本文主要是介绍spacy微调BERT-NER模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据准备
加载数据集
from tqdm.notebook import tqdm
import osdataset = []
with open(train_file, 'r') as file:for line in tqdm(file.readlines()):data = json.loads(line.strip())dataset.append(data)
你可以按照 CLUENER 的格式准备训练数据,
例如:
{'text': '胡建新经营着位于深圳市福田区华富街道田面社区深南中路4028号田面城市大厦19B-19C的公司。','label': {'person': {'胡建新': [[0, 2]]},'address': {'深圳市福田区华富街道田面社区深南中路4028号田面城市大厦19B-19C': [[8, 43]]}}}
拆分训练集验证集
import random
import numpy as npdef split_train_test_valid(dataset, train_size=0.8, test_size=0.1):dataset = np.array(dataset)total_size = len(dataset)# define the ratiostrain_len = int(total_size * train_size)test_len = int(total_size * test_size)# split the dataframeidx = list(range(total_size))random.shuffle(idx) # 将index列表打乱data_train = dataset[idx[:train_len]]data_test = dataset[idx[train_len:train_len+test_len]]data_valid = dataset[idx[train_len+test_len:]] # 剩下的就是validreturn data_train, data_test, data_validdata_train, data_test, data_valid = split_train_test_valid(dataset)
转化成 spacy docbin 格式
from spacy.tokens import DocBin
from tqdm import tqdm
from spacy.util import filter_spansdef to_docbin(dataset):data = datasetdata_spacy = []for d in tqdm(data):text = d['text']tags = []labels = d['label']for label in labels:entities = labels[label]for entity in entities:for loc in entities[entity]:tags.append((loc[0], loc[1]+1, label))data_spacy.append({"text":text, "entities": tags})nlp = spacy.blank('zh') # 选择中文空白模型doc_bin = DocBin()for training_example in tqdm(data_spacy):text = training_example['text']labels = training_example['entities']doc = nlp.make_doc(text)ents = []for start, end, label in labels:span = doc.char_span(start, end, label=label, alignment_mode="contract")if span is None:print("Skipping entity")else:ents.append(span)filtered_ents = filter_spans(ents)doc.ents = filtered_entsdoc_bin.add(doc)return doc_bindoc_bin_train = to_docbin(data_train)
doc_bin_train.to_disk("train.spacy")
doc_bin_valid = to_docbin(data_valid)
doc_bin_valid.to_disk("valid.spacy")
训练集和验证集保存到了 train.spacy 和 valid.spacy
获取spacy训练配置
进入网页:https://spacy.io/usage/training#quickstart
选择Chinese/ner/GPU,自动生成配置文件 base_config.cfg
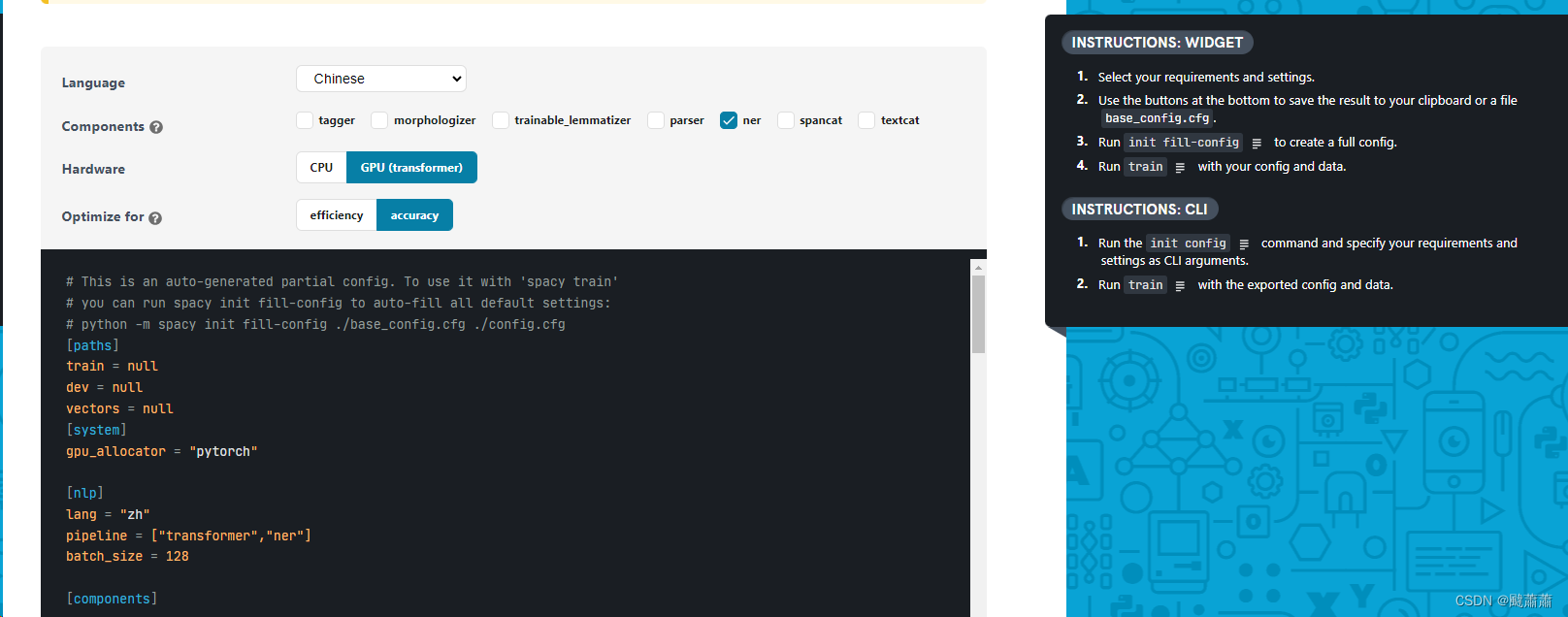
自动补全配置
python -m spacy init fill-config base_config.cfg config.cfg
训练模型
python -m spacy train config.cfg --output . --paths.train ./train.spacy --paths.dev ./valid.spacy --gpu-id 0
日志如下:
python -m spacy train config.cfg --output . --paths.train ./train.spacy --paths.dev ./dev.spacy --gpu-id 0
ℹ Saving to output directory: .
ℹ Using GPU: 0=========================== Initializing pipeline ===========================
Some weights of the model checkpoint at ../models/bert-base-chinese were not used when initializing BertModel: ['cls.seq_relationship.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
✔ Initialized pipeline============================= Training pipeline =============================
ℹ Pipeline: ['transformer', 'ner']
ℹ Initial learn rate: 0.0
E # LOSS TRANS... LOSS NER ENTS_F ENTS_P ENTS_R SCORE
--- ------ ------------- -------- ------ ------ ------ ------0 0 2414.47 804.03 0.41 0.25 1.17 0.000 200 553440.62 100815.50 25.73 27.65 24.06 0.261 400 379529.80 55305.57 36.83 43.31 32.03 0.372 600 164609.24 36629.69 62.07 60.54 63.67 0.623 800 163662.29 38876.53 32.75 42.38 26.69 0.334 1000 81601.30 28677.56 62.02 63.22 60.87 0.625 1200 75558.20 26489.57 61.61 63.17 60.12 0.626 1400 87824.25 25230.27 69.77 69.59 69.95 0.706 1600 54173.95 21436.94 70.03 69.52 70.54 0.707 1800 30978.67 15641.39 71.80 72.03 71.58 0.728 2000 27723.05 13770.74 69.07 69.53 68.62 0.699 2200 25622.08 12936.05 72.89 71.89 73.93 0.7310 2400 24126.19 13338.83 71.58 71.96 71.19 0.7211 2600 21804.75 11238.43 74.20 74.82 73.60 0.7412 2800 20628.26 10916.07 71.44 71.39 71.48 0.7113 3000 20134.37 11081.41 72.51 72.17 72.85 0.7314 3200 16227.69 8933.84 74.17 73.84 74.51 0.7414 3400 19235.74 9438.10 72.00 73.18 70.87 0.7215 3600 29307.03 12692.90 74.84 76.13 73.60 0.7516 3800 18102.06 8969.09 73.38 71.82 75.00 0.7317 4000 14903.23 8416.16 73.11 71.91 74.35 0.7318 4200 19608.45 9377.10 72.91 72.67 73.14 0.7319 4400 17153.18 8931.95 74.35 74.20 74.51 0.7420 4600 17934.71 9112.66 66.37 67.00 65.76 0.6620 4800 13376.17 7252.01 74.06 74.29 73.83 0.7421 5000 13659.26 6804.46 72.38 71.47 73.31 0.7222 5200 18188.32 8358.28 73.57 72.22 74.97 0.74
✔ Saved pipeline to output directory
model-last
验证集 F1 score 达到了 0.75,相比比非transform的模型的 0.65 如下,结果是有明显提升的:
ℹ Saving to output directory: .
ℹ Using GPU: 0=========================== Initializing pipeline ===========================
✔ Initialized pipeline============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'ner']
ℹ Initial learn rate: 0.001
E # LOSS TOK2VEC LOSS NER ENTS_F ENTS_P ENTS_R SCORE
--- ------ ------------ -------- ------ ------ ------ ------0 0 0.00 49.29 0.09 0.15 0.07 0.000 200 496.94 3348.46 5.82 4.36 8.76 0.060 400 1408.31 4107.52 9.38 20.41 6.09 0.090 600 2121.99 5357.34 17.45 23.00 14.06 0.170 800 1096.04 5009.92 19.90 27.89 15.46 0.200 1000 931.30 5447.63 27.72 33.77 23.50 0.280 1200 1375.05 6551.97 32.09 38.83 27.34 0.320 1400 1388.81 7116.59 37.61 43.81 32.94 0.380 1600 2521.46 9638.09 42.25 52.07 35.55 0.421 1800 2172.77 10659.31 40.53 48.04 35.06 0.411 2000 3563.99 12454.60 43.00 49.98 37.73 0.431 2200 4926.80 15747.33 46.38 50.38 42.97 0.462 2400 4712.95 18150.01 48.91 53.97 44.73 0.492 2600 4945.91 18023.03 50.25 53.30 47.53 0.503 2800 6100.79 18400.07 51.21 54.85 48.01 0.513 3000 5124.39 17074.50 51.38 54.62 48.50 0.514 3200 5595.23 17486.11 52.83 57.31 48.99 0.534 3400 5857.02 16183.54 52.39 55.95 49.25 0.525 3600 7097.00 16779.79 55.20 58.97 51.89 0.555 3800 7305.36 16330.97 53.70 56.30 51.33 0.546 4000 6912.16 15848.24 55.86 57.40 54.39 0.566 4200 7083.29 15591.03 54.72 57.02 52.60 0.557 4400 7072.32 14623.82 55.80 61.07 51.37 0.567 4600 9153.78 15341.62 57.24 58.95 55.63 0.578 4800 7584.10 14801.21 54.85 56.26 53.52 0.558 5000 7514.11 14013.45 58.38 61.83 55.31 0.589 5200 9505.86 14416.66 57.41 60.38 54.72 0.579 5400 8458.73 13544.08 58.90 62.29 55.86 0.5910 5600 9179.71 12723.23 58.53 60.97 56.28 0.5910 5800 9730.11 13078.69 58.85 62.58 55.53 0.5911 6000 8485.15 13275.12 59.14 62.02 56.51 0.5911 6200 10376.37 12896.16 58.77 60.26 57.36 0.5912 6400 8562.07 12582.15 58.59 62.72 54.98 0.5912 6600 8131.18 11650.52 59.21 62.55 56.22 0.5913 6800 10618.73 11832.74 58.46 60.77 56.32 0.5813 7000 10180.18 12106.64 59.16 61.23 57.23 0.5914 7200 10455.71 11767.56 62.46 65.60 59.60 0.6214 7400 10277.93 11417.25 61.00 61.90 60.12 0.6115 7600 10416.83 11844.74 61.50 63.19 59.90 0.6115 7800 9843.24 10815.69 60.73 63.61 58.11 0.6116 8000 10849.20 11080.88 62.16 65.61 59.05 0.6216 8200 12479.84 10464.58 60.54 63.07 58.20 0.6116 8400 11960.47 10947.46 63.05 64.79 61.39 0.6317 8600 12225.40 10741.32 63.00 64.06 61.98 0.6317 8800 11885.81 10653.15 63.88 66.43 61.52 0.6418 9000 9813.91 9519.76 62.38 65.15 59.83 0.6218 9200 11317.17 10009.74 62.36 65.20 59.77 0.6219 9400 11061.72 10646.52 62.66 63.56 61.78 0.6319 9600 11708.71 9658.76 62.61 66.30 59.31 0.6320 9800 11545.23 10812.54 64.21 65.83 62.66 0.6420 10000 12078.46 9654.99 63.09 64.35 61.88 0.6321 10200 11745.36 9246.17 61.87 64.31 59.60 0.6221 10400 11913.01 9916.31 62.74 64.24 61.30 0.6322 10600 11860.46 9340.68 64.30 66.44 62.30 0.6422 10800 13450.33 9669.23 63.20 64.48 61.98 0.6323 11000 13385.45 9062.81 63.31 65.10 61.62 0.6323 11200 13600.88 9135.41 63.88 65.94 61.95 0.6424 11400 14294.13 8782.87 63.87 65.69 62.14 0.6424 11600 18930.36 9024.00 63.06 64.11 62.04 0.6325 11800 14705.22 8806.56 63.40 66.38 60.68 0.6325 12000 17361.70 8958.72 64.71 66.28 63.22 0.6526 12200 14182.36 8224.55 64.20 66.21 62.30 0.6426 12400 15606.35 8725.44 64.23 66.68 61.95 0.6427 12600 11960.69 7855.59 64.27 64.61 63.93 0.6427 12800 12869.61 8011.05 63.80 66.58 61.23 0.6428 13000 13938.21 8064.88 64.14 65.55 62.79 0.6428 13200 12936.39 8126.91 65.23 66.64 63.87 0.6529 13400 11387.84 7295.93 64.38 64.87 63.90 0.6429 13600 15525.57 8512.57 64.52 66.23 62.89 0.6530 13800 13474.02 8028.01 65.55 67.37 63.83 0.6630 14000 16685.29 7827.30 64.15 64.61 63.70 0.6431 14200 15312.08 7759.34 65.53 66.29 64.78 0.6631 14400 16065.35 7711.75 64.03 65.93 62.24 0.6432 14600 16316.15 7407.74 65.02 66.08 64.00 0.6532 14800 16318.76 7667.86 64.97 66.60 63.41 0.6533 15000 14086.54 7523.11 64.96 68.17 62.04 0.6533 15200 16476.11 7485.34 64.86 67.14 62.73 0.6534 15400 16635.40 7954.74 64.90 66.50 63.38 0.65
✔ Saved pipeline to output directory
model-last
这篇关于spacy微调BERT-NER模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








