experts专题

【大模型理论篇】Mixture of Experts(混合专家模型, MOE)
1. MoE的特点及为什么会出现MoE 1.1 MoE特点 Mixture of Experts(MoE,专家混合)【1】架构是一种神经网络架构,旨在通过有效分配计算负载来扩展模型规模。MoE架构通过在推理和训练过程中仅使用部分“专家”(子模型),优化了资源利用率,从而能够处理复杂任务。 在具体介绍MoE之前,先抛出MoE的一些表现【2】: 与密集模型相
![[论文笔记]Mixtral of Experts](https://img-blog.csdnimg.cn/img_convert/b06b142a1959182b9b6723bbcd6914ba.png)
[论文笔记]Mixtral of Experts
引言 今天带来大名鼎鼎的Mixtral of Experts的论文笔记,即Mixtral-8x7B。 作者提出了Mixtral 8x7B,一种稀疏专家混合(Sparse Mixture of Experts,SMoE)语言模型。Mixtral与Mistral 7B具有相同的架构,不同之处在于每个层由8个前馈块(即专家)组成。对于每个令牌(Token),在每个层中,路由器网络选择两个专家处理当前

Datacamp 笔记代码 Machine Learning with the Experts: School Budgets 第三章 Improving your model
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 22 (3) Exercise Instantiate pipeline In order to mak

Datacamp 笔记代码 Machine Learning with the Experts: School Budgets 第二章 Creating a simple first model
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 22 (2) Exercise Setting up a train-test split in scik
![[阅读笔记20][BTX]Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM](https://img-blog.csdnimg.cn/direct/8751e7253f134d69b3387fceb546fff5.png)
[阅读笔记20][BTX]Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
这篇论文是meta在24年3月发表的,它提出的BTX结构融合了BTM和MoE的优点,既能保证各专家模型训练时的高度并行,又是一个统一的单个模型,可以进一步微调。 这篇论文研究了以高效方法训练LLM使其获得各领域专家的能力,例如写代码、数学推理以及自然知识。现有的融合多个专家模型的方法有Branch-Train-Merge和Mixture-of-Experts,前者BTM各专家模型在不

最强开源模型 Mixtral-8x7B-Instruct-v0.1 详细介绍:稀疏 Mixtral of experts
LLM votes 评测排行榜: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard 模型链接: https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1

从rookie到基佬~017:BEIT-3基础概念解析-Modality experts
一天一个变弯小技巧 今日份洗脑: Modality experts概念解析 结论:Modality experts指专门处理特定类型数据(或称为"模态")的专家模型或专家网络 涉及研究内容: 原文:Wang W, Bao H, Dong L, et al. Image as a Foreign Language: BEiT Pretraining for All Vision and Vi

论文系列之-Mixtral of Experts
Q: 这篇论文试图解决什么问题? A: 这篇论文介绍了Mixtral 8x7B,这是一个稀疏混合专家(Sparse Mixture of Experts,SMoE)语言模型。它试图解决的主要问题包括: 1. 提高模型性能:通过使用稀疏混合专家结构,Mixtral在多个基准测试中超越或匹配了现有的大型模型(如Llama 2 70B和GPT-3.5),尤其是在数学、代码生成和多语言理解任务上。2.

mmoe/Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
文章目录 总结细节实验 总结 每个task分开emb,每个task分开attention 细节 现有的方法对任务间的relationship敏感 MTL 改进1: 不使用shared-bottom,使用单独的参数,但是加一个多个task参数之间的L2正则 shared-bottom,共用emb,每个任务上再套一个tower network。这种做法可以降低overf
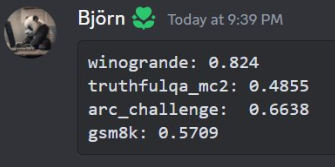
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
本文来自DataLearnerAI官方网站: MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051702125462162 MistralAI是一家法国的大模型初创企业,其202
TensorFlow官方教程学习 Deep MNIST for Experts
写在前面的话 其实有人组织了翻译TensorFlow文档,在github上的项目,但是我还是比较喜欢看原始的文档,边看边写,纯粹自娱自乐,也是看看自己是否真的认真看了并且有些理解了。 开始正文 TensorFlow是一个对于大规模数字计算十分强力的库。其使命之一就是实现和训练深度神经网络。在这个教程中我们将会学习建立一个深度卷积MNIST分类器的TensorFlow模型的基本步骤。 这个介
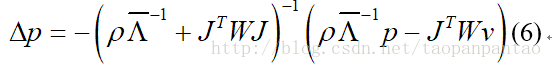
【翻译】Convolutional Experts Network for Facial Landmark Detection
【翻译】Convolutional Experts Network for Facial Landmark Detection 摘要: 约束局部模型(CLM)是一个成熟的面部标记点检测方法系列。然而他们最近不如 级联回归 方法流行。这部分是由于现有CLM局部检测器无法对表情,照明,面部毛发,化妆等影响的非常复杂的标记点外观进行建模。我们提出了一种新颖的局部检测器 - 卷积专家网络(CEN),它将
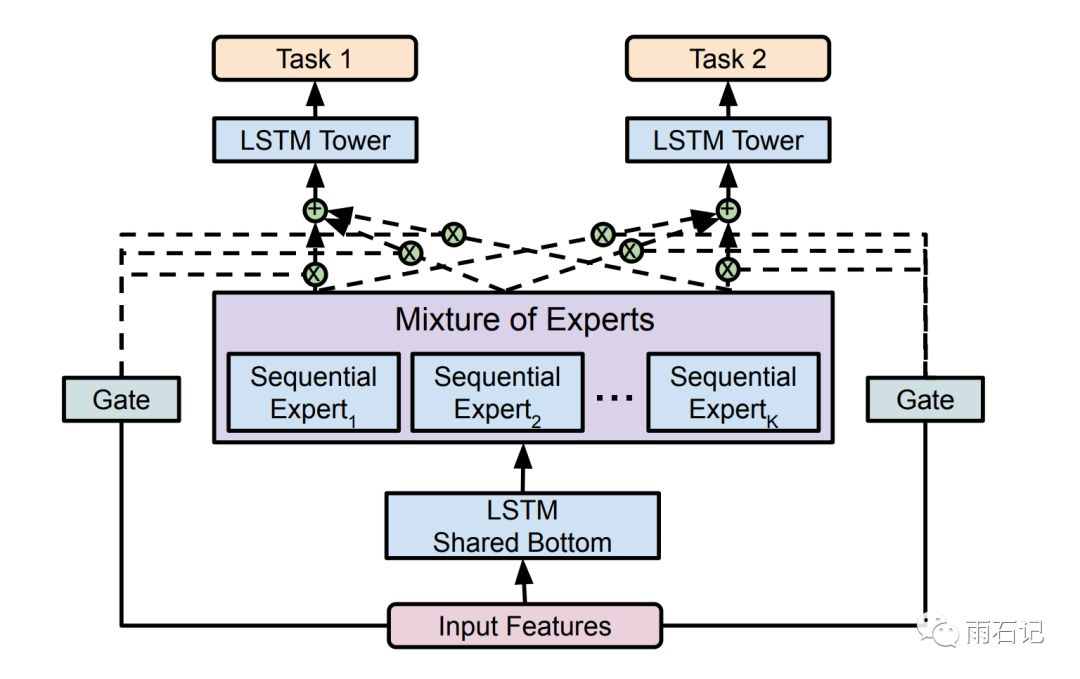
混合专家模型 Mixture-of-Experts (MoE)
大纲 Mixture-of-Experts (MoE)Mixture of Sequential Experts(MoSE)Multi-gate Mixture-of-Experts (MMoE) 一、MoE 1. MoE架构 MoE(Mixture of Experts)层包含一个门网络(Gating Network)和n个专家网络(Expert Network)。对于每一个输入,动态地
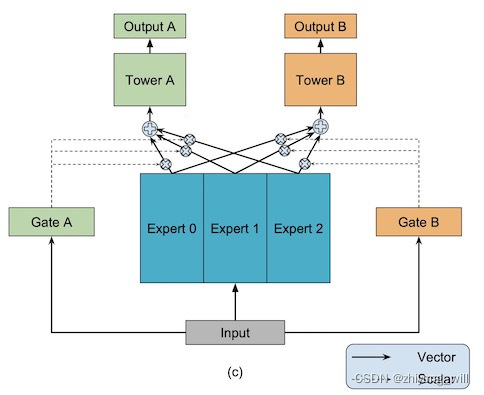
Multi-gate Mixture-of-Experts(MMoE)
1. 概述 在工业界经常会面对多个学习目标的场景,如在推荐系统中,除了要给用户推荐刚兴趣的物品之外,一些细化的指标,包括点击率,转化率,浏览时长等等,都会作为评判推荐系统效果好坏的重要指标,不同的是在不同的场景下对不同指标的要求不一样而已。在面对这种多任务的场景,最简单最直接的方法是针对每一个任务训练一个模型,显而易见,这种方式带来了巨大的成本开销,包括了计算成本和存储成本。多任务学习(Mult