本文主要是介绍Hadoop格式化namenode出错,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们在对Hadoop进行格式化时 很有可能会出现以下错误
输入命令:hadoop namenode -format
报错信息:-bash:hadoop:command not found
我们总结的最主要原因有三个

-
Hadoop的环境变量是否配置 配置以后是否使其生效
vim /etc/profile

source /etc/profile
2.我们要明确Hadoop的安装目录 在配置环境变量的时候 我们是否将安装目录填错
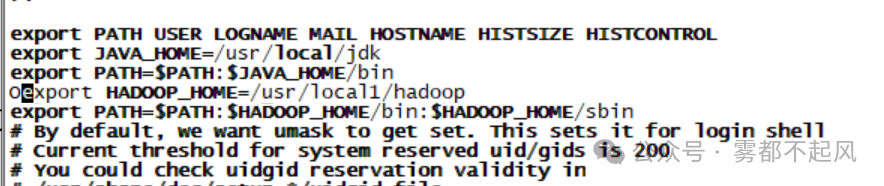
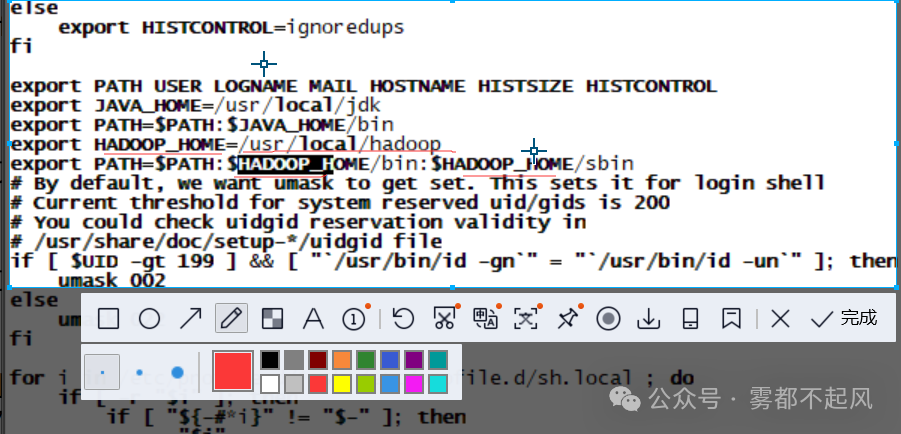
3.最容易出错也是最不容易发现的错误 我们在配置环境变量时 要注意输入的字母 路径是否正确 比如 local 打成了 lcoal 字母输入错误是我们很有可能出现的错误 但是很难被发现
编程中遇到问题是再正常不过的事情了。有时候代码会出现错误,程序可能无法正常运行,但这并不意味着你失败了。相反,这是学习和成长的机会!
当你遇到问题时,可以采取以下步骤来解决它们:
1. 冷静下来:遇到问题时不要惊慌,保持冷静,放松心情。焦虑和压力只会让问题变得更加棘手。
2. 仔细阅读错误信息:编程语言和开发工具通常会提供有用的错误信息,仔细阅读并理解它们有助于找到问题所在。
3. 检查代码:仔细检查你的代码,看看是否有拼写错误、语法错误或逻辑错误。有时候问题就隐藏在代码的某个角落。
4. 查找解决方案:利用搜索引擎、论坛、社区等资源来查找解决方案。很可能有其他人已经遇到过类似的问题,并且提供了解决方法。
5. 寻求帮助:如果你无法解决问题,不要犹豫向他人寻求帮助。可以向同事、老师、论坛或社区提问,他们可能会提供有益的建议和指导。
6. 学习和成长:每次解决一个问题,都是对自己编程能力的提升和加深理解的过程。不断学习、积累经验,你会变得越来越强大!
记住,每个优秀的程序员都曾经遇到过无数次的问题,但正是通过不断地解决这些问题,他们才变得更加优秀和有经验。所以,不要害怕问题,勇敢面对并克服它们,你会成长为一个更加优秀的程序员!
这篇关于Hadoop格式化namenode出错的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








