本文主要是介绍Raki的读paper小记:通过教师-学生模型在目标语言上的无标注数据上学习来实现单源/多源跨语言NER任务 from ACL2020,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Single-/Multi-Source Cross-Lingual NER via Teacher-Student Learning on Unlabeled Data in Target Language
不要问我为什么改成了中文名,因为标题名字太长了!!
Abstract & Introduction & Related Work
- 研究任务
通过教师-学生模型在目标语言上的无标注数据上学习来实现单源/多源跨语言NER任务 - 已有方法和相关工作
- 以前关于跨语言NER的工作大多是基于成对文本的标签投射或直接模型转移。
- 通过在可比语料库上的标签投影,为目标语言自动标注NER数据,并开发了一个启发式方案来选择高质量的投影标注的数据。
- 在短语/词的层面上翻译源语言标记的数据,以生成目标语言的成对标记的数据。
- 在源语言的标记数据上训练一个共享的NER模型,该模型具有与语言无关的特征,如跨语言的词汇表征(Devlin等人,2019),然后在目标语言上直接测试模型。
- 面临挑战
- 如果源语言中的标记数据不可用,或者没有利用目标语言中的无标记数据所包含的信息,那么这些方法就不适用
- 前者依靠源语言中的标签数据进行标签投射,因此在所需的标签数据无法获取的情况下(例如,由于隐私/敏感性问题),并不适用。同时,后者没有利用目标语言中的无标签数据,而后者的获取成本要低得多,而且可能包含非常有用的语言信息
- 创新思路
- 使用教师模型来预测软标签而不是硬标签,因为软标签能提供更多的信息
- 相比直接迁移,带有成对文本的标签投射,使用源模型来预测软性标签
 - 实验结论
- 实验结论

Methodology
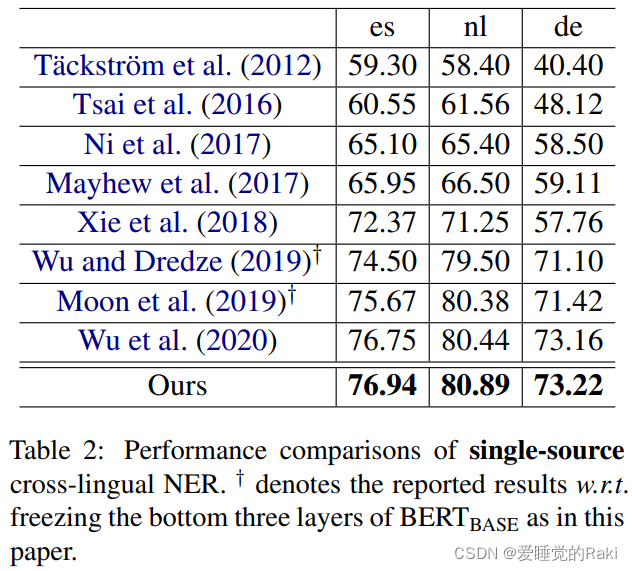
Single-Source Cross-Lingual NER
NER Model Structure
单教师的训练模型
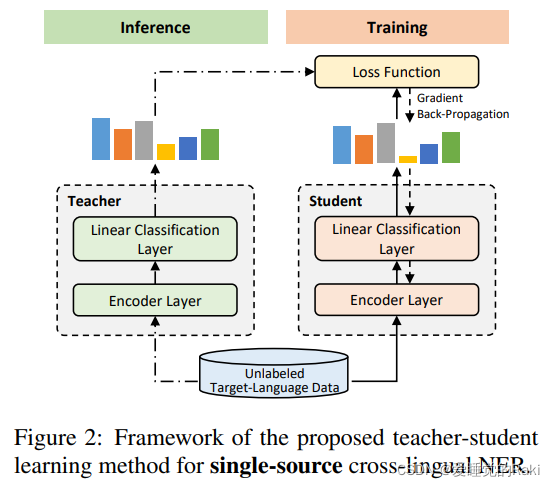
首先经过一个encoder层进行编码
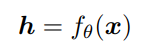
然后经过一个线性层,再通过softmax得到推理的分布
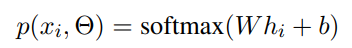
Teacher-Student Learning
Training
训练学生模型来模仿教师模型在目标语言上对实体标签的分布的输出,这样能使教师模型的知识迁移到学生模型上,而学生模型也可以利用未标记的目标语言数据中的有用的特定语言信息
学生模型和教师模型对第i个token的实体分布输出分别为:
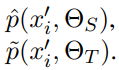
定义教师-学生模型的损失函数:
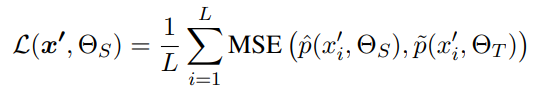
总损失:
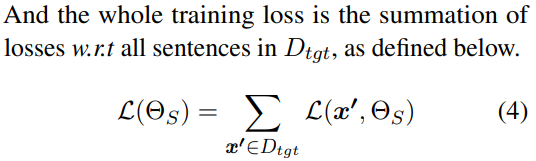
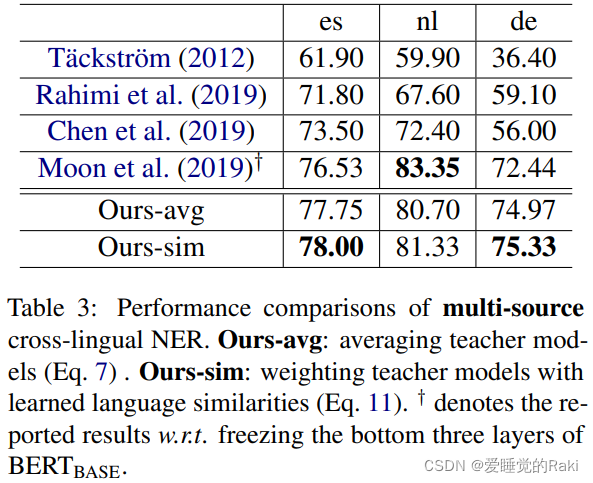
Multi-Source Cross-Lingual NER
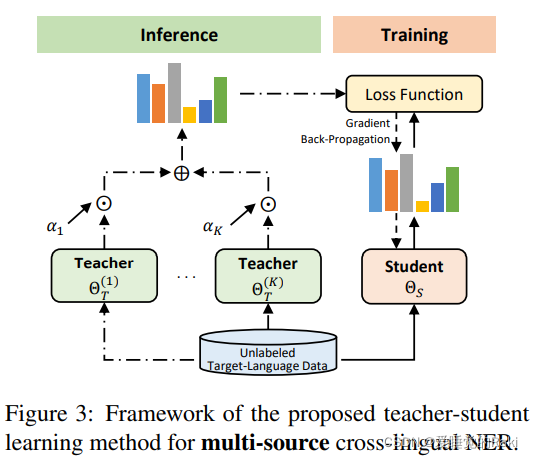
Extension to Multiple Teacher Models
k个教师模型的组合
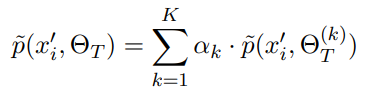
Weighting Teacher Models
源语言和目标语言相似度更高就应该分配更高的权重
Without Any Source-Language Data
平均分配
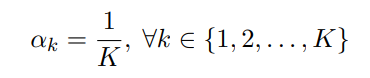
With Unlabeled Source-Language Data
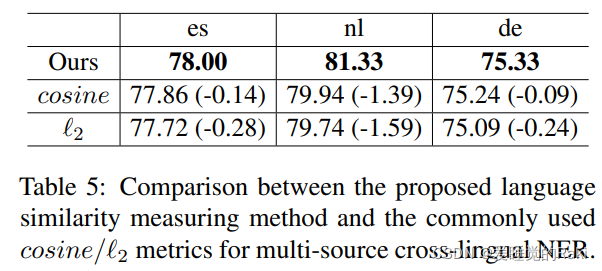
由于没有标注数据,已有的监督学习方法并不适用,在此引入一个语言辅助识别任务来计算源语言与目标语言之间的相似度,然后根据这个指标对教师模型进行加权
用一个双线性模型来对句子u和第k种语言的可学习向量 μ \mu μ 进行计算
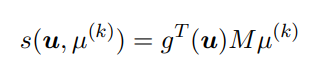

P是讲所有的 μ \mu μ 堆叠起来形成的矩阵,我们可以推导出特定语言的概率分布
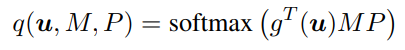
参数M和P是通过使用交叉熵损失经过训练,可以识别源语言合集中每个句子的语言
正则项鼓励语言嵌入向量的不同维度来关注不同的方面

通过softmax来计算权重参数

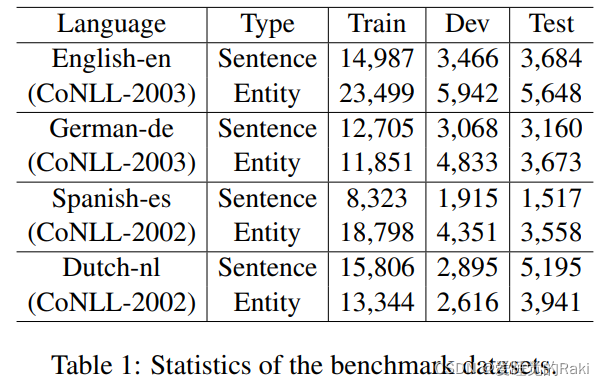
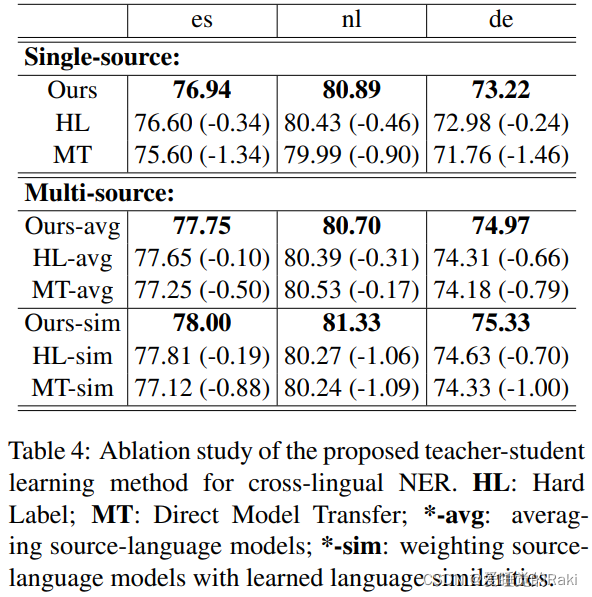
Experiments


Conclusion
在本文中,我们提出了一种用于单/多源跨语言NER的师生学习方法,通过使用源语言模型作为教师,在目标语言的未标记数据上训练学生模型。该方法不依赖于源语言的标记数据,能够利用未标记的目标语言数据中的额外信息,这解决了以前基于标签投影和基于模型转移的方法的局限性。我们还提出了一种基于语言识别的语言相似性测量方法,以更好地衡量不同的教师模型。在基准数据集上进行的大量实验表明,我们的方法优于现有的sota
Remark
截止2022年2月7,这篇paper的方法在Cross-Lingual NER on CoNLL German数据集上仍然是sota,说明这个方法确实蛮有效的,整整一年也没有新sota出来(可能是做这个方向的人少?),总之novelty感觉算是中规中矩,模型还算简单,个人认为是蛮不错的一篇paper
这篇关于Raki的读paper小记:通过教师-学生模型在目标语言上的无标注数据上学习来实现单源/多源跨语言NER任务 from ACL2020的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


