本文主要是介绍namenode启动失败 org.apache.hadoop.hdfs.server.common.InconsistentFSStateException:,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小白的Hadoop学习笔记 2024/5/14 18:26
问题
namenode启动失败
读日志
安装目录下
vim /usr/local/hadoop/logs/hadoop-tangseng-namenode-hadoop102.log
2024-05-14 00:22:46,262 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /usr/local/hadoop/data/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:327)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:215)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:975)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:681)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:584)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:644)
at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:811)
at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:795)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1488)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1554)
2024-05-14 00:22:46,264 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1
2024-05-14 00:22:46,271 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG:
解决
目录写错了,Hadoop的数据存储目录写错了
下面是正确的,原来写的是/usr/local/hadoop/data
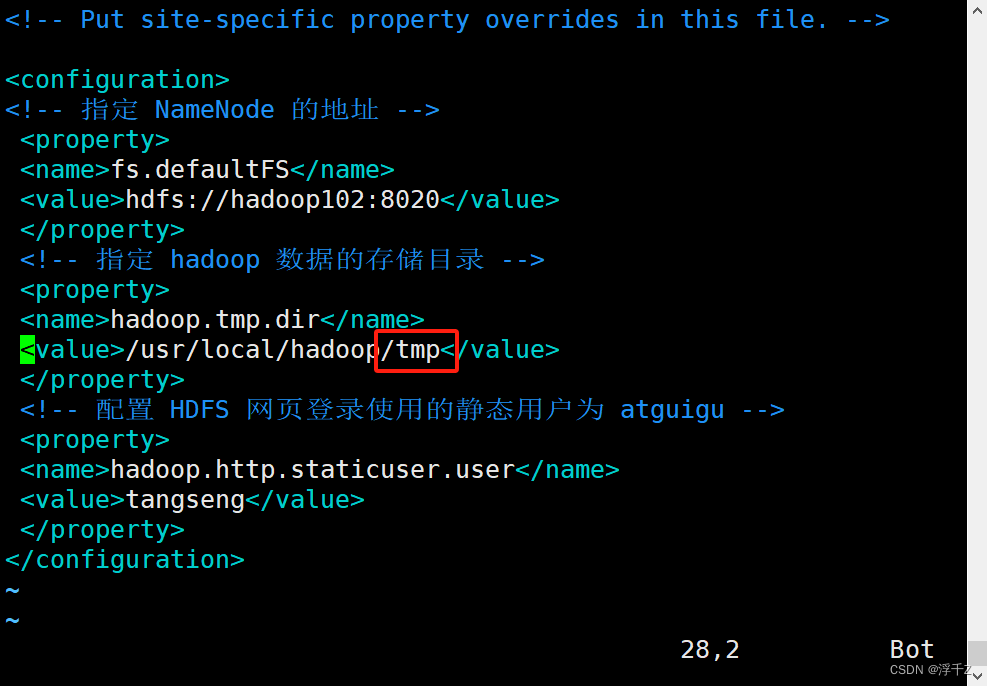
报错
浅浅分析一下
我是跟这个视频学的
31_尚硅谷_Hadoop_入门_群起集群并测试_哔哩哔哩_bilibili
对比我的和视频的
core-ste.xml
视频的
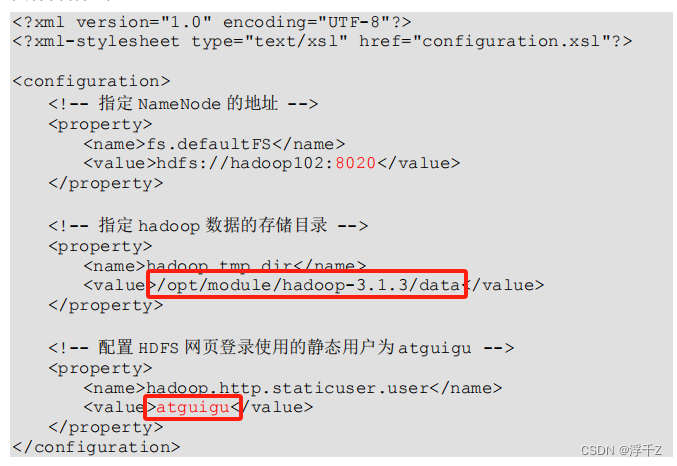
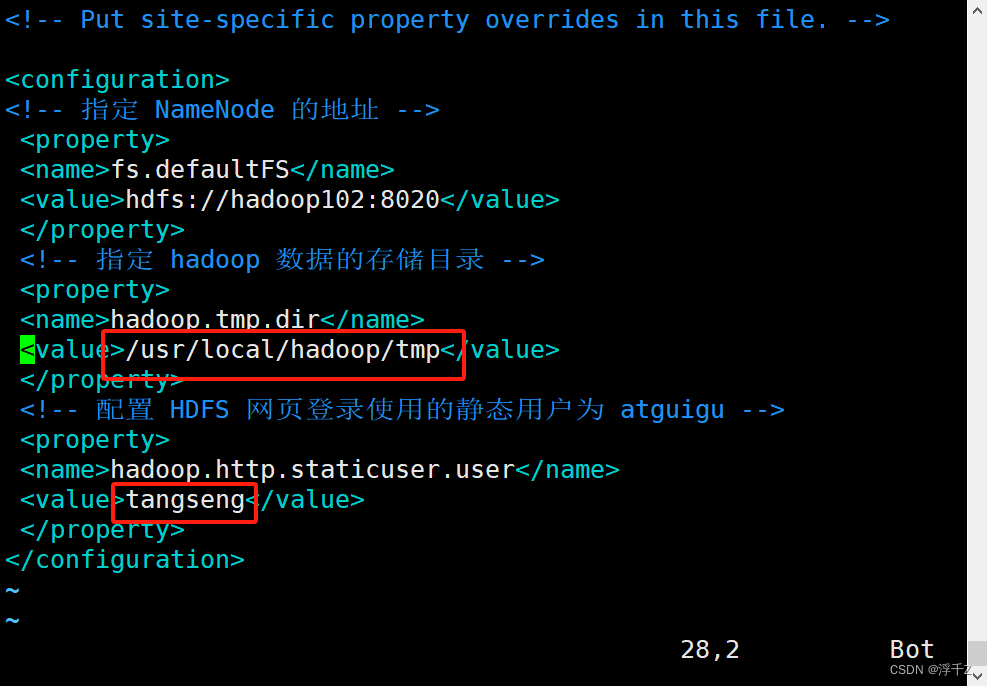
我的
我之前使用过,是存在tmp目录下
这篇关于namenode启动失败 org.apache.hadoop.hdfs.server.common.InconsistentFSStateException:的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








