本文主要是介绍记一次低级且重大的Presto运维事故,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文纯属虚构,旨在提醒各位别犯类似低级错误。
如有雷同,说的就是你!
文章目录
- 前言
- 事件回顾
- 后续
- 总结
前言
首先,要重视运维工作和离职人员的交接工作,这个不必多说。一将无能,累死三军!
接下来,我尽可能根据操作记录、配置文件备份和聊天记录,还原这长达两个多月的运维事故。但毕竟我也只是个用户,很多细节内幕并不清楚,部分内容会进行“艺术”加工,但一些明显低级的错误行为,大家应该也能感觉出来,希望各位以此为戒。
事件回顾
图1 Presto配置文件修改备份记录

图2 Presto用户操作该配置文件记录
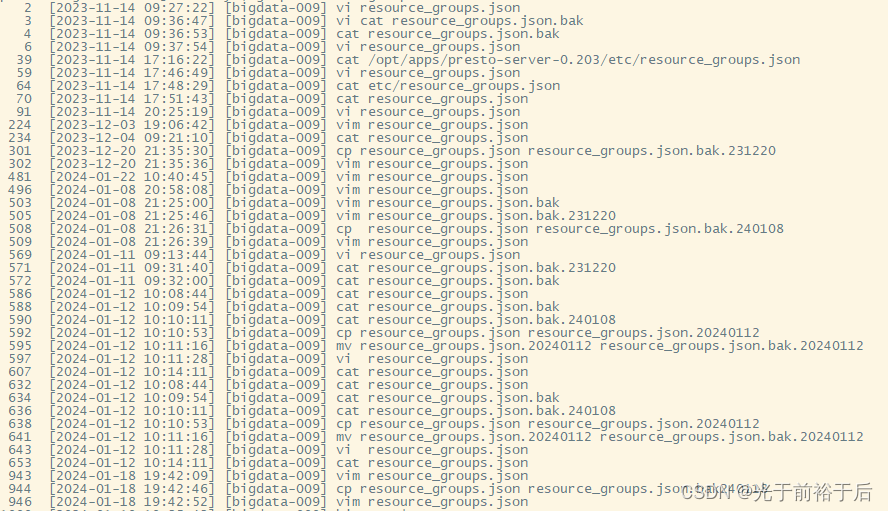
根据图1和图2可以看出以下问题,一是该配置文件修改非常频繁,二是很多修改并没有留下备份,三是不止使用Presto用户操作过该文件,因为有些备份和操作时间对不上。
图3 resource_groups.json.bak
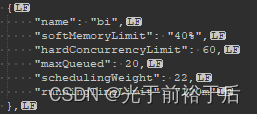
这是2023年10月30日的备份文件配置,bi队列并行任务限制是60,最大排队数是20。备份的是修改之前配置,这和群里聊天记录也能对上,见下。
*2023年10月30日 09:22,有用户反馈很多任务失败,日志报错:
Too many queued queries for “global.bi”
刚接手运维同事 2023年10月30日 10:37 回复
已经找到问题原因,今晚我们会调整 global.bi 资源组的参数,确保满足高峰查询使用
之前我没有过多关注这句话,今天再看到的时候恍然大悟,从2023年10月30日起,他们就已经走错路了。bi队列的用户,不止我们数据部门批任务和即席查询用,dolphinscheduler上的租户没有几个,全公司的批任务大部分也会选择bi队列的用户作为租户使用。而刚接手的运维同事,将bi队列并行任务数限制从60一路降到15,导致大量任务堆积,进而导致了2023年11月后大量用户反馈Presto慢、不能用。
图4 resource_groups.json.bak.231220

这是2023年12月20日的备份文件配置,bi队列并行任务限制从60降到20,最大排队数从20涨到45。因为2023年10月30日至2023年12月20日之间修改配置并没有留备份,无法确定哪天修改,可以确定的是2023年12月20日前就已经改成20了。但bi队列是全公司用的最多的队列,竟然被他们拍脑门限制为20,生产集群改的如此随意。更可笑的是,某位人才把问题推给用户写的代码太烂,把用户当傻子,进一步激化矛盾。退一万步讲,写的烂也是一直都烂,集群正常运行多年,任务也正常运行多年,你就没意识到自己最近改了什么东西?另外还有人才归到了即席查询和批处理不能同时使用,同时使用这么多年,你一接手就不能用了是吧?还有任务变多、小文件过多等等借口。
图5 resource_groups.json.bak.20240112
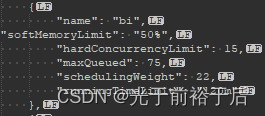
这是2024年1月12日的备份文件配置,bi队列并行任务限制从最开始60降到15,最大排队数从45涨到75。2024年1月12日的备份是2024年1月8日至2024年1月12日的配置。
后续
在领导英明领导下,我们于2024年1月6日进行了小文件归档操作,截至2024年1月16日,清理了五千万小文件。
hadoop archive -Dmapred.job.queue.name=xxx -archiveName xxx.har -p
Presto成功的从上午不能用,变成了下午也不能用。写个select 1 都要运行(排队)二十分钟。当然,这和清理小文件无关,某个人才于2024-01-08 21:26:39将bi队列并行任务限制改为15。

好在他们做对了一件事,2024年1月6日不光清理小文件,还新搭了14个节点的集群。当用户反馈不能用时,让他们使用新集群,成功实现了分流。但是dolphinscheduler上还有大量的任务使用老集群,15的限制还是导致任务积压、排队,问题还是没有解决。
我不是运维人员,一直知道他们改了配置,但不知道他们这么瞎改。了解这一切,是我在2024年1月18日偶然发现一个事,当单个任务实时内存使用超过150GB就会失败。

而老集群31个节点,单节点256GB,31*256=7936GB,单任务限制最大150GB。当时同时执行的只有19个任务,其它都在排队,就算都是顶格150GB,剩下还有大量资源。
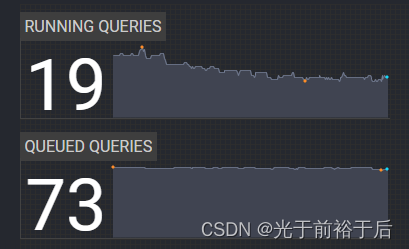
于是我把这情况反馈到群里,领导@几个运维让回答一下,至今没有任何回复。
虽然没有回答,但他们晚上把限制提高到了20,与此同时,还更换了故障节点(存疑),降低了NameNode 堆内存等。2024年1月19日,Presto老集群突然正常了,但由于他们同时修改较多,且只是把限制从15提高到20,无法确定根源。但有一点可以确定,bi队列限制为15,甚至20都极不合理,大量资源闲置,人为制造排队。从上图可以看出,当时bi队列限制为15,其它队列加一起才19-15=4个任务,bi队列73个排队!
总结
从2023年10月30日到现在,两个多月时间,老Presto集群基本处于上午不能用的状态,甚至后来下午也不能用。不可否认,运维做了一些有效的工作,但如果一开始用户反馈排队过多,只是因为部分节点挂掉,甚至真的因为任务突然增多了,运维去增加节点(从后来搭建14个节点新集群来看,并不是没有服务器),而不是瞎改配置,结果会不会不一样?如果运维修改生产环境配置文件不那么随意、频繁,而是先统计bi队列每天总任务数、并行任务数,根据实际情况调整限制和错开任务执行时间,结果会不会不一样?
很多事宜通不宜堵,有些人什么时候才能明白。
祝愿大家远离低级的人和事。
这篇关于记一次低级且重大的Presto运维事故的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







