本文主要是介绍Hadoop双namenode配置搭建(HA),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
配置双namenode的目的就是为了防错,防止一个namenode挂掉数据丢失,具体原理本文不详细讲解,这里只说明具体的安装过程。
Hadoop HA的搭建是基于Zookeeper的,关于Zookeeper的搭建可以查看这里 hadoop、zookeeper、hbase、spark集群环境搭建 ,本文可以看做是这篇文章的补充。这里讲一下Hadoop配置安装。
配置Hadoop文件
需要修改的配置文件在$HADOOP_HOME/etc/hadoop目录下面,具体修改内容如下:
core-site.xml
<!-- 指定hdfs的nameservice为ns --><property><name>fs.defaultFS</name><value>hdfs://ns</value></property><!--指定hadoop数据临时存放目录--><property><name>hadoop.tmp.dir</name><value>/data/install/hadoop-2.7.3/temp</value></property><property><name>io.file.buffer.size</name><value>4096</value></property><!--指定zookeeper地址--><property><name>ha.zookeeper.quorum</name><value>master1:2181,master2:2181,slave1:2181,slave2:2181,slave3:2181</value></property>hdfs-site.xml
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 --><property><name>dfs.nameservices</name><value>ns</value></property><!-- ns下面有两个NameNode,分别是nn1,nn2 --><property><name>dfs.ha.namenodes.ns</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.ns.nn1</name><value>master1:9000</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.ns.nn1</name><value>master1:50070</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.ns.nn2</name><value>master2:9000</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.ns.nn2</name><value>master2:50070</value></property><!-- 指定NameNode的元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://slave1:8485;slave2:8485;slave3:8485/ns</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><property><name>dfs.journalnode.edits.dir</name><value>/data/install/hadoop-2.7.3/journal</value></property><!-- 开启NameNode故障时自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置失败自动切换实现方式 --><property><name>dfs.client.failover.proxy.provider.ns</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 --><property><name>dfs.ha.fencing.methods</name><value>sshfence(hadoop:22022)</value></property><!-- 使用隔离机制时需要ssh免登陆 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property><property><name>dfs.namenode.name.dir</name><value>file:/data/install/hadoop-2.7.3/hdfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/data/install/hadoop-2.7.3/hdfs/data</value></property><property><name>dfs.replication</name><value>2</value></property><!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 --><property><name>dfs.webhdfs.enabled</name><value>true</value></property>mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value></property>yarn-site.xml
<!-- 指定nodemanager启动时加载server的方式为shuffle server --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><!-- 指定resourcemanager地址 --><property><name>yarn.resourcemanager.hostname</name><value>master1</value></property>hadoop-env.sh添加如下内容
export JAVA_HOME=/data/install/jdk
# ssh端口非默认22端口
export HADOOP_SSH_OPTS="-p 22022"yarn-env.sh添加如下内容
export JAVA_HOME=/data/install/jdk启动命令
注意首次初始化启动命令和之后启动的命令是不同的,首次启动比较复杂,步骤不对的话就会报错,不过之后就好了
首次启动命令
1、首先启动各个节点的Zookeeper,在各个节点上执行以下命令:
bin/zkServer.sh start2、在某一个namenode节点执行如下命令,创建命名空间
hdfs zkfc -formatZK3、在每个journalnode节点用如下命令启动journalnode
sbin/hadoop-daemon.sh start journalnode4、在主namenode节点格式化namenode和journalnode目录
hdfs namenode -format ns5、在主namenode节点启动namenode进程
sbin/hadoop-daemon.sh start namenode6、在备namenode节点执行第一行命令,这个是把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了!然后用第二个命令启动备namenode进程!
hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode7、在两个namenode节点都执行以下命令
sbin/hadoop-daemon.sh start zkfc8、在所有datanode节点都执行以下命令启动datanode
sbin/hadoop-daemon.sh start datanode日常启停命令
sbin/start-dfs.sh
sbin/stop-dfs.sh测试验证
首先在浏览器分别打开两个节点的namenode状态,其中一个显示active,另一个显示standby
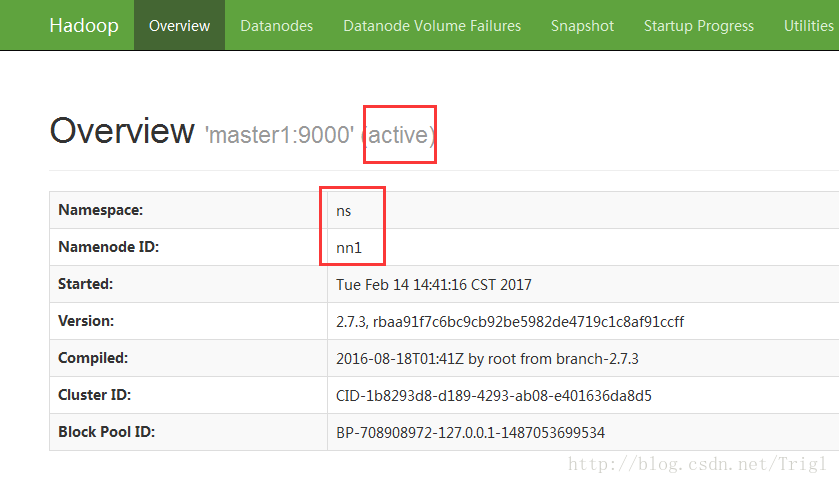
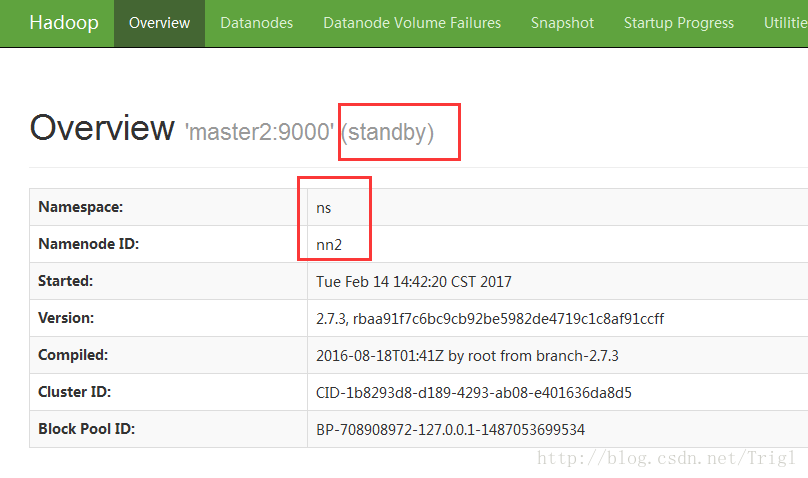
然后在active所在的namenode节点执行jps,杀掉相应的namenode进程
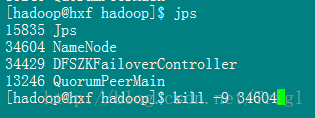
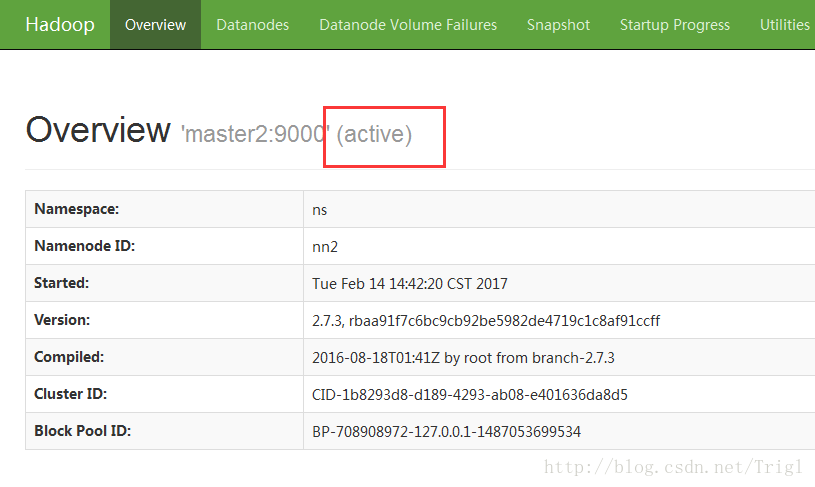
前面standby所对应的namenode变成active
2017-03-05更新
Hadoop配置了HA,Spark也需要更改一些配置,否则会报java.net.UnknownHostException的错误,就是在$SPARK_HOME/conf/spark-defaults.conf内添加如下内容:
spark.files file:///data/install/hadoop-2.7.3/etc/hadoop/hdfs-site.xml,file:///data/install/hadoop-2.7.3/etc/hadoop/core-site.xmlMen were born to be suffering, the pain of struggle, or the pain of regret?
这篇关于Hadoop双namenode配置搭建(HA)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





