本文主要是介绍Presto 下载安装部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.1 Presto 是什么
Presto(或 PrestoDB)是一种开源的分布式 SQL 查询引擎,设计之初用于对任何规模的数据进行快速分析查询。支持关系型数据【Mysql、PostgreSQL等】及非关系型数据库【Hadoop分布式文件系统(HDFS)、HBase、MongoDB等】。Presto的一大优点是:Presto 设计采用了存储抽象化思想,构建可插入的连接器,可在数据的存储位置查询数据,无需将数据移动到独立的分析系统。且所有的查询执行处理都在内存中进行,大多数结果在几秒内即可返回。
1.2 Presto 工作原理
Presto 是在 Hadoop 上运行的分布式系统,使用与经典大规模并行处理 (MPP) 数据库管理系统相似的架构。它有一个协调器节点(coordinate),与多个工作线程节点(worker)同步工作。用户将其 SQL 查询提交给协调器,由其使用自定义查询和执行引擎进行解析、计划并将分布式查询计划安排到工作线程节点之间。它设计用于支持标准 ANSI SQL 语义,包括复杂查询、聚合、联接、左/右外联接、子查询、开窗函数、不重复计数和近似百分位数。
1.3 Presto 架构图
source :Presto 安装配置 - 简书 (jianshu.com)
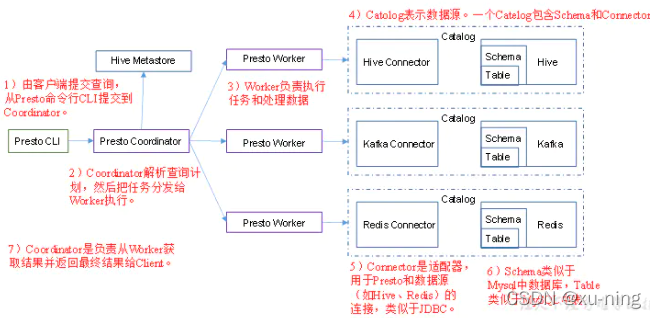
2.1 Presto 下载路径
presto-server-0.245.tar.gz 下载地址:
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/
presto-cli-0.223.1.jar 用更低的版本不要用高版本否则会出现乱码 下载地址:
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/
2.2 本次安装在MobaX 2-120虚拟机上
(1)把安装包移到该虚拟机中并解压。
<MobaX 中可以把压缩包直接拉到左侧文件栏中;或者你用的是FinalShell 可以使用 “ rz -be ” 指令打开要文件夹,选择要上传的压缩包 >
[root@2-120 ~ ] cd /home/deploy
[root@2-120 deploy ] mkdir presto // 把所有presto放在这个文件夹内,目前应包括presto-server-0.245.tar.gz 、presto-cli-0.223.1.jar
[root@2-120 presto ] tar -zxvf presto-server-0.245.tar.gz -C ./
[root@2-120 presto ] tar -zxvf presto-cli-0.223.1.jar -C ./
解压完presto--cli之后,更名、加权限 ,即可使用了
更名
[root@2-120 opt]# mv presto-cli-0.223.1.jar presto-cli2
加权限
[root@2-120 opt]# chmod +x presto-cli2
启动:presto-cli2
[root@2-120 opt]# ./presto-cli2 --server 填你服务器地址,我的是120:8000 --catalog hive --schema default
presto:default> // 这就通过cli客户端进来了
(2)在安装目录中创建一个etc目录, 在这个etc目录中放入以下配置文件:
整体目录结构为:
├── home
├── deploy
├── presto
├── presto-cli2
├── presto-datadir
├── presto-server-0.254
├── presto-server-0.254.tar.gz
├── presto-server-0.254
├── bin
├── lib
├── NOTICE
├── plugin
├── README.txt
├── etc
├── config.properties
├── core-site.xml
├── jvm.config
├── log.properties
├── node.properties
├── catalog
├── hive.properties
├── jmx.properties
- config.properties :Presto 服务配置
- node.properties :环境变量配置,每个节点特定配置
- jvm.config :Java虚拟机的命令行选项
- log.properties: 允许你根据不同的日志结构设置不同的日志级别
- catalog目录 :每个连接者配置(data sources)
(3-1)配置文件 config.properties 的内容:
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8000
query.max-memory=50GB
query.max-memory-per-node=8GB
query.max-total-memory-per-node=8GB
discovery-server.enabled=true
discovery.uri=http://IP:8000 // 8000这个端口号,在你当前虚拟机 / 服务器没有占用就行。至于设成什么可以自定义。注意:若想查找欲设端口号是否被占用,在Linux 环境下可使用 “ lsof -i:8000 ” 来查端口号8000有无没当前服务器使用。
(3-2)配置文件 core-site.xml 的内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定hdfs的nameservice为ns -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property><!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>填你复制后的sink服务器地址,我的是124:22</value> // ZK的ip:port,根据你服务器集群上的情况去更改。
</property>
</configuration>
(3-3)配置文件 jvm.config 的内容:
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
(3-4)配置文件 log.properties 的内容:
com.facebook.presto.hive=DEBUG
org.apache=DEBUG
(3-5)配置文件 node.properties 的内容: // presto-datadir 是放presto 产生的数据文件的。
node.environment=production
node.id=1001
node.data-dir=/home/deploy/presto/presto-datadir
(3-6)配置文件 /etc/catalog/hive.properties 的内容:
connector.name=hive-hadoop2
hive.metastore.uri=thrift://2-120:9083 //2-120 是我当前服务器的名称,你也可以用全ip。172.16.2.120:9083 这样写也是可以的。
// core-site.xml && hdfs-site.xml && hive-site.xml --- 是hadoop和hive 的xml 文件,找到你服务器上hadoop和hive中交这个名字的xml文件,带着地址填到下面的就ok的啦hive.config.resources=/home/deploy/hadoop-2.9.2/etc/hadoop/core-site.xml,/home/deploy/hadoop-2.9.2/etc/hadoop/hdfs-site.xml,/home/deploy/hive2.3.8/conf/hive-site.xml
hive.metastore-cache-ttl=0s
#hive.metastore-refresh-intervals=1s
hive.allow-drop-table=true
hive.parquet.use-column-names=true
(3-7)配置文件 /etc/catalog/jmx.properties 的内容:
connector.name=jmx
(4-1) 将该文件分发到其他机器
1.发送 2-124 机器 scp -r /home/deploy/presto/presto-server-0.245/ root@填你复制后的sink服务器地址,我的是124:/home/deploy/presto/
2.发送 2-123 机器 scp -r /home//deploypresto/presto-server-0.245/ root@填你复制后的sink服务器地址,我的是123:/home/deploy/presto/
(4-2-1) 在 2-124 机器需要修改的第一个文件:node.properties
我的是在124上,你根据你复制的情况来看。
node.environment=production
node.id=master02 // 主要配置node.id 配置不一样
node.data-dir=/home/presto/presto-datadir
(4-2-2) 在 2-124 机器需要修改的第一个文件:config.properties
coordinator=false // 注释掉表示不是coordinator
#node-scheduler.include-coordinator=false // 注释掉表示不是coordinator
http-server.http.port=8000
query.max-memory=50GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
#discovery-server.enabled=true // 注释掉
discovery.uri=http://填你主服务器ip,我的就是120:8000
(4-3-1) 在 2-123 机器需要修改的第一个文件:提示主要修改id 不能重复
我的是在123上,你根据你复制的情况来看。
路径: /home/deploy/presto/presto-server-0.245/etc
[root@2-123 etc]# vi node.properties
node.environment=production
node.id=master03
node.data-dir=/home/presto/presto-datadir
(4-3-2) 在 2-123 机器需要修改的第二个文件
coordinator=false // 注释掉表示不是coordinator
#node-scheduler.include-coordinator=false // 注释掉表示不是coordinator
http-server.http.port=8000
query.max-memory=50GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
#discovery-server.enabled=true // 注释掉
discovery.uri=http://填你主服务器ip,我的就是120:8000
(5-1)首先要启动 master01,slave01,slave02 机器上的presto service 服务
1.后台启动
[root@2-120 presto]$ bin/launcher run
[root@2-124 presto]$ bin/launcher run
[root@2-123 presto]$ bin/launcher run
2.前台启动
[root@2-120 presto]$ bin/launcher start
[root@2-124 presto]$ bin/launcher start
[root@2-123 presto]$ bin/launcher start
3. 日志位置:/home/deploy/presto/presto-datadir/var/log
4. tail -f /home/deploy/presto/presto-datadir/var/log/server.log把120、123、124 的都启动之后,就能在coordinate上操作使用了。这是我出现的结果

用到的些命令
// 查看端口号是否占用 lsof -i:8000
// 给 Presto 加权限
chmod +x /presto/presto.jar
//presto 启动命令
./presto-cli2 --server 我服务器ip:8000 --catalog hive --schema default
//退出presto
quit
参考文档:
Presto安装与配置_zyj8170的专栏-CSDN博客_presto配置
Presto 安装配置 - 简书 (jianshu.com)
这篇关于Presto 下载安装部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








