本文主要是介绍MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文来自DataLearnerAI官方网站:
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般! | 数据学习者官方网站(Datalearner)![]() https://www.datalearner.com/blog/1051702125462162
https://www.datalearner.com/blog/1051702125462162
MistralAI是一家法国的大模型初创企业,其2023年9月份发布的Mistral-7B模型声称是70亿参数规模模型中最强大的模型,并且由于其商用友好的开源协议,吸引了很多的关注。在昨晚,MistralAI突然在推特上公布了一个磁力下载链接,而下载之后大家发现这是一个基于混合专家的大模型这是由8个70亿参数规模专家网络组成的混合模型(Mixture of Experts,MoE,混合专家网络)。

而这也可能是目前全球首个基于MoE架构开源的大语言模型(如果有漏掉,欢迎补充~)。另外,Mistral-8x7B-MoE已经上架DataLearnerAI模型信息卡,欢迎关注后续的开源地址和技术报告分析:Mistral-7B-MoE(Mistral-7B-MoE)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习 (DataLearner)
- 混合专家网络(Mixture of Experts,MoE)简介
- Mistral-8x7B-MoE简介
- Mistral-7B-MoE(mixtral-8x7b-32kseqlen)实际评测
- FireworksAI已经上架mixtral-8x7b-32kseqlen
- mixtral-8x7b-32kseqlen实际问答测试结果
- mixtral-8x7b-32kseqlen的评测结果
- Mistral-8x7B-MoE运行的资源
Mistral-8x7B-MoE简介
MistralAI目前没有公布Mistral-7B-MoE这个模型的其它细节,而根据公布的磁力下载链接中的文件夹名称,这个模型目前也被称为mixtral-8x7b-32kseqlen。
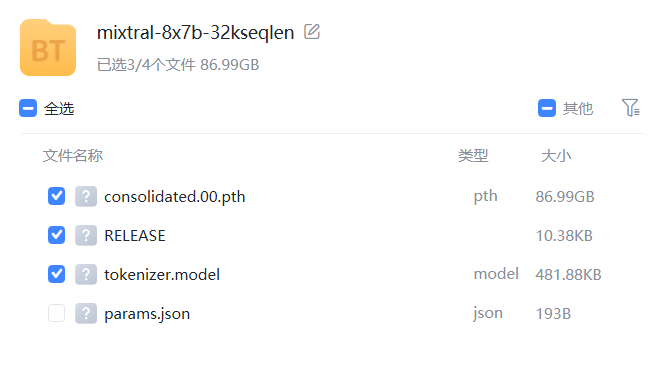
从上图可以看到,这个模型的预训练结果大小为86.99GB,这意味着单个专家网络大小在10.9GB左右,比此前开源的Mistral-7B(Mistral-7B模型信息卡地址:Mistral 7B(Mistral 7B)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习 (DataLearner) )小不少(Mistral-7B模型为15GB左右)。
而这个模型参数的具体配置如下:
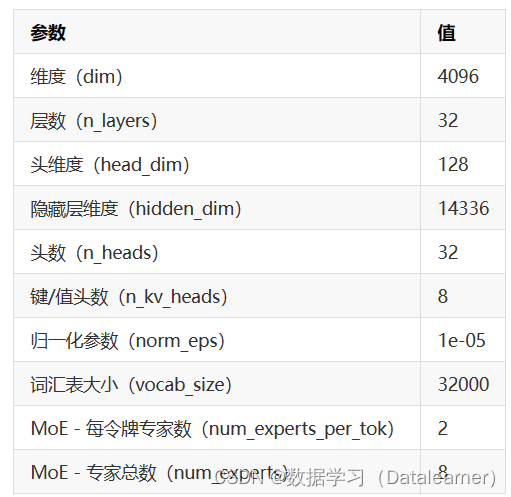
这个配置结果看,这个模型是8个专家混合而成,而输入的时候每个token分给2个专家处理。注意,这个模型的词汇表大小是32000,与LLaMA2模型是一样的。
而模型配置说维度是4096,但是文件夹命名是32k序列长度,应该是单个专家网络4K,8个一起可以处理32K输入!
目前,除了这些参数外,官方没有公布技术文档或者博客介绍,但是吸引了大量的关注和讨论,着实是一个营销的好案例。
Mistral-7B-MoE(mixtral-8x7b-32kseqlen)实际评测
尽管Mistral AI目前没有给出除了模型下载链接外的任何信息,但是这个模型吸引了社区的大量注意。因为这可能是目前已知的全球首个完整的基于MoE架构的大语言模型。因此,已经有很多人开始测试了。而其它用户的其它评测基准表现也是只比Mistral-7B好10-20%左右,提升十分有限,非常奇怪!
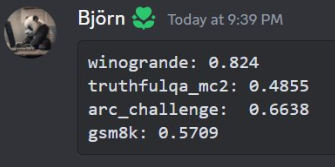
具体的测试结果参考原文:MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般! | 数据学习者官方网站(Datalearner)
Mistral-8x7B-MoE已经上架DataLearnerAI模型信息卡,欢迎关注后续的开源地址和技术报告分析:Mistral-7B-MoE(Mistral-7B-MoE)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习 (DataLearner)
关于Mistral-8x7B-MoE的其它信息目前还没有看到,期待官方给出技术细节~
这篇关于MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






