本文主要是介绍HDFS 和 YARN 的 HA 故障切换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 一 非 HDFS HA 集群转换成 HA 集群
- 二 HDFS 的 HA 自动切换命令
- 1 获得当前 NameNode 的 active 和 standby 状态
- 2 NameNode 的 active 和 standby 状态切换
- 3 HDFS HA自动切换比手工切换多出来的步骤
- 三 ResourceManager 的 HA 自动切换命令
- 1 获得当前 RM 的 active 和 standby 状态
- 2 RM 的 active 和 standby 状态切换
- 3 yarn rmadmin 所支持的命令
- 4 YARN HA自动切换比手工切换多出来的步骤
- 四 HDFS HA 故障切换后欲恢复原 active NameNode 步骤
一. 非 HDFS HA 集群转换成 HA 集群
1. 分别启动所有的 journalnode 进程,在其中一台 NameNode 上完成即可(比如 NameNode1)
$HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode2. 在 NameNode1上对 journalnode 的共享数据进行初始化,然后启动 namenode 进程
$HADOOP_HOME/bin/hdfs namenode -initializeSharedEdits
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode3. 在 NameNode2 上同步 journalnode 的共享数据,和 NameNode 上存放的元数据,然后启动 namenode 进程
$HADOOP_HOME/bin/hdfs namenode -bootstrapStandby
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode4. 在其中一台 NameNode 上启动所有的 datanode 进程
$HADOOP_HOME/sbin/hadoop-daemon.sh start datanode二. HDFS 的 HA 自动切换命令
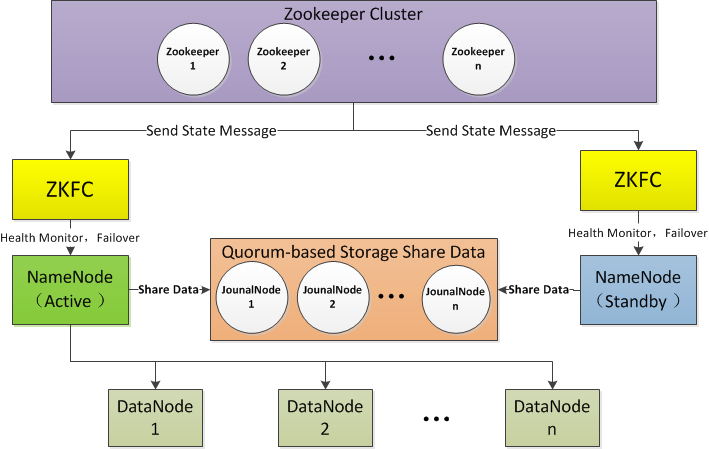
说明: 为了更加通俗的说明,笔者将两台运行 namenode 进程的主机名抽象为 NameNode1 和 NameNode2,笔者更倾向 NameNode1 上的运行的是 active 状态的 namenode 进程,NameNode2 上的运行的是 standby状态的 namenode 进程,而实际操作中,master5 就是这个 NameNode1 ,master52 就是这个 NameNode2。
| 抽象主机名 | 实际操作主机名 | 初始状态 | 理想稳定状态 |
|---|---|---|---|
| NameNode1 | master5 | standby | active |
| NameNode2 | master52 | standby | standby |
2.1 获得当前 NameNode 的 active 和 standby 状态
当未启动 ZK 服务时,发现两个 NameNode 都是 standby 的状态,通过以下命令可以查得:
hdfs haadmin 这篇关于HDFS 和 YARN 的 HA 故障切换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








