ha专题

VMware8实现高可用(HA)集群
陈科肇 =========== 操作系统:中标麒麟高级操作系统V6 x86-64 实现软件:中标麒麟高可用集群软件 ======================== 1.环境的规划与配置 硬件要求 服务器服务器至少需要 2 台,每台服务器至少需要 2 块网卡以做心跳与连接公网使用存储环境 建议使用一台 SAN/NAS/ISCSI 存储作为数据共享存储空间 软

快看 | Java连接集成Kerberos的HA HDFS方案
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 来源:http://suo.im/5SGnSD 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 在实施方案前,假设读者已经基本熟悉以下技术 (不细说) Java,mavenhdfs,kerberos 方案实施 最后目录大概如下新建maven工程,pom.xml配置, 添加

多平台融合——数据库HA(一)
需求背景:在K8S集群中创建的微服务要使用浪潮云超融合上的数据库资源,为减少两个平台之间的耦合度,同时确保系统整体的可用性和安全性,做如下设计: 1、建立数据库主从集群,并将超融合中mariadb数据库视为主数据库,负责原平台的写入和读取业务,同时为其建立HA,确保主库的高可用性; 2、在K8S容器中建立多副本的mariadb数据库,并将其视为从数据库,与主数据库建立主从复制机制,确保数据的一

HA里面如何添加美的智能设备
环境: Home Assistant 2023.8.0 问题描述: HA里面如何添加美的智能设备 解决方案: 1.打开 HACS 菜单,点开其中的集成选项,点击右下角的“浏览并下载存储库”,之后再搜索 Midea AC LAN 点击下载 如果下载不了要手动下载 将最新版本中的所有 custom_components/midea_ac_lan 文件复制到您的 /custom_compon
Kubernetes学习指南:保姆级实操手册05——配置集群HA负载均衡
五、Kubernetes学习指南:保姆级实操手册05——配置集群HA负载均衡 简介: Keepalived 提供 VRRP 实现,并允许您配置 Linux 机器使负载均衡,预防单点故障。HAProxy 提供可靠、高性能的负载均衡,能与 Keepalived 完美配合 1、配置Keepalive 官方文档提供了两种运行方式(此案例使用选项1): 选项1:在操作系统上运行服务选项2:将服务作为

hdfs2.x HA搭建
官档:http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html node01免秘钥控制node02、node03、node04 node02免秘钥控制node01 zkfc自动故障转移 原因:若nn01 active 挂了 需要把nn02

【Redis】HA-高可用
简述 虽然Redis的主从复制可以实现数据的备份,保障数据的安全,但是还不能实现高可用,需要手动故障转移,因此Master仍然可能存在单点故障,为此Redis提供了Sentinel(哨兵)模式来实现高可用。 Redis Sentinel 提供以下功能: Monitoring(监控):Sentinel会不断检查Master和Slave是否正常工作;Notification(通知):Se
Hadoop2.x HDFS HA架构部署配置
一、HA简介 在Hadoop2.x之前,HDFS集群中只有一个NameNode,若NameNode出现了故障,则整个集群将无法使用,直到NameNode重新启动。 Hadoop2.x开始支持HA和Federation。HDFS HA功能通过配置Active/Standby两个NameNode实现集群中对NameNode的热备。如果Active出现故障,则Standby可快速替代

hadoop HA (高可用 high available)的搭建
hadoop HA 的搭建 hadoop HA 需求来源为什么要搭建hadoop HA?如何实现高可用?如何写入zookeeper数据? hadoop HA 的搭建:搭建准备开始搭建启动集群 hadoop HA 需求来源 为什么要搭建hadoop HA? 在hadoop 2.0之前,整个hdfs集群中只有一个nn,所以一旦nn节点宕机,则整个集群无法使用。这种现象称为单

Hadoop的HA配置与实现(ZooKeeper)
目录 一、Hadoop的HA架构二、配置实现Hadoop的HA三、效果 一、Hadoop的HA架构 集群规划 112:NameNode1 ResourceManager1 JournalNode1 113:NameNode2 ResourceManager2 JournalNode2 114:DataNode1 NodeManager1 115:DataNode2 NodeMa

大数据技术之_07_Hadoop学习_HDFS_HA(高可用)_HA概述+HDFS-HA工作机制+HDFS-HA集群配置+YARN-HA配置+HDFS Federation(联邦) 架构设计
大数据技术之_07_Hadoop学习_HDFS_HA(高可用) 第8章 HDFS HA 高可用8.1 HA概述8.2 HDFS-HA工作机制8.2.1 HDFS-HA工作要点8.2.2 HDFS-HA手动故障转移工作机制8.2.3 HDFS-HA自动故障转移工作机制 8.3 HDFS-HA集群配置8.3.1 环境准备8.3.2 规划集群8.3.3 配置Zookeeper集群8.3.4 配置H

redis分布式及HA部署文档
本文就官方redis分布式的部署进行总结说明,redis分布式中集成了高可用HA功能,依次进行说明,现对redis的分布式部署做以下总结。 下载redis版本 官方下载地址:http://download.redis.io/releases/redis-3.2.4.tar.gzredis编译 解压redis-3.2.4.tar.gz包,进入到redis-3.2.4 我一般添加快捷方式:ln

如何配置Hadoop2.0HDFS的HA以及联邦使用QJM
配置过程详述 大家从官网下载的apache hadoop2.2.0的代码是32位操作系统下编译的,不能使用64位的jdk。我下面部署的hadoop代码是自己的64位机器上重新编译过的。服务器都是64位的,本配置尽量模拟真实环境。大家可以以32位的操作系统做练习,这是没关系的。关于基本环境的详细配置,大家可以观看我的视频,或者浏览吴超沉思录的相关文章。 在这里我们选
Cluster className=org.apache.catalina.ha.tcp.SimpleTcpCluster 各个节点意思
<!-- Cluster(集群,族) 节点,如果你要配置tomcat集群,则需要使用此节点.className 表示tomcat集群时,之间相互传递信息使用那个类来实现信息之间的传递.channelSendOptions可以设置为2、4、8、10,每个数字代表一种方式2 = Channel.SEND_OPTIONS_USE_ACK(确认发送)4 = Channel.SEND_OPTIONS_SYN
Hadoop 3.X HA集群部署
准备工作 1、确认各个服务器网络是否互通、时间是否同步 2、确认各个节点部署那些组件 ip地址host名部署组件192.168.190.130h202406131 NameNode ResourceManager QuorumPeerMain JournalNode DFSZKFailoverController JobHistoryServer 192.168.190.131h2024

Hadoop2.x配置HA
各节点配置参考表 主机NameNodeDataNodeZookeeperZKFCJournalNodeResourceManagerNodeManagernode11111node2111111node31111node4111 文件配置: core-site.xml <property><name>hadoop.tmp.dir</name><value>/csh/hadoop/h
Elasticsearch 7.6.0 最详细安装及配置(HA)安装与启动
Elasticsearch 7.6.0 最详细安装及配置(HA)安装与启动 Elasticsearch是一个非常好用的搜索引擎,和Solr一样,他们都是基于倒排索引的。今天我们就看一看Elasticsearch如何进行安装。 下载和安装 今天我们的目的是搭建一个有3个节点的Elasticsearch集群,所以我们找了3台虚拟机,ip分别是: 192.168.73.130192.168
Spark对多HDFS集群Namenode HA的支持
具体的配置需要参考core-site.xml和hdfs-site.xml val sc = new SparkContext()// 多个HDFS的相同配置sc.hadoopConfiguration.setStrings("fs.defaultFS", "hdfs://cluster1", "hdfs://cluster2");sc.hadoopConfiguration.setStri
Hadoop 2.0 中 NameNode/ResourceManager HA 总结
本文部分转自 董的博客《Hadoop 2.0中单点故障解决方案总结》 一 为什么需要 HA 和 Federation 1 单点故障2 集群容量和集群性能 二 Hadoop 20 三个系统简介 1 HDFS 基础架构2 YARN 基础架构3 MapReduce 三 Hadoop HA 架构 1 HDFS 的 HA 架构2 YARN 的 HA 架构3 Hadoop HA 解决方案架构4 构成
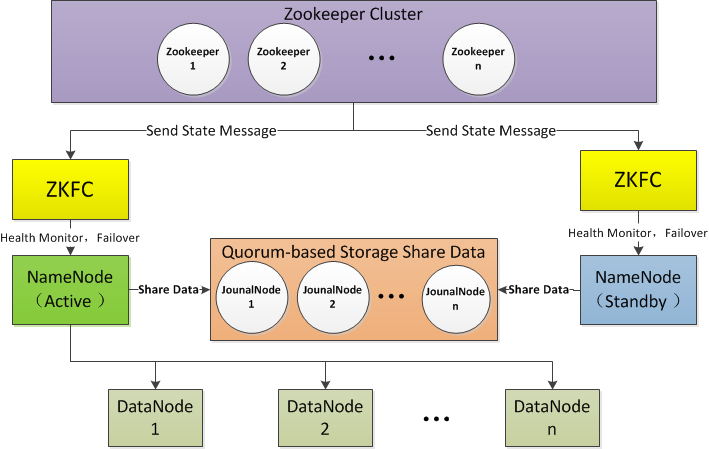
HDFS 和 YARN 的 HA 故障切换
一 非 HDFS HA 集群转换成 HA 集群二 HDFS 的 HA 自动切换命令 1 获得当前 NameNode 的 active 和 standby 状态2 NameNode 的 active 和 standby 状态切换3 HDFS HA自动切换比手工切换多出来的步骤 三 ResourceManager 的 HA 自动切换命令 1 获得当前 RM 的 active 和 standby
Linux集群之HA(高可用集群)篇
LVS+Keepalive网络结构: IP备注120.10.10.10ipvsadm master120.10.10.11ipvsadm slave120.10.10.12web1120.10.10.13web2 1、搭建LVS DR模式,见上一篇文章Linux集群之LB(负载均衡集群)篇 2、高可用搭建 使用Keepalived实现高可用 主副节点Keepalived设置 vi /etc/k
redis从单机到HA高可用集群的部署策略总结
最近在研究redis的部署,看了很多方案,现在总结一下 单机模式 最初接触redis,用的就是单机模式,最简单的一种模式,client直接访问1个redis服务。 优点:入门级,部署简单。 缺点:负载量小、容量小、容灾差。 客户端分片模式 客户端分片也是常见的一种模式,就是有多个redis服务,利用客户端的机制将数据存储到不同的redis服务中,然后从不同的redis服务中读取。 优点
分布式7:Hadoop+zookeeper实现HA
集群规划 zk01——zk05,5台centos zk01——zk05部署了5个zookeeper zk01为namenode节点 zk05为namenode的HA节点 zk02、zk03、zk04为datanode节点搭建过程 修改主机名,hosts 搭建5台zookeeper,启动后5台机器都要zkServer.sh status查看状态,如果有启动没成功的节点,先
分布式6:HA的概念
ha是High Available缩写,是双机集群系统简称,指高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点 定义 HA(High Available),高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。通常把正在执行业务的称为活动节点,而作为活动节点的一个备份的则称为备用节点。当活动节点出现问题
esx ha 配置警告原因和解决办法
工作环境:VMware vSphere 5.0 ,vCenter Server 5.0 此主机当前没有管理网络冗余 VMware vSphere 5.0配置完成Cluster的HA后在主机的摘要栏提示“此主机当前没有管理网络冗余”,我的环境中服务器都是单网卡,也没有做多余的Management Network。只好通过以下方法解决。 1.右键点击Cluster选中 编辑设置。

ranger配置ha高可用方案
变更影响面 变更完需要重启所有组件 配置lb(需要客户侧配置并提供LB地址) 转发方式选择ip hash(哈希) 监听端口为6080 协议为tcp 配置后端监听