本文主要是介绍FLAT:使用Transformer引入词汇信息增强中文NER(Chinese NER Using Flat-Lattice Transformer),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 引言
- 2 背景
- 3 模型
- 3.1 转换格子为扁平结构
- 3.2 范围的相对位置编码
- 4 实验
- 4.1 实验设置
- 4.2 整体性能
- 4.3 全连接结构的优势
- 4.4 FLAT效率
- 4.5 FLAT的提升
- 4.6 BERT兼容性
【论文链接】:FLAT: Chinese NER Using Flat-Lattice Transformer
近年来,已证明引入词汇信息的字-词格子结构能够有效提升中文NER任务(强化实体边界),然而,格子结构复杂且多变,多数现有的基于格子结构的模型难以利用GPU并行计算,并且推理速度较慢。
本文提出FLAT(Flat-LAttice Transformer for Chinese NER),其将格子结构转变为由数个区间组成的扁平结构,每一个区间与字或词在原格子中的位置相关。利用强大的Transformer和设计优良的位置编码,FLAT能够充分利用格子信息,并具有优秀的并行化能力。在4个实验上验证表明,FLAT的性能和效率显著优于基于字典的方法。
1 引言
NER在许多自然语言处理任务中扮演者重要角色,与英文NER相比,由于中文NER任务通常包含词汇信息,往往更加复杂。
近期,已证明格子结构能够利用词汇信息避免分词误差传播(中文分词歧义),我们可以利用词典获得句子中包含的词汇,从而获得如图1所示的格子结构。
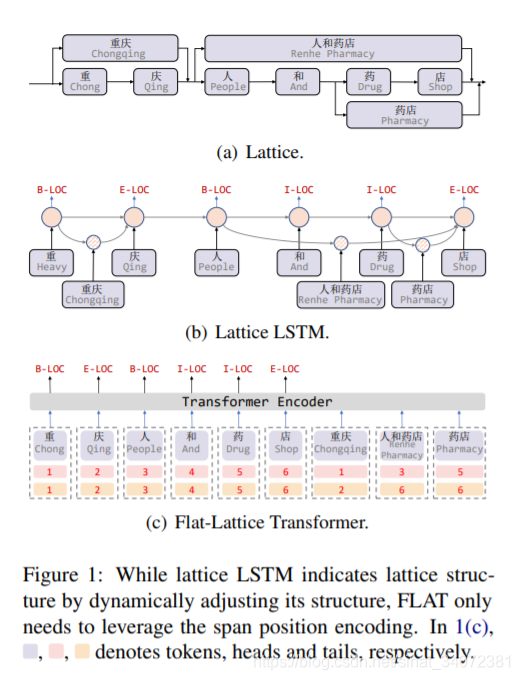
格子结构是有向无环图,每一个节点是一个字符,或是一个潜在的词汇。格子包含字符序列和句中潜在的词汇,它们并不是有序序列,词汇的位置由首尾字符决定。格子中的一些词汇对于NER任务可能很重要,例如,图1a中,利用人和药店能够区分地理实体 “重庆” 和组织实体 “重庆人”。
目前有两种方法利用格子信息。
第一种,设计模型适配格子输入,如lattice LSTM 和 LR-CNN。lattice LSTM 利用额外的词汇单元编码潜在词汇信息,并利用注意力机制融合每一个位置包含的不同数量的节点,如图1b所示。LR-CNN使用CNN在不同窗口中编码词汇信息。然而,RNN和CNN难以建模NER任务中可能很有用的长期依赖,如共同指代。由于格子结构的动态性,这些模型也难以利用GPU并行计算。
第二种,转换格子为图,并使用GNN编码,例如LGN和CGN,序列结构对于NER任务很重要,为此多数图方法使用LSTM作为底层编码器感知位置偏差,这使得模型更加复杂。
本文提出FLAT模型,Transformer采用全连接注意力编码序列中的长期依赖,为保持位置信息,Transformer为序列中每一个token引入一个位置表示。
受位置表示启发,我们为格子结构设计了一种独创的位置编码,如图1c所示。具体地说,我们为每一个token(字符或词汇)设计两种位置索引:头位置和尾位置,并用其从tokens集合中重建格子结构。因此,我们可以直接使用Trasnsformer完全建模格子输入。
Transformer中的注意力机制使得字符能直接与任意词汇交互,包括自匹配的词汇,对于字符来说,其自匹配词汇为包含它的词汇,例如图1a,“药”的自匹配单词是“人和药店”和“药店”。
实验结果表明,我们的模型的性能和推理速度显著优于其他基于字典的方法,本文代码将开源于https://github.com/LeeSureman/FlatLattice-Transformer。
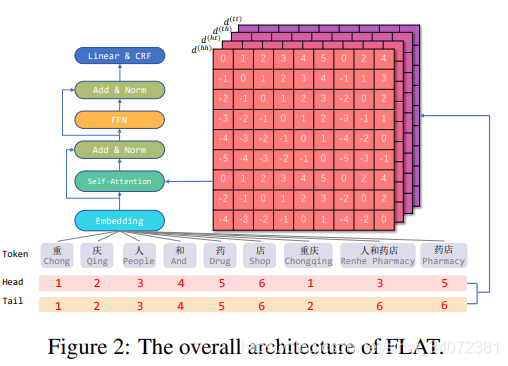
2 背景
本节简要介绍Transformer结构。主要关注于NER任务,我们仅讨论Transformer Encoder部分,它由自注意力和前馈神经网络FFN组成,每一个子层之后接残连接和层标准化。FFN使用非线性变化的全位置多层感知机。Transformer在序列上使用独立的多头自注意力,并拼接多头结果作为最终结果。
为简化,下式中忽略了多头索引,每一个头的计算公式为:

其中, E E E是词向量或上一层Transformer的输出。 W q W_q Wq, W k W_k Wk, W v ∈ R d m o d e l × d h e a d W_v\in\R^{d_{model}\times d_{head}} Wv∈Rdmodel×dhead是可学习参数, d m o d e l = H × d h e a d d_{model}=H\times d_{head} dmodel=H×dhead, d h e a d d_{head} dhead是每一个头的维度。
天然Transformer使用绝对位置编码捕获序列信息,受启发于Yan et al. (2019),我们认为自注意力中向量内点的交换可能损失方向性,因此,我们认为格子的相对位置对NER也很重要。
3 模型
3.1 转换格子为扁平结构
利用字典从字符串获得格子之后,将其压平,这些扁平格子也可被定义为一系列区间,一个区间与一个token、一个头和一个尾有关,如图1c所示。
token是一个字符或词汇,头和尾表示token首尾字符在原序列中的位置,它们指示格子中token的位置,字符的头尾相同。可利用简单的算法将扁平格子还原为原始结构,为构造字符序列,我们首先认为token的头尾相同,然后,使用余下词汇的头尾建立跳路径,由于转换可逆,我们假定扁平格子能够保留格子的原始结构。
3.2 范围的相对位置编码
扁平格子结构由不同长度的区间组成,为编码区间之间的交互,我们提出区间相对位置编码。对于格子中的两个区间 x i x_i xi和 x j x_j xj,根据各自的头尾位置具有三种不同的关系:交叉、包含和分离。我们不是直接编码这三种关系,而是使用密度向量建模。
我们利用头尾信息的连续变换计算关系向量,因此,我们认为它不仅能表示两个token的关系,而且可能指明如字符和词汇之间的距离等其它详细信息。我们使用 h e a d [ i ] head[i] head[i]和 t a i l [ i ] tail[i] tail[i]表示区间 x i x_i xi的头尾位置,区间 x i x_i xi和 x j x_j xj的四种相对位置表示为:

其中, d i j ( h h ) d_{ij}^{(hh)} dij(hh)表示 x i x_i xi和 x j x_j xj头之间的距离。最终区间之间的相对位置编码是四种距离的非线性变换:

其中, W r W_r Wr是可学习参数, ⊕ \oplus ⊕表示拼接操作, p d p_d pd计算如下:

其中, d d d是 d i j ( h h ) d_{ij}^{(hh)} dij(hh), d i j ( h t ) d_{ij}^{(ht)} dij(ht), d i j ( t h ) d_{ij}^{(th)} dij(th), d i j ( t t ) d_{ij}^{(tt)} dij(tt); k k k表示位置编码的维度索引,然后,我们使用一种自注意力的变体来利用相对区间位置编码,如下:

其中, W q W_q Wq, W k , R W_{k,R} Wk,R, W k , E ∈ R d m o d e l × d h e a d W_{k,E}\in\R^{d_{model}\times d_{head}} Wk,E∈Rdmodel×dhead, u u u, v ∈ R d h e a d v\in\R^{d_{head}} v∈Rdhead是可学习参数。因此,我们将公式1中的 A A A替换为 A ∗ A^* A∗,之后的计算与天然Transformer一致。
FLAT之后,我们在输出层仅利用字符表示,之后接入CRF层。
4 实验
4.1 实验设置
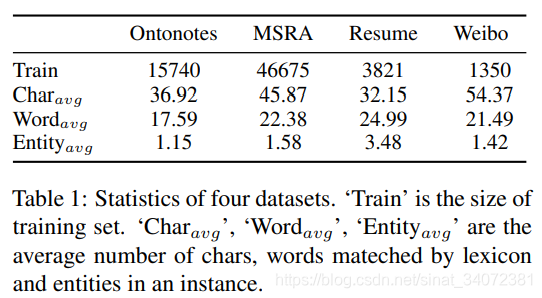
我们使用4种中文NER评估我们的模型,包括:Ontonotes 4.0、MSRA、Resume和Weibo,如表1所示。
4.2 整体性能
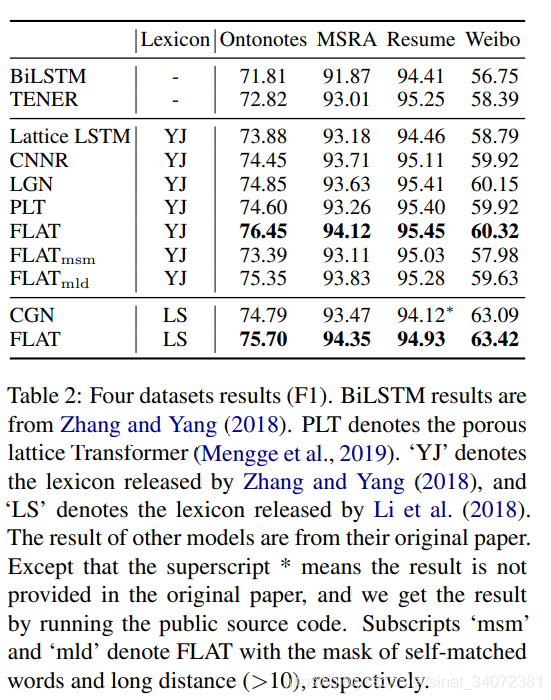
表2为我们模型与几种基于字典的中文NER模型的比较。
4.3 全连接结构的优势
自注意力机制的两处优势:
- 所有字符能直接与自匹配单词交互;
- 可建模长期依赖
由于我们的模型仅包含一层,我们可以通过掩盖相关的注意力分离它们。具体地说,我们掩盖字符与其距离超过10的自匹配词汇之间的注意力。如表2所示,第一种掩盖是FLAT性能急剧下降,而第二种使性能略微下降,因此,对于中文NER任务,我们认为利用自匹配词汇的信息十分必要。
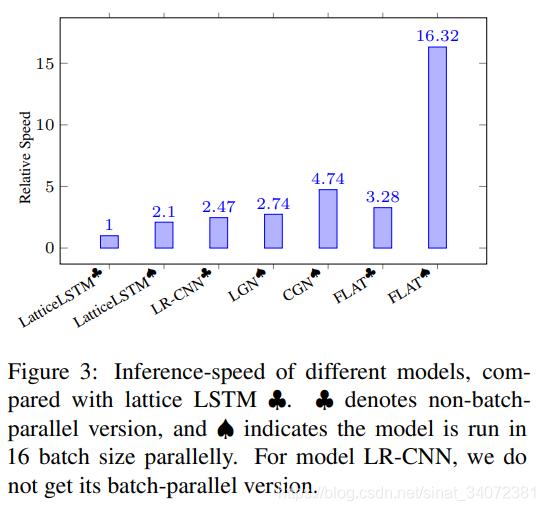
4.4 FLAT效率
为验证我们模型的计算效率,我们在Ontonotes数据集上评估不同的基于字典的模型的推理速度,结果如图3所示。
4.5 FLAT的提升
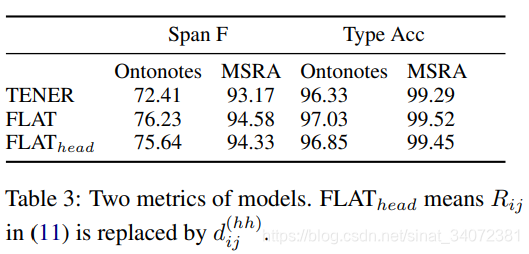
Span F表示区间F分数(不考虑实体类型),Type Acc表示完全预测正确与区间预测正确的比例。表3表明:
- 新位置编码有助于FLAT准确定位实体位置;
- 预训练的词汇向量使得FLAT准确分类实体类别;
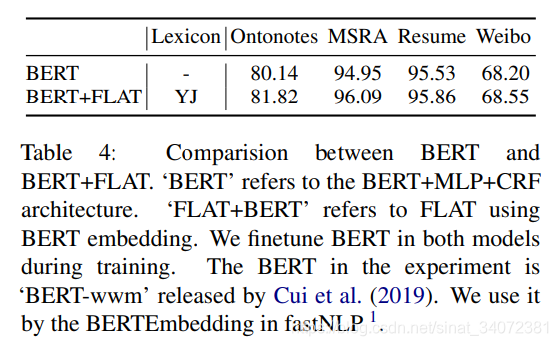
4.6 BERT兼容性
这篇关于FLAT:使用Transformer引入词汇信息增强中文NER(Chinese NER Using Flat-Lattice Transformer)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




