namenode专题

使用SecondaryNameNode恢复NameNode的数据
1)需求: NameNode进程挂了并且存储的数据也丢失了,如何恢复NameNode 此种方式恢复的数据可能存在小部分数据的丢失。 2)故障模拟 (1)kill -9 NameNode进程 [lytfly@hadoop102 current]$ kill -9 19886 (2)删除NameNode存储的数据(/opt/module/hadoop-3.1.4/data/tmp/dfs/na

NameNode内存生产配置
Hadoop2.x 系列,配置 NameNode 内存 NameNode 内存默认 2000m ,如果服务器内存 4G , NameNode 内存可以配置 3g 。在 hadoop-env.sh 文件中配置如下。 HADOOP_NAMENODE_OPTS=-Xmx3072m Hadoop3.x 系列,配置 Nam

【Hadoop|HDFS篇】NameNode和SecondaryNameNode
1. NN和2NN的工作机制 思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访 问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在 内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的 Fslmage。 这样又会带来新的问题,当在内存中的元数据更新时,如

Hadoop Namenode元数据持久化机制与SecondaryNamenode的作用详解
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 我们都知道namenode是用来存储元数据的,他并不是用来存储真正的数据。 那么他的元数据怎么进行持久化呢! FsImage 文件系统的镜像文件叫fsImage,它包括了文件和块信息的映射,还有文件系统的属性信息。 datan

NameNode 的 Web 界面
http://127.0.0.1:50070/ 图片显示的是Hadoop的Web界面导航栏。导航栏包含以下选项: Hadoop:Hadoop的主页。Overview:集群的概览信息。Datanodes:数据节点的状态和信息。Datanode Volume Failures:数据节点的卷故障信息。Snapshot:快照信息。Startup Progress:启动进度信息。Utilit

Trino大量查询会导致HDFS namenode主备频繁切换吗?
会,且肯定会 一、背景 今天还没起床就被智能运维叫醒了,说通过namenode审计日志查看访问源ip有我们的trino集群,并且访问量比较大,起床气范了,这不很正常吗,早上一般都是跑批高峰,也不一定是我们trino的问题,必须按时上班。 到了工位联系运维,被告知也不一定是我们的trino引起的namenode主备节点切换,因为那个时间段,有很多系统会访问大数据平台,不管怎样,既然有警告就得排查,

handoop0.20.2:名字节点namenode的启动
注:分析到的主要代码在 org.apache.hadoop.hdfs.server.namenode.NameNode和org.apache.hadoop.hdfs.server.namenode.FSNamesystem中 1.NameNode.main()是名字节点启动的入口,主要就是通过createNameNode方法创建一个namenode对象,创建成功后再等待它执行结束(nam

Hadoop运行中NameNode闪退和运行mapreducer时卡在Running job.....
开始安装Hadoop时 第一次成功启动 包括MapReducer程序也能成功运行。后来不知道什么原因 进入了Safe mode 即使退出了安全模式照样不能对HDFS进行任何修改操作,索性hdfs namenode -format格式化一下,连启动都无法启动了,修改NameNode和DataNode的clusterID一致后 虽然修改HDFS问题解决了,但是运行任务时总是卡在了Running jo
namenode启动失败 。 : Cannot assign requested address
Cannot assign requested address 我部署hadoop 格式化后 , start-all.sh . 通过 jps 命令发现 datanode 可以启动 。 然而那么namenode启动失败。 网上找了好多博客贴吧 。 1 有的是 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Faile
hadoop启动过程(一) NameNode
一、第一次启动 NameNode 内存 本地磁盘 fsimage edits 格式化HDFS,目的是审查隔行fsimage format fsimage start namenode read fsimage start datanode 注册 block report 进行操作的时候 create dir -> write [edit
DataNode 和 NameNode
在 Apache Hadoop 的分布式文件系统 (HDFS) 中,DataNode 和 NameNode 是两个核心组件,它们共同协作以实现大规模数据存储和管理的功能。下面我将详细介绍这两个组件的作用和职责。 NameNode NameNode 是 HDFS 的主节点 (Master node),负责管理文件系统的命名空间和元数据。它的主要职责包括: 元数据管理: NameNode 存储
hadoop安全模式(rm: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot delete /sort. Name )
https://blog.csdn.net/world_java/article/details/17754369 hadoop 关闭安全模式,因为安全模式无法操作上传,修改等
namenode和jobTracker进程没起来的原因
namenode和jobTracker进程没起来的原因有许多种: 1、启动时没有先格式化; 2、4个配置文件没有配置正确; 3、hostnaame与ip没有绑定; 4、ssh免密码登陆没有配置成功; 5、多次格式化hadoop造成的错误; (其中由多次格式化造成的错误,可以通过删除/usr/local/hadoop/tmp 的hadoop的临时文件,然后重新格式化来解决。)
修改NameNode端口后,hive表查询报错
https://www.cnblogs.com/zhangXingSheng/p/7073584.html 修改NameNode端口后,hive表查询报错 在进行使用hive查询表数据的时候,抛出异常 hive> select*from blackList;FAILED: SemanticException Unable to determine if hdfs://node1

Hadoop的namenode的管理机制,工作机制和datanode的工作原理
Hadoop的namenode的管理机制,工作机制和datanode的工作原理 HDFS前言: 1) 设计思想 分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析; 2)在大数据系统中作用: 为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务 3)重点概念:文件切块
Spark对多HDFS集群Namenode HA的支持
具体的配置需要参考core-site.xml和hdfs-site.xml val sc = new SparkContext()// 多个HDFS的相同配置sc.hadoopConfiguration.setStrings("fs.defaultFS", "hdfs://cluster1", "hdfs://cluster2");sc.hadoopConfiguration.setStri
Hadoop 2.0 中 NameNode/ResourceManager HA 总结
本文部分转自 董的博客《Hadoop 2.0中单点故障解决方案总结》 一 为什么需要 HA 和 Federation 1 单点故障2 集群容量和集群性能 二 Hadoop 20 三个系统简介 1 HDFS 基础架构2 YARN 基础架构3 MapReduce 三 Hadoop HA 架构 1 HDFS 的 HA 架构2 YARN 的 HA 架构3 Hadoop HA 解决方案架构4 构成
hadoop-3.1.3 启动HDFS时报错ERROR: Attempting to operate on hdfs namenode as root的解决方法
今天在使用hadoop时遇到了下面这个问题,看报错信息是用户问题,于是上网查了下解决方案,找到两种方式,我使用的是方法1,下面将两种方式都列给大家参考。 报错场景: hadoop-3.1.3 启动HDFS时报错,具体错误信息如下: [root@hadoop10 hadoop-3.1.3]# sbin/start-dfs.sh Starting namenodes on [hadoop
hadoop:no namenode to stop及其他
在重隔几个月后重新启动hadoop时,发现namenode启动不了(在bin/stop-all.sh时提示no namenode to stop),上网搜寻no namenode to stop 发现各种各样的解决问题的方法,例如format namenode...等等,发现都不管用。自己还是不够耐心,一气之下就把hadoop和cygwin和jdk全部重装了一遍。下面记录下需要注意的一
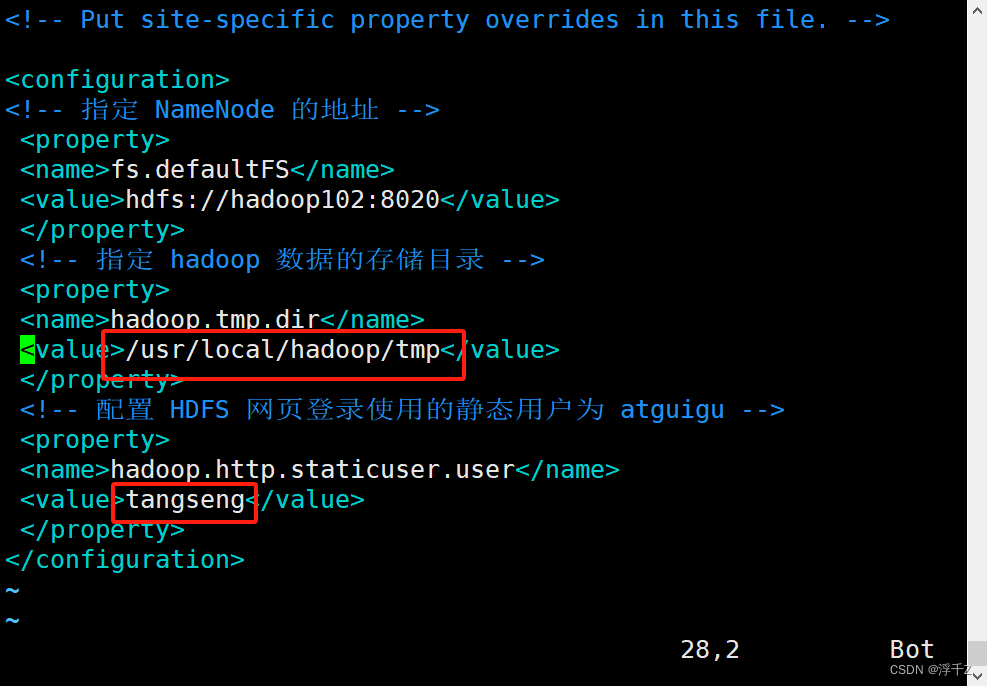
namenode启动失败 org.apache.hadoop.hdfs.server.common.InconsistentFSStateException:
小白的Hadoop学习笔记 2024/5/14 18:26 文章目录 问题解决报错浅浅分析一下core-ste.xml 问题 namenode启动失败 读日志 安装目录下 vim /usr/local/hadoop/logs/hadoop-tangseng-namenode-hadoop102.log 2024-05-14 00:22:46,262 E
在搭建好Hadoop集群后,namenode与datanode两个过程不能起来,或者一个启动之后另一个自动关闭
故障现像: 此故障可以算是在换电脑搭集群后最多的故障了,首先是从节点上相关进程都没起来,后来又是进程起来后从节点上datanode节点没起来,最后是datanode进程起来之后,主节点上namenode进程又没起来。此故障看起来一波三折,实际上在理解好相关原理后,解决起来要比第一个故障轻松一些。 解决思路: 原理为先:首先要找到对应关系,主节点上namenod
Hadoop Namenode不能启动 dfs/name is in an inconsistent
Hadoop Namenode不能启动 dfs/name is in an inconsistent 前段时间自己的本机上搭的Hadoop环境(按文档的伪分布式),第一天还一切正常,后来发现每次重新开机以后都不能正常启动, 在start-dfs.sh之后jps一下发现namenode不能正常启动,按提示找到logs目录下namenode的启动log发现如下异常 org.
Hadoop格式化namenode出错
我们在对Hadoop进行格式化时 很有可能会出现以下错误 输入命令:hadoop namenode -format 报错信息:-bash:hadoop:command not found 我们总结的最主要原因有三个 Hadoop的环境变量是否配置 配置以后是否使其生效 vim /etc/profile source /etc/profile 2.
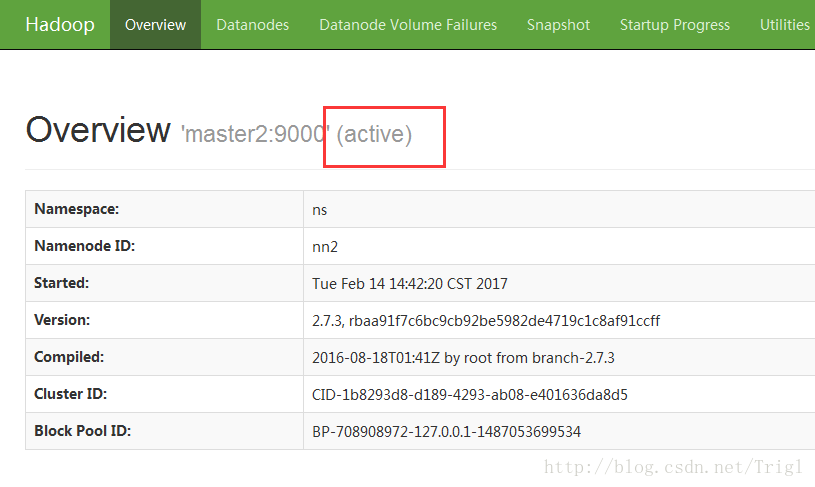
Hadoop双namenode配置搭建(HA)
配置双namenode的目的就是为了防错,防止一个namenode挂掉数据丢失,具体原理本文不详细讲解,这里只说明具体的安装过程。 Hadoop HA的搭建是基于Zookeeper的,关于Zookeeper的搭建可以查看这里 hadoop、zookeeper、hbase、spark集群环境搭建 ,本文可以看做是这篇文章的补充。这里讲一下Hadoop配置安装。 配置Hadoop文件 需要修改的
【HDFS】namenode如何根据输入的文件(路径)名找到对应的inode的?
大家都用过 hadoop dfs -ls/rmr/rm/get/put/cat等命令,后面跟的都是一个字符串形式的文件绝对路径/a/b/c/d这样的玩意,那么namenode如何根据你输入的/a/b/c/d这样字符串格式的东西找到对应的文件呢? 我们都知道文件对应的inodefile,目录对应inodeDirectory,它们都是inode, abstract class INode
datenode节点超时时间设置,Hadoop启动不正常,HDFS冗余数据块的自动删除,NameNode安全模式问题,ntp时间服务同步,机架感知配置
1.Hadoop datanode节点超时时间设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为: timeout = 2 * heartbeat.rec