mixture专题

【大模型理论篇】Mixture of Experts(混合专家模型, MOE)
1. MoE的特点及为什么会出现MoE 1.1 MoE特点 Mixture of Experts(MoE,专家混合)【1】架构是一种神经网络架构,旨在通过有效分配计算负载来扩展模型规模。MoE架构通过在推理和训练过程中仅使用部分“专家”(子模型),优化了资源利用率,从而能够处理复杂任务。 在具体介绍MoE之前,先抛出MoE的一些表现【2】: 与密集模型相

【论文阅读】MOA,《Mixture-of-Agents Enhances Large Language Model Capabilities》
前面大概了解了Together AI的新研究MoA,比较好奇具体的实现方法,所以再来看一下对应的文章论文。 论文:《Mixture-of-Agents Enhances Large Language Model Capabilities》 论文链接:https://arxiv.org/html/2406.04692v1 这篇文章的标题是《Mixture-of-Agents Enhances
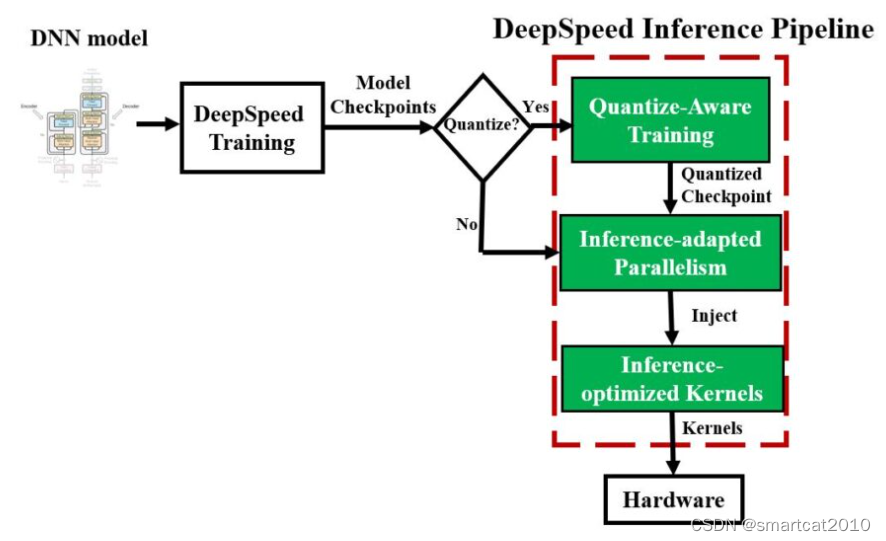
DeepSpeed Mixture-of-Quantization (MoQ)
属于QAT (Quantization-Aware Training)的一种,训练阶段用量化。 特点是: 1. 从16-bit INT开始训练,逐渐减1bit,训练一些steps就减1bit,直至减至8bit INT; 2. (可选,不一定非用)多久减1bit,这个策略,使用模型参数的二阶特征来决定,每层独立的(同一时刻,每层的特征值们大小不一致,也就造成bit减少速度不一致,造成bit数目
![[阅读笔记20][BTX]Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM](https://img-blog.csdnimg.cn/direct/8751e7253f134d69b3387fceb546fff5.png)
[阅读笔记20][BTX]Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
这篇论文是meta在24年3月发表的,它提出的BTX结构融合了BTM和MoE的优点,既能保证各专家模型训练时的高度并行,又是一个统一的单个模型,可以进一步微调。 这篇论文研究了以高效方法训练LLM使其获得各领域专家的能力,例如写代码、数学推理以及自然知识。现有的融合多个专家模型的方法有Branch-Train-Merge和Mixture-of-Experts,前者BTM各专家模型在不

聚类(1)——混合高斯模型 Gaussian Mixture Model
聚类系列: 聚类(序)----监督学习与无监督学习 聚类(1)----混合高斯模型 Gaussian Mixture Model 聚类(2)----层次聚类 Hierarchical Clustering 聚类(3)----谱聚类 Spectral Clustering -------------------------------- 聚类的方法有很多种,k-means要

mmoe/Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
文章目录 总结细节实验 总结 每个task分开emb,每个task分开attention 细节 现有的方法对任务间的relationship敏感 MTL 改进1: 不使用shared-bottom,使用单独的参数,但是加一个多个task参数之间的L2正则 shared-bottom,共用emb,每个任务上再套一个tower network。这种做法可以降低overf
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
本文来自DataLearnerAI官方网站: MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051702125462162 MistralAI是一家法国的大模型初创企业,其202

21-高斯混合模型-GMM(Gaussian Mixture Model)
文章目录 1.高斯混合模型GMM的定义1.1高斯混合模型GMM的几何表示1.2高斯混合模型GMM的模型表示2.高斯混合模型的极大似然估计2.1 数据样本的定义 3.高斯混合模型GMM(EM期望最大算法求解)3.1 EM算法(E-Step)3.2 EM算法(E-Step-高斯混合模型代入)3.2 EM算法(M-Step) 1.高斯混合模型GMM的定义 高斯混合模型中的高斯就是指的
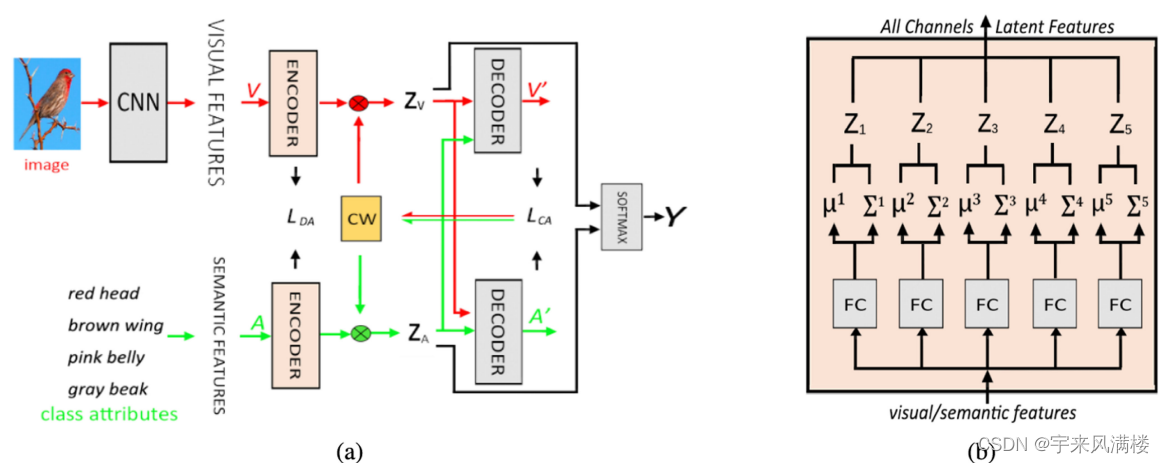
Generalized Zero-Shot Learning With Multi-Channel Gaussian Mixture VAE
L D A _{DA} DA最大化编码后两种特征分布之间的相似性 辅助信息 作者未提供代码
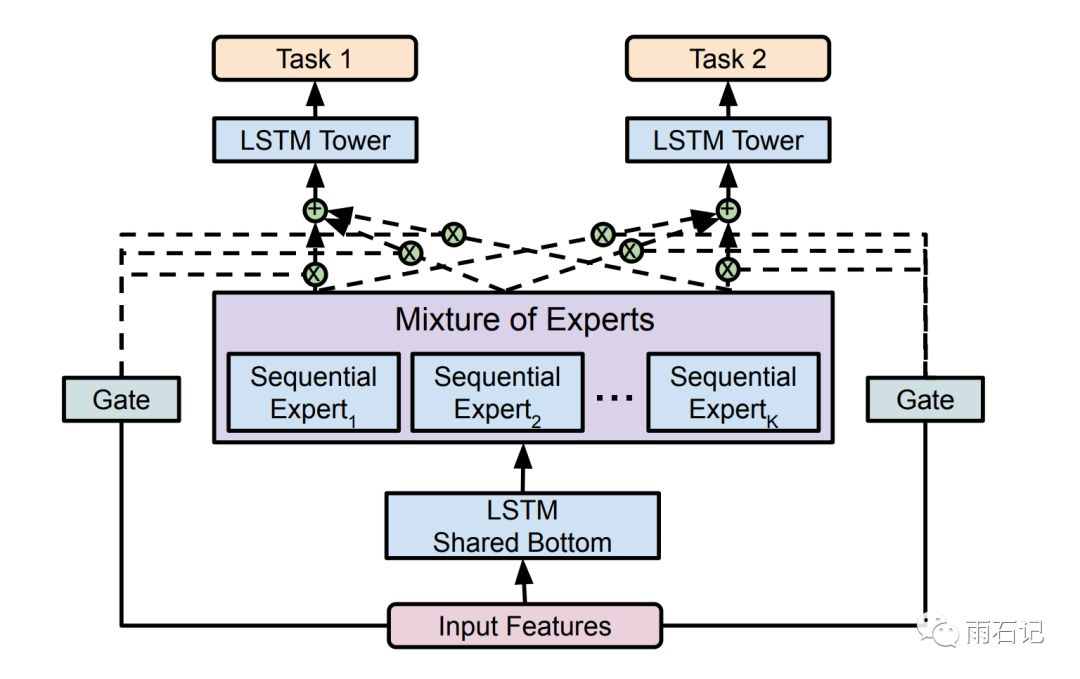
混合专家模型 Mixture-of-Experts (MoE)
大纲 Mixture-of-Experts (MoE)Mixture of Sequential Experts(MoSE)Multi-gate Mixture-of-Experts (MMoE) 一、MoE 1. MoE架构 MoE(Mixture of Experts)层包含一个门网络(Gating Network)和n个专家网络(Expert Network)。对于每一个输入,动态地

混合密度模型Mixture Density Networks
翻译并简化自:http://blog.otoro.net/2015/11/24/mixture-density-networks-with-tensorflow/?tdsourcetag=s_pctim_aiomsg notebook地址: http://otoro.net/ml/ipynb/mixture/mixture.html 原文的TF代码+版本微调,和本人用Keras复现的,代码见 h
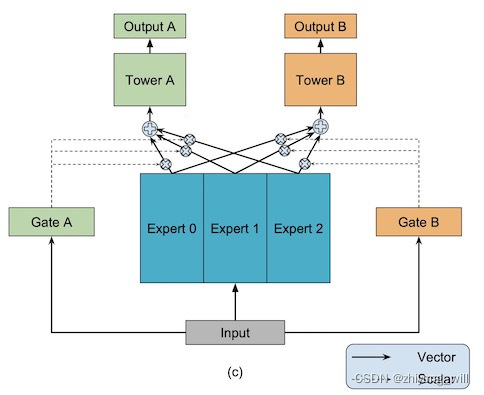
Multi-gate Mixture-of-Experts(MMoE)
1. 概述 在工业界经常会面对多个学习目标的场景,如在推荐系统中,除了要给用户推荐刚兴趣的物品之外,一些细化的指标,包括点击率,转化率,浏览时长等等,都会作为评判推荐系统效果好坏的重要指标,不同的是在不同的场景下对不同指标的要求不一样而已。在面对这种多任务的场景,最简单最直接的方法是针对每一个任务训练一个模型,显而易见,这种方式带来了巨大的成本开销,包括了计算成本和存储成本。多任务学习(Mult
解决 No module named ‘sklearn.mixture._gaussian_mixture‘
该问题是scikit-learn的版本导致的,安装其他版本的scikit-learn即可解决问题。部分scikit的是sklearn.mixture.gaussian_mixture,gaussian前面没有下划线_。 pip uninstall scikit-learnpip install scikit-learn==0.23.2
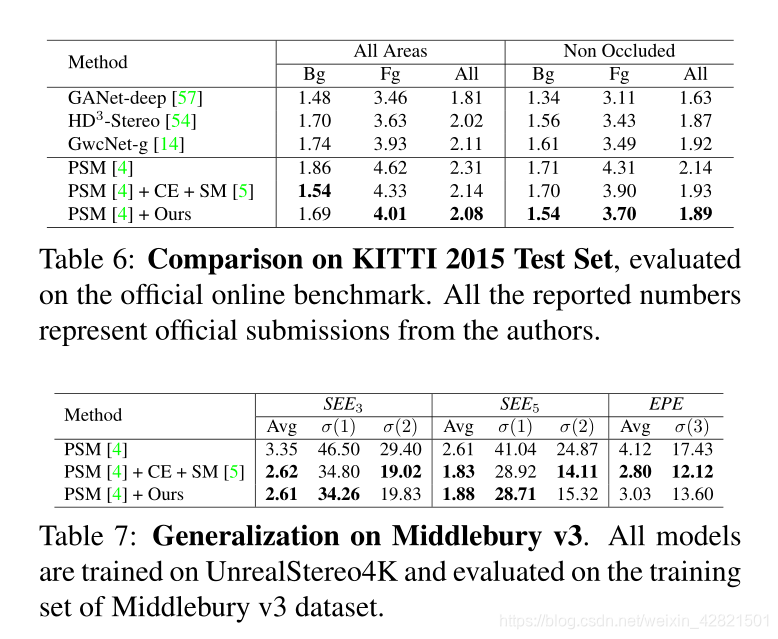
SMD-Nets: Stereo Mixture Density Networks
paper | project Abstract 尽管在过去的几年中,深度学习大大提高了立体匹配的精度,但有效地恢复尖锐边界和高分辨率输出仍然具有挑战性。在本文中,我们提出了立体混合密度网络(Stereo Mixture Density Networks, SMD-Nets),这是一种简单而有效的学习框架,可与广泛的2D和3D体系结构兼容,改善了这两个问题。 具体来说,我们利用双峰混合密度作

【Python】机器学习笔记10-高斯混合模型(Gaussian Mixture Model)
本文的参考资料:《Python数据科学手册》; 本文的源代上传到了Gitee上; 本文用到的包: %matplotlib inlineimport numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom matplotlib.patches import Ellips
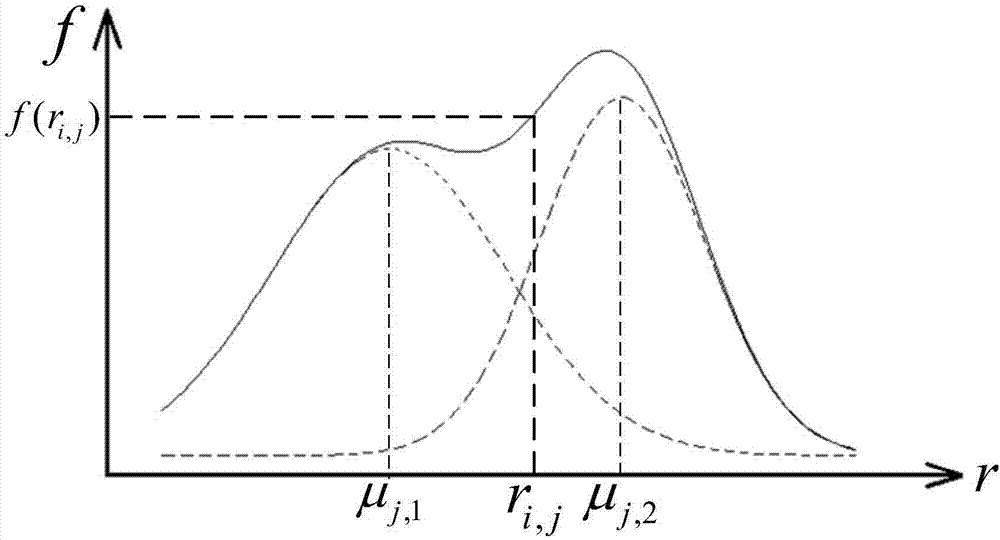
Gaussian Mixture Model 高斯混合模型 GMM
Gaussian Mixture Model 高斯混合模型 GMM Gaussian mixture model is a combine of multiple Gaussian models. These Gaussian models mixture according to ‘weight’ π \pi π. The picture is a mixture of two mo