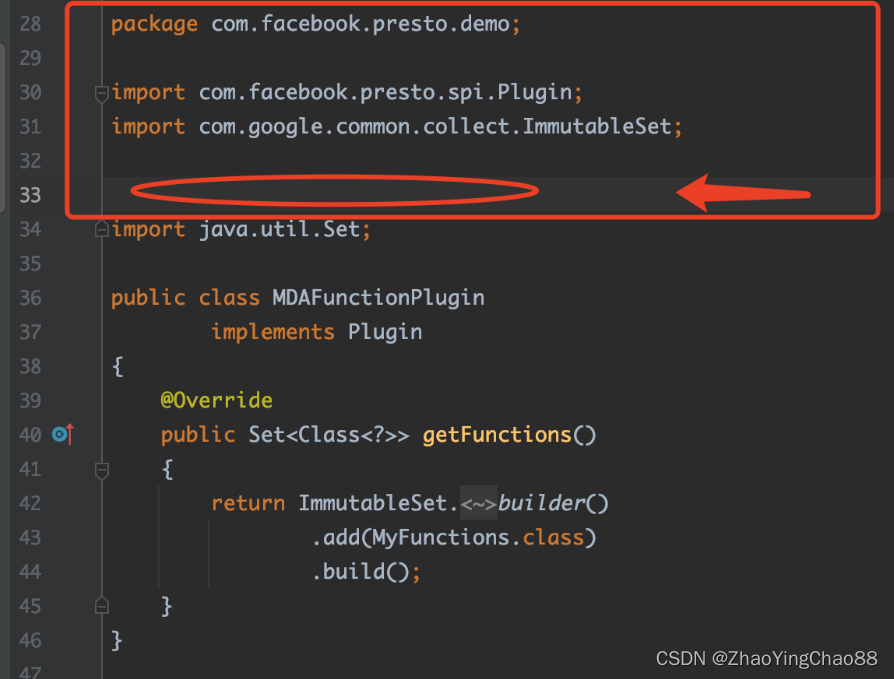
presto / trino plugin(自定义UDF函数)开发指南
方案1:自定义udf插件开发 1. Presto插件机制 presto不能像hive那样配置自定义的udf,而是采用插件机制实现。Presto 的插件(Plugin)机制,是 Presto 能够整合多种数据源的核心。通过实现不同的 Plugin,Presto 允许用户在不同类型的数据源之间进行 JOIN 等计算。Presto 内部的所有数据源都是通过插件机制实现, 例如 MySQL、Hive、

Presto入门简介(含和Hive对比)
一、简介 Presto是由Facebook开发的,是一个运行在多台服务器上的分布式查询引擎,本身并不存储数据,但是可以接入多种数据源(Hive、Oracle、MySql、Kafka、Redis等),并且支持跨数据源的级联查询,比如: select * from a join b where a.id=b.id;,其中表a可以来自Hive,表b可以来自Mysql。 优势(相对于Hive): Pr

python和powerquery直连presto方案
公司数据库新上了presto架构,对于做数据的人而言第一重要的事就是看python和powerquery是否可以直连数据库。 一、python直连presto方案: 1.安装pyhive包 pip install pyhive 2.调用pyhive里的presto from pyhive import prestoconnection = presto.connect(host='127

Presto集群安装配置
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator(调度节点)和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。 coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker 目录: 环境基本要求集群规划连接器安装步骤config.propertiesnode.propertie
【presto权威指南】常用操作
shell ./bin/launcher start ./bin/launcher status ./bin/launcher stop /home/work/presto/bin/presto --server hadoop2:8443 --catalog hive --schema defult --debug --user ‘sdfyypt_2_0_eywa_admin’ //指定用户
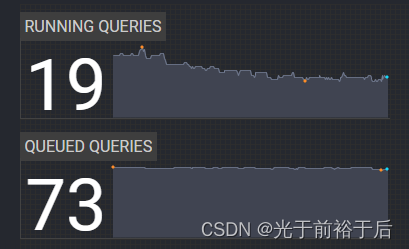
Presto中Queue的使用总结
当众多开发者或是测试人员共同使用一个环境时,可能会出现某个人的大量查询把系统资源耗尽的情况,此时可以使用Queue来限制某人的最大连接数,从而达到资源平等的目的。本文对相关配置以及使用做简单的说明 配置 添加配置文件,文件格式为json文件,例如 文件叫queue_config.json,内容如下 { "queues": { "user.${USER}": { "maxConcurr

Presto Benchmark Driver 的使用
最近在做Presto的研究,系统中有时候会因为重复执行部分SQL查询而导致整个系统的查询会很慢,为了便于重现慢SQL的一些执行过程,这里用到了 Benchmark Driver,本文主要描述 Benchmark Driver的使用方法 安装 下载文件:https://repo1.maven.org/maven2/com/facebook/presto/presto-benchmark-dr
记一次低级且重大的Presto运维事故
本文纯属虚构,旨在提醒各位别犯类似低级错误。 如有雷同,说的就是你! 文章目录 前言事件回顾后续总结 前言 首先,要重视运维工作和离职人员的交接工作,这个不必多说。一将无能,累死三军! 接下来,我尽可能根据操作记录、配置文件备份和聊天记录,还原这长达两个多月的运维事故。但毕竟我也只是个用户,很多细节内幕并不清楚,部分内容会进行“艺术”加工,但一些明显低级的错误行为,大家应

(44)Presto 命令行 Client 安装
1. 命令行 Client 安装 1 )下载 Presto 的客户端 https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.196/presto-cli-0.196- executable.jar 2 )将 presto-cli-0.196-executable.jar 上传