ner专题

NLP-信息抽取-NER-2015-BiLSTM+CRF(一):命名实体识别【预测每个词的标签】【评价指标:精确率=识别出正确的实体数/识别出的实体数、召回率=识别出正确的实体数/样本真实实体数】
一、命名实体识别介绍 命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型。是信息提取, 问答系统, 句法分析, 机器翻译等应用领域的重要基础工具, 在自然语言处理技术走向实用化的过程中占有重要地位. 包含行业, 领域专有名词, 如人名, 地名, 公司名, 机构名, 日期, 时间, 疾病名, 症状名, 手术名称, 软

命名实体识别(NER)-模型评估:词级别评估、实体级别评估【Precision、Recall、F1】
一、概述 命名实体识别的评判标准:实体的边界是否正确;实体的类型是否标注正确。主要错误类型包括: 文本正确,类型可能错误;反之,文本边界错误,而其包含的主要实体词和词类标记可能正确。 对于二分类的模型,预测结果与实际结果分别可以取0和1。我们用N和P代替0和1,T和F表示预测正确和错误。将他们两两组合,就形成了下图所示的混淆矩阵(注意:组合结果都是针对预测结果而言的)。 由于1和0是数字

NLP领域内,文本分类、Ner、QA、生成、关系抽取等等,用过的最实用、效果最好的技巧或思想是什么?
作者:杨夕 链接:https://www.zhihu.com/question/451107745/answer/1801709801 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 命名实体识别用过的最实用、效果最好的技巧或思想可以看一下 这个 【关于 NER trick】 那些你不知道的事github.com/km1994/NLP-Interview

将stanfordcorenlp的tokenizer换成自定义的(或用stanfordcorenlp对自定义tokenizer分词后的结果做ner)
本文是基于中文语料做的,对于英文语料应该也是同理,即同样适用的。 分析stanfordcorenlp的分词结果,可以发现,它好像是对最小的中文词进行分词,即其对中文的分词粒度很小,这对于某些nlp场景可能就不太合适了,自然的就想到能不能将stanfordcorenlp中用于分词的tokenizer替换掉,替换成自定义的,这样就可以控制中文分词结果是你想要的了。 基于以上动机,我查找了相关资料,

实体识别NER模块理解整理(待进一步更新)
请参考 BiLSTM-CRF理解整理 一篇BiLSTM-CRF比较易懂的文章 英文 基于上面的链接内容的理解 博客 收藏不看的简书教程 其中的CRF: 由于状态转移的限制,能够避免诸如 I 的后面接 B的非法错误。 最大熵模型NER 最大熵与大病中病小病 当你要猜一个概率分布时,如果你对这个分布一无所知,那就猜熵最大的均匀分布, 如果你对这个分布知道一些情况,那么,就猜满足这些情况的熵最大

论文笔记 | Simplify the Usage of Lexicon in Chinese NER
作者:刘锁阵 单位:燕山大学 论文地址:https://www.aclweb.org/anthology/2020.acl-main.528.pdf 代码地址:https://github.com/v-mipeng/LexiconAugmentedNER 文章目录 背景介绍Softword特征Lattice-LSTM 模型设计字符表示层合并词典信息ExSoftword特征Soft

spacy NER 位置信息不考虑空格!!!
texts = ["疫情期间,俄罗斯 联邦军队医疗机构的负责人Saanvi Alia在方城县启动了远程医疗服务。","疫情期间,俄罗斯 联 邦 军队医疗机构的负责人Saanvi Alia在方城县启动了远程医疗服务。","疫情期间,俄罗 斯 联 邦 军 队医疗 机构的负责人Saanvi Alia在方城县启动了远程医疗服务。",]for text in texts:doc = nlp(text)fo
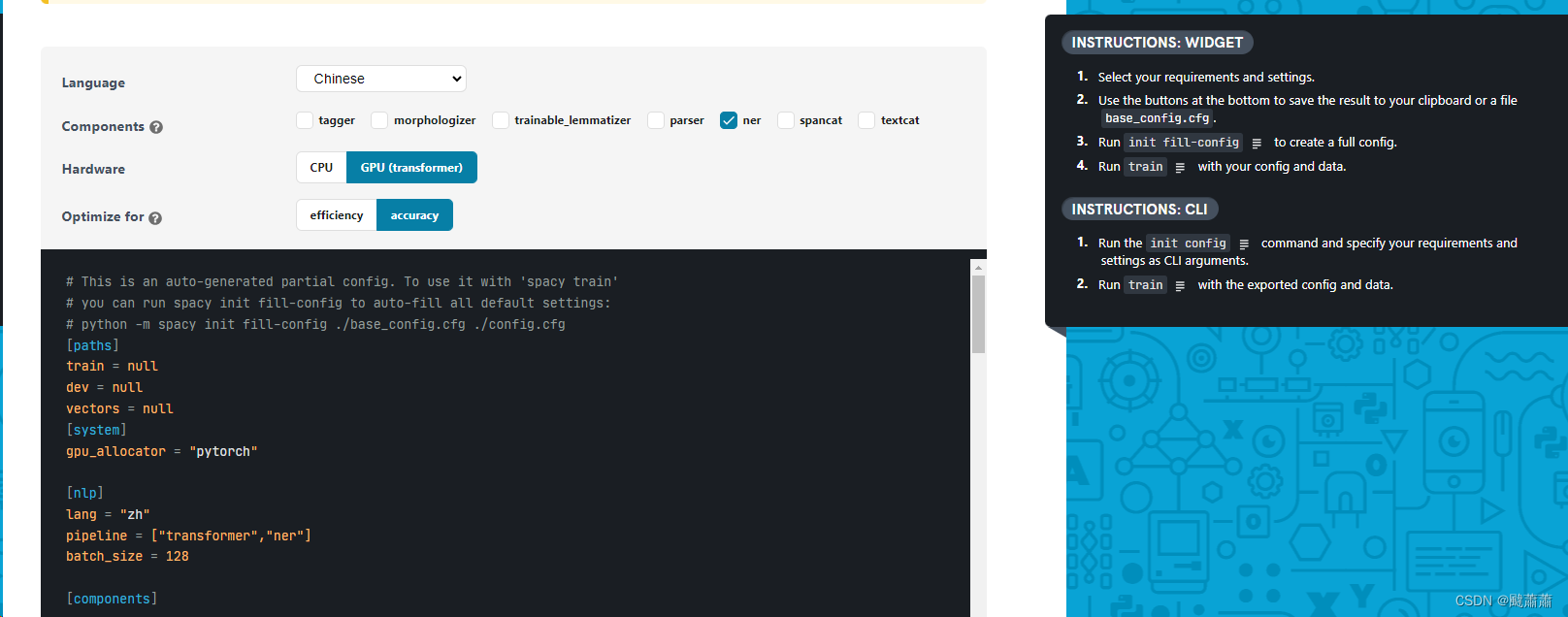
spacy微调BERT-NER模型
数据准备 加载数据集 from tqdm.notebook import tqdmimport osdataset = []with open(train_file, 'r') as file:for line in tqdm(file.readlines()):data = json.loads(line.strip())dataset.append(data) 你可以按照 CLUE

Bert基础(十八)--Bert实战:NER命名实体识别
1、命名实体识别介绍 1.1 简介 命名实体识别(NER)是自然语言处理(NLP)中的一项关键技术,它的目标是从文本中识别出具有特定意义或指代性强的实体,并对这些实体进行分类。这些实体通常包括人名、地名、组织机构名、日期、时间、专有名词等。NER在许多实际应用中都非常重要,如信息提取、文本挖掘、机器翻译、自动摘要等。 NER的任务主要分为两部分: 实体的边界识别:这部分任务是要确定文本中实体
2017. cheap translation for Cross-lingual NER 阅读笔记
cheap translation for Cross-lingual NER, Illinois Champaign 提出了一个生成翻译字典的 cheap translation 算法该算法可以和 wikifier features、Brown Cluster features 等结合取得更好的效果通过实验说明当 source Lan. 与 traget Lan. 相似度比较高时,可以进一步提
NER (named entity recognition)
命名实体识别,主要目的是从文本中检测出专有名词并进行分类,如人名、地名、公司名、日期等。 综述一篇: A survey of named entity recognition and classification, D Nadeau, S Sekine, Linguisticae Investigationes, 2007 http://nlp.cs.nyu.edu/sekine/p

BERT 微调中文 NER 模型
查看GPU数量和型号 import torch# 检查CUDA是否可用if torch.cuda.is_available():print("CUDA is available!")# 还可以获取CUDA设备的数量device_count = torch.cuda.device_count()print(f"Number of CUDA devices: {device_count}")# 获

Raki的读paper小记:通过教师-学生模型在目标语言上的无标注数据上学习来实现单源/多源跨语言NER任务 from ACL2020
Single-/Multi-Source Cross-Lingual NER via Teacher-Student Learning on Unlabeled Data in Target Language 不要问我为什么改成了中文名,因为标题名字太长了!! Abstract & Introduction & Related Work 研究任务 通过教师-学生模型在目标语言上的无标注数据上

统一的NER识别模型-Unified NER
论文:Unified Named Entity Recognition as Word-Word Relation Classification 地址:https://arxiv.org/abs/2112.10070 截止到20220308为止的sota 1. 提出两个概念 提出了两个新的概念,将连续、嵌套、不连续实体的识别进行了统一,可用一个模型更好的完成以上三种实体的识别:

基于卷积注意力神经网络的命名实体识别(CAN-NER)
CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition(NAACL-HLT 2019) 论文要点 该论文提出过去基于词向量和词典中的几个问题: 模型结果会受词向量和词典覆盖好坏的影响【迁移问题】会存在OOV的问题,而命名实体大多为OOV词向量会极大增大模型大小【Embeddings Size一
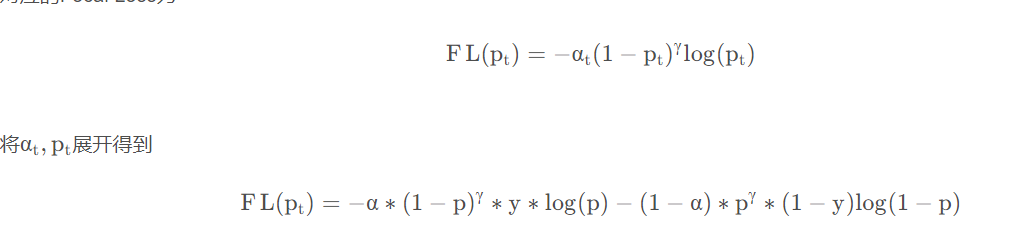
中医药NER命名实体识别基于SPANNER方式
向AI转型的程序员都关注了这个号👇👇👇 知识图谱是近年来知识管理和知识服务领域中出现的一项新兴技术,它为中医临床知识的关联、整合与分析提供了理想的技术手段。我们基于中医医案等临床知识源,初步建立了由疾病、证候、症状、方剂、中药等核心概念所构成的中医临床知识图谱,以促进中医临床知识的互融互通,揭示中医方证的相关关系,辅助中医临床研究和临床决策。 中医药学是一门古老的医学,历代医家在数千年的

自然语言处理(NLP)中NER如何从JSON数据中提取实体词的有效信息
专栏集锦,大佬们可以收藏以备不时之需: Spring Cloud 专栏:http://t.csdnimg.cn/WDmJ9 Python 专栏:http://t.csdnimg.cn/hMwPR Redis 专栏:http://t.csdnimg.cn/Qq0Xc TensorFlow 专栏:http://t.csdnimg.cn/SOien Logback 专栏:http://t.cs
NLP命名实体识别(NER)代码实践
NLP命名实体识别(NER)开源实战教程 引 https://blog.csdn.net/xiaosongshine/article/details/99622170 NER学习系列之-BILSTM+CRF 转 https://blog.csdn.net/Jasminexjf/article/details/88407645?utm_medium=distribute.pc_rele
NLP NER HMM CRF讲的较好的知乎
NLP NER HMM CRF讲的较好的知乎 https://zhuanlan.zhihu.com/p/88544122 专门讲CRF层的 https://www.cnblogs.com/createMoMo/p/7529885.html
源码阅读笔记 BiLSTM+CRF做NER任务 流程图
源码阅读笔记 BiLSTM+CRF做NER任务(二) 源码地址:https://github.com/ZhixiuYe/NER-pytorch 本篇正式进入源码的阅读,按照流程顺序,一一解剖。 一、流程图 https://www.cnblogs.com/zhuangzi101/p/12753620.html

BERT-文本分类NER
BERT文本分类 训练样本 训练数据:18W条 评估数据:1W条 测试数据:1W条 体验2D巅峰 倚天屠龙记十大创新概览 860年铁树开花形状似玉米芯(组图) 5同步A股首秀:港股缩量回调 2中青宝sg现场抓拍 兔子舞热辣表演 8锌价难续去年辉煌 02岁男童爬窗台不慎7楼坠下获救(图) 5布拉特:放球员一条生路吧 FIFA能消化俱乐部的攻击 7金科西府 名墅天成 1状元
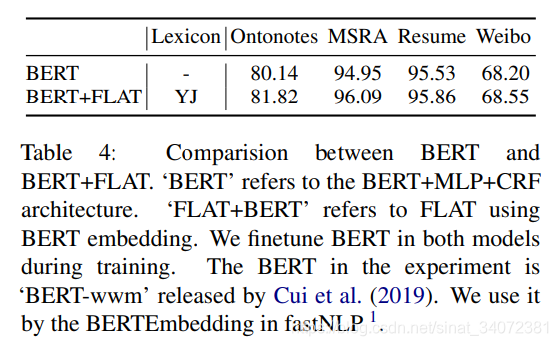
FLAT:使用Transformer引入词汇信息增强中文NER(Chinese NER Using Flat-Lattice Transformer)
文章目录 1 引言2 背景3 模型3.1 转换格子为扁平结构3.2 范围的相对位置编码 4 实验4.1 实验设置4.2 整体性能4.3 全连接结构的优势4.4 FLAT效率4.5 FLAT的提升4.6 BERT兼容性 【论文链接】:FLAT: Chinese NER Using Flat-Lattice Transformer 近年来,已证明引入词汇信息的字-词格子结构能够

B站【1espresso】NLP - transform、bert、HMM、NER课件
git地址 传送门 传送门2(含bert情感分析) 仅学习使用,侵删 中文自然语言处理 Transformer模型(一) transformer是谷歌大脑在2017年底发表的论文attention is all you need中所提出的seq2seq模型. 现在已经取得了大范围的应用和扩展, 而BERT就是从transformer中衍生出来的预训练语言模型. 目前tran
信息抽取(Information Extraction:NER(命名实体识别),关系抽取)
信息/数据抽取是指从非结构化或半结构化文档中提取结构化信息的技术。信息抽取有两部分:命名实体识别(目标是识别和分类真实世界里的知名实体)和关系提取(目标是提取实体之间的语义关系)。概率模型/分类器可以帮助实现这些任务。 信息抽取的定义为:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术 信息抽取是从文本数据中抽取特定信息的一种技术。文本数据是由
pytorch bilstm crf NER
参考链接:https://blog.csdn.net/Jason__Liang/article/details/81772632 https://github.com/jayavardhanr/End-to-end-Sequence-Labeling-via-Bi-directional-LSTM-CNNs-CRF-Tutorial/blob/master/Named_Entity_Recogn