metrics专题

图解可观测Metrics, tracing, and logging
最近在看Gophercon大会PPT的时候无意中看到了关于Metrics,Tracing和Logging相关的一篇文章,凑巧这些我基本都接触过,也是去年后半年到现在一直在做和研究的东西。从去年的关于Metrics的goappmonitor,到今年在排查问题时脑洞的基于log全链路(Tracing)追踪系统的设计,正好是对这三个话题的实践。这不禁让我对它们的关系进行思考:Metrics和Loggi

prometheus删除指定metrics下收集的值
Prometheus 删除指定 Metric 官方文档: - https://prometheus.io/docs/prometheus/latest/querying/api/#tsdb-admin-apis Prometheus 的管理 API 接口,官方到现在一共提供了三个接口,对应的分别是快照功能、数据删除功能、数据清理功能,想要使用 API 需要先添加启动参数 --web.en

Flink实战(七十二):监控(四)自定义metrics相关指标(二)
项目实现代码举例: 添加自定义监控指标,以flink1.5的Kafka读取以及写入为例,添加rps、dirtyData等相关指标信息。�kafka读取和写入重点是先拿到RuntimeContex初始化指标,并传递给要使用的序列类,通过重写序列化和反序列化方法,来更新指标信息。 不加指标的kafka数据读取、写入Demo。 public class FlinkEtlTest {priv
Flink实战(七十一):监控(三)自定义metrics相关指标(一)
0 简介 User-defined Metrics 除了系统的 Metrics 之外,Flink 支持自定义 Metrics ,即 User-defined Metrics。上文说的都是系统框架方面,对于自己的业务逻辑也可以用 Metrics 来暴露一些指标,以便进行监控。 User-defined Metrics 现在提及的都是 datastream 的 API,table、sql 可

Flink实战:监控(一)Metrics监控原理与实战
什么是 Metrics? Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志,比如作业很大或者有很多作业的情况下,该如何处理?此时 Metrics 可以很好的帮助开发人员了解作业的当前状况。 Metric Type
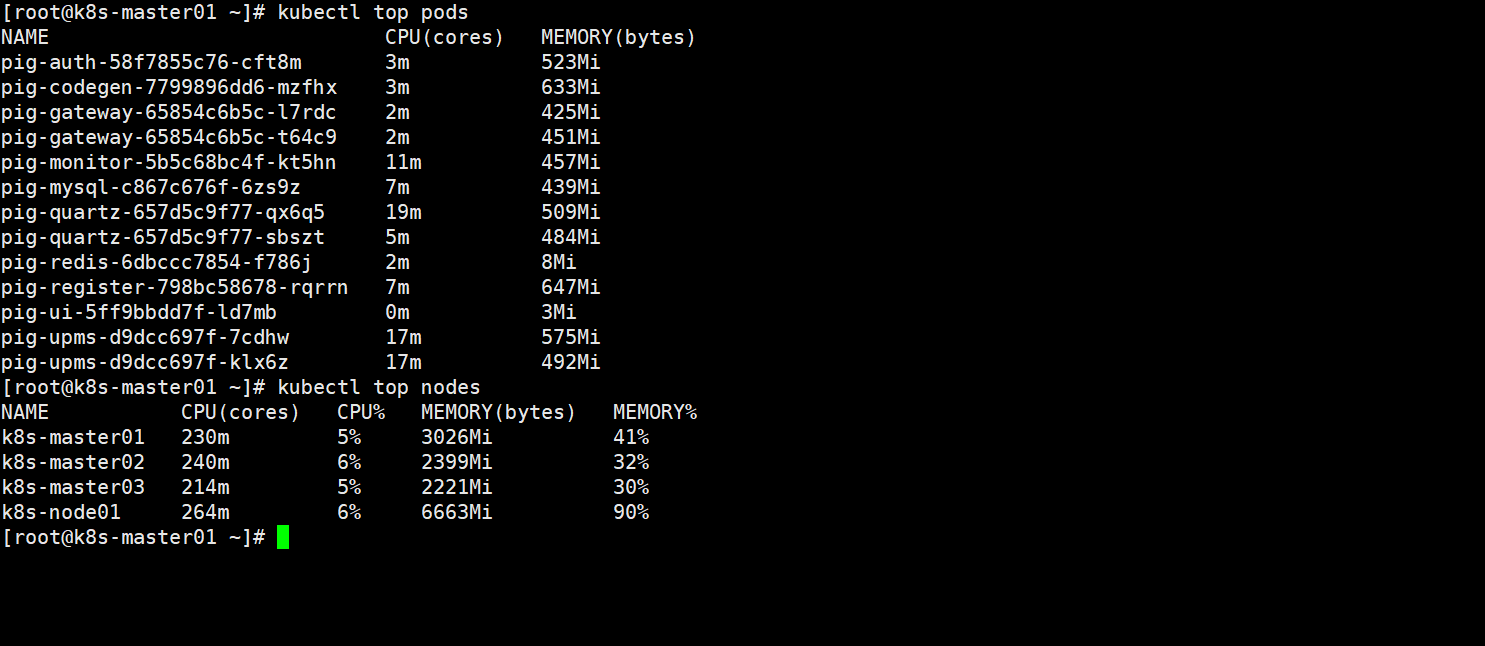
K8S部署Metrics-Server服务
Metrics-Server是k8s集群采集监控数据的聚合器,如采集node、pod的cpu、内存等数据,从 Kubernetes1.8 开始默认使用Metrics-Server采集数据,并通过Metrics API的形式提供查询,但是,kubeadm安装的k8s集群默认是没有安装Metrics-Server的,所以我们来安装一下Metrics-Server。 ⚠️ 需要注意的是 在 Kub
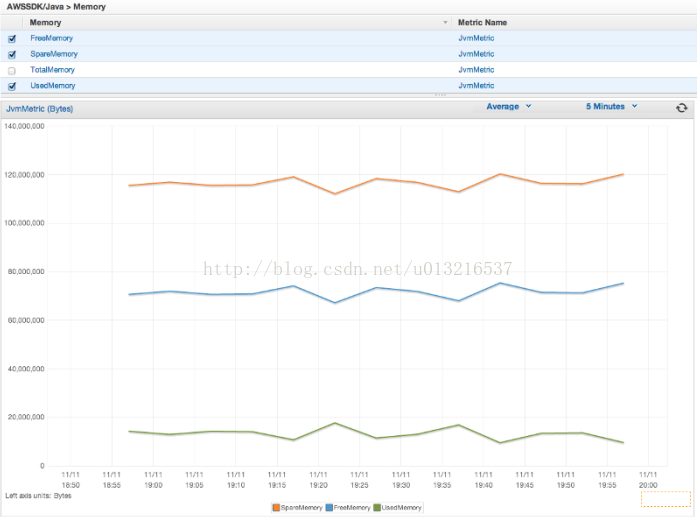
Enabling Metrics for the AWS SDK for Java
原文连接:《AWS SDK for Java——Developer Guide》 译文↓↓↓ 用于Java的AWS开发工具包可以使用CloudWatch生成可视化和监控指标来衡量如下内容: ·访问AWS时应用程序的性能 ·与AWS一起使用时JVM的性能 ·运行环境的详细信息,如堆内存、线程数以及打开的文件描述符 如何启动SDK生成指标 SDK在默认情况下是不启用的。
![【Keras】keras model.compile(loss='目标函数 ', optimizer='adam', metrics=['accuracy'])](/front/images/it_default.jpg)
【Keras】keras model.compile(loss='目标函数 ', optimizer='adam', metrics=['accuracy'])
讲解了各种loss https://www.cnblogs.com/smuxiaolei/p/8662177.html
Metrics-Server的核心产生原因是为了实现监控接口的标准化。
Metrics-Server的核心产生原因是为了实现监控接口的标准化。 正确 错误 这句话是正确的 Metrics-Server是Kubernetes中的一个组件,它的主要目的是为了提供一个标准化的监控接口,以便于对Kubernetes集群中的资源使用情况进行监控。在Kubernetes中,资源的监控和调度是确保集群高效运行的关键因素。为了实现这一点,Kubernetes提供了一系列接口和工具
【Rust日报】2022-02-19 Tokio Metrics 0.1
Tokio Metrics 0.1 今天,我们很高兴地宣布初始发布Tokio-Metrics,一个用于获得Tokio应用程序的运行时和任务级别指标的crate。Tokio-Metrics使Tokio用户更容易通过提供生产中的运行时行为来调试性能问题。 如今,Tokio已成功用于亚马逊、微软、Discord等公司的大规模生产部署。然而,我们通常会从处理调试问题的工程师那里收到问题。 文章链接,ht
17-云原生监控体系-metrics-server
1. 关于监控 Kubernetes 如果想让 Prometheus 监控 Kubernetes 集群,首先需要明确集群中需要监控哪些对象,也就是需要收集哪些监控指标,如下是总结 Kubernetes 集群中大概有三类指标需要收集: 集群中每个节点服务器的指标,就是每台服务器的CPU,内存等这些级别信息,可以使用之前学习到的 node_exporter 实现。Kubernetes 集群组件的指

复现百度云智实验出的bug:使用paddle的fluid出现please use fluid.metrics.EditDistance instead.报错问题
最近看了百度云智学院的OCR的实验,简直不能更坑,以后还是好好在github上或者CSDN上搜搜案例来实践,商业公司的即使是BAT的也糟糕透了,英文不好不然就去微软的学学。 百度的车牌识别: http://abcxueyuan.cloud.baidu.com/newlab/#/lab_detail/lab_exp_book?id=121 学习流程: 实验目录: 用paddlepaddle框架搭
18-云原生监控体系-kube-state-metrics
文章目录 1. 介绍2. kube-state-metrics vs. metrics-server3. 安装3.1. 拉取镜像3.2. 部署到 kubernetes 集群3.2.1 Kubernetes Deployment 3.3. 配置到 Prometheus3.3. 自己构建 Docker 镜像3.4. 对于 prometheus-operator/kube-prometeus st
k8s学习(九) 使用metrics-server 进行hpa扩容
Horizontal Pod Autoscaling(Pod水平自动伸缩),简称HPA。HAP通过监控分析RC或者Deployment控制的所有Pod的负载变化情况来确定是否需要调整Pod的副本数量,这是HPA最基本的原理。 当你创建了HPA后,HPA会从metrics-server或者用户自定义的监控获取每一个一个Pod利用率或原始值的平均值,然后和HPA中定义的指标进行对比,同时计算出需要伸
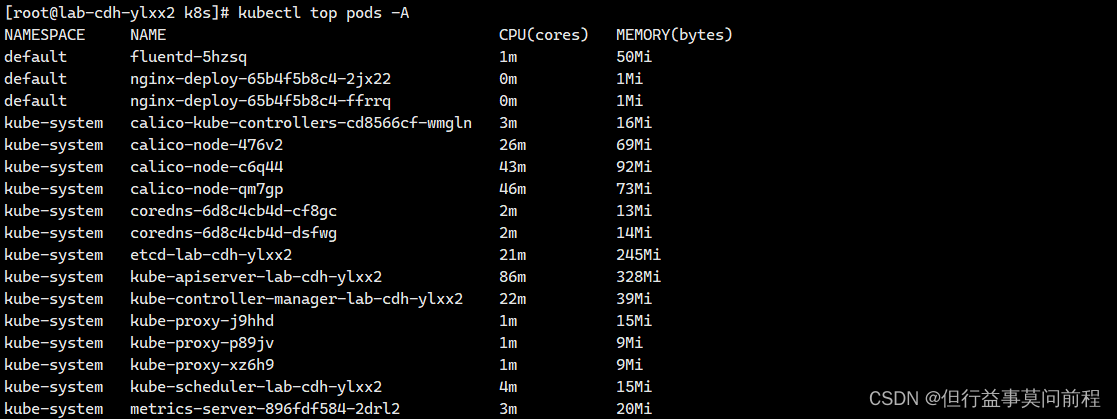
k8s metrics-server服务监控pod 的 cpu、内存
项目场景: 需要开启指标服务,依据pod 的 cpu、内存使用率进行自动的扩容或缩容 pod 的数量 解决方案: 下载 metrics-server 组件配置文件: wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml -O components.y
【Jmeter】插件详解:PerfMon Metrics Collector 服务器性能监控插件
目录 一、前言 二、PerfMon Metrics Collector 插件详解 (1)插件简介 (2)功能介绍 (3)应用场景 (4)使用指南 ① 环境准备 ② 服务端插件配置 ③ 监听器配置 ④ 图表设置 ⑤ 非 GUI 模式 三、ServerAgent 下载 四、ServerAgent 安装 (1)安装 (2)使用方法 (3)使用 Server
Kubernetes 系统监控Metrics Server、HorizontalPodAutoscaler、Prometheus
Metrics Server Linux 系统命令 top 能够实时显示当前系统的 CPU 和内存利用率,它是性能分析和调优的基本工具。 Kubernetes 也提供了类似的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装一个插件 Metrics Server 才可以。 Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(met
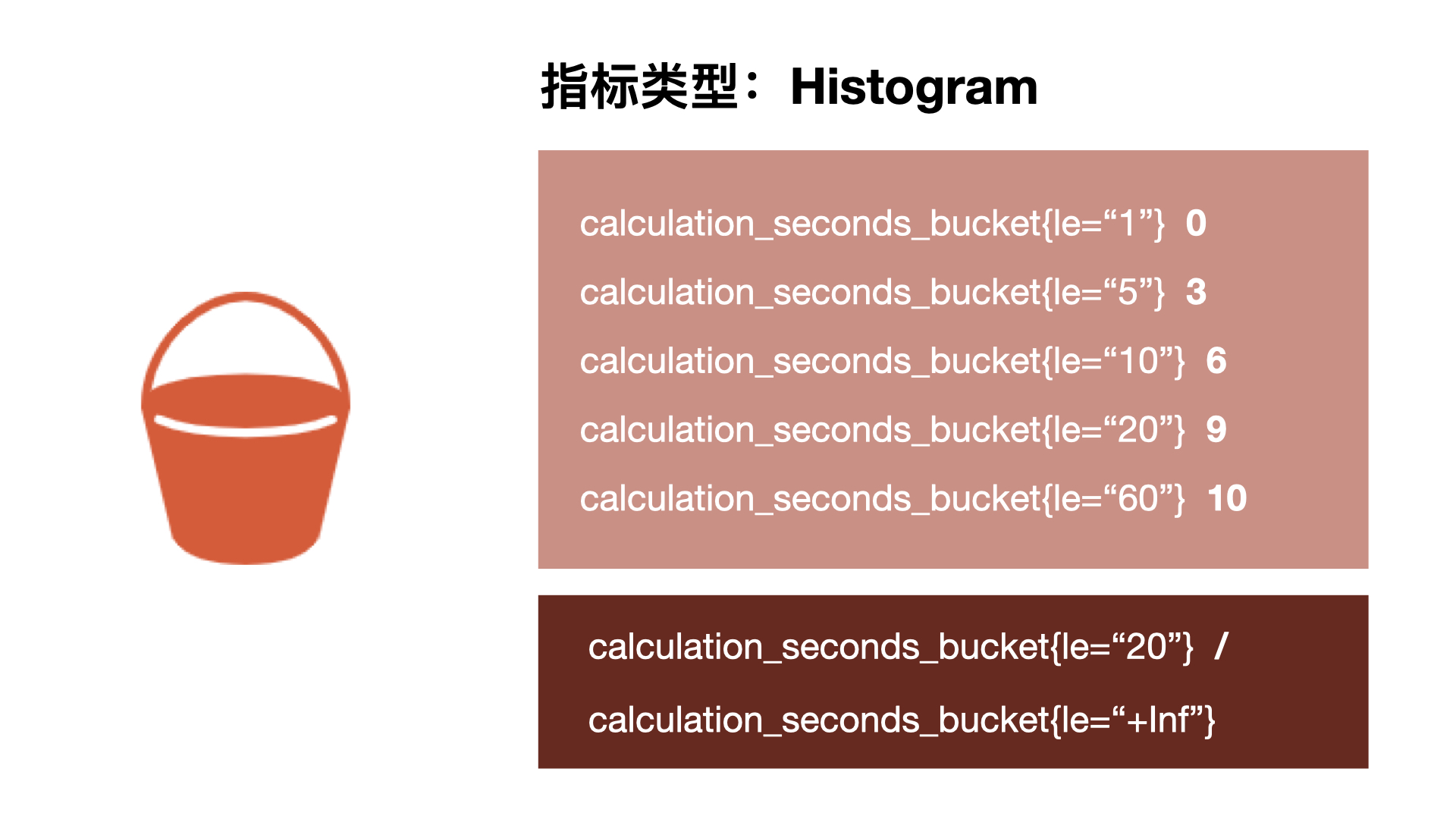
Prometheus Metrics指标类型 Histogram、Summary分析数据分布情况
Histogram 直方图 、Summary 摘要 使用Histogram和Summary分析数据分布情况 除了 Counter 和 Gauge 类型的监控指标以外,Prometheus 还定义了 Histogram 和 Summary 的指标类型。Histogram 和 Summary 主用用于统计和分析样本的分布情况。 在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 C

kubernetes中的附件组件Metrics-server与hpa资源实现对pod的自动扩容和缩容
一、概述 Metrics-Server组件目的:获取集群中pod、节点等负载信息; hpa资源目的:通过metrics-server获取的pod负载信息,自动伸缩创建pod; 二、安装部署 Metrics-Server组件 安装目的,就是给k8s集群安装top命令 1、下载Metrics-Server资源清单 wget https://githu
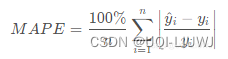
sklearn 笔记 metrics
1 分类 1.1 accuracy_score 分类准确率得分 在多标签分类中,此函数计算子集准确率:y_pred的标签集必须与 y_true 中的相应标签集完全匹配。 1.1.1 参数 y_true真实(正确)标签y_pred由分类器返回的预测标签normalize 默认为 True,返回正确分类的样本比例 如果为 False,返回正确分类的样本数量 sample_weight
metrics小常识
Metrics,我们听到的太多了,熟悉大数据系统的不可能没听说过metrics,当我们需要为某个系统某个服务做监控、做统计,就需要用到Metrics。 举个例子,一个图片压缩服务: 每秒钟的请求数是多少(TPS)?平均每个请求处理的时间?请求处理的最长耗时?等待处理的请求队列长度? 又或者一个缓存服务: 缓存的命中率?平均查询缓存的时间? 基本上每一个服务、应用都需要做一个监控系
ROI of Software Process Improvement: Metrics for Project Managers and Software Engineers
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp An indispensable addition to your project management, software engineering or computer science bookshelf,

分布式时序计算框架vortex metrics使用介绍
vortex metrics是一款用Java写的,轻量级的,高性能的分布式时序计算框架。 vortex metrics框架源自作者另一个分布式流式计算框架vortex,可以看作是vortex关于时序计算场景的一个具体实现 框架特性: 去中心化模式管理应用集群支持应用动态水平扩展并发性能极高且稳定(网络层可适配Netty4,Mina,Grizzly等框架)CP分布式架构,支持数据的最终一致性
error: Metrics not available for pod 解决方案
环境 win10系统,开启了WSL2 docker for windows,开启了WSL集成 minikube for windows kubectl for windows 缘由 kubectl top po 查看pod的资源使用情况时报错: error: Metrics not available for pod 解决方案 在metrics-server的启动参数里添加以下两个命

【go】metrics基本使用
metrics 是什么? 当我们需要为某个系统某个服务做监控、做统计,就需要用到Metrics 五种 Metrics 类型 Gauges :最简单的度量指标,只有一个简单的返回值,或者叫瞬时状态Counters:Counter 就是计数器,Counter 只是用 Gauge 封装了 AtomicLongMeters:Meter度量一系列事件发生的速率(rate),例如TPS。Meters会统