本文主要是介绍Kubernetes 系统监控Metrics Server、HorizontalPodAutoscaler、Prometheus,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Metrics Server
Linux 系统命令 top 能够实时显示当前系统的 CPU 和内存利用率,它是性能分析和调优的基本工具。
Kubernetes 也提供了类似的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装一个插件 Metrics Server 才可以。
Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的工具,它定时从所有节点的 kubelet 里采集信息,但是对集群的整体性能影响极小,每个节点只大约会占用 1m 的 CPU 和 2MB 的内存,所以性价比非常高。
Metrics Server 的工作方式(如下图):它调用 kubelet 的 API 拿到节点和 Pod 的指标,再把这些信息交给 apiserver,这样 kubectl、HPA 就可以利用 apiserver 来读取指标了。

Metrics Server安装
Metrics Server 的镜像仓库用的是 gcr.io,下载很困难,所以需要走迂回路线,先下载下来,再上传到自己的dockerhub镜像仓库或者阿里云仓库
1、下载 Metrics Server 的镜像并上传到dockerhub
脚本内容
#!/bin/bash# 定义变量
repo="registry.aliyuncs.com/google_containers"
name="k8s.gcr.io/metrics-server/metrics-server:v0.6.1"
src_name="metrics-server:v0.6.1"# 从阿里云镜像仓库拉取镜像
docker pull ${repo}/${src_name}# 重新标记镜像
docker tag ${repo}/${src_name} ${name}# 删除原始镜像标签
docker rmi ${repo}/${src_name}
# 查看镜像
docker images

# 登录dockerhub
docker login
# 打镜像tag
docker tag k8s.gcr.io/metrics-server/metrics-server:v0.6.1 dockerhub用户名/metrics-server:v0.6.1
# 推送镜像到自己的dockerhub上
docker push dockerhub用户名/metrics-server:v0.6.1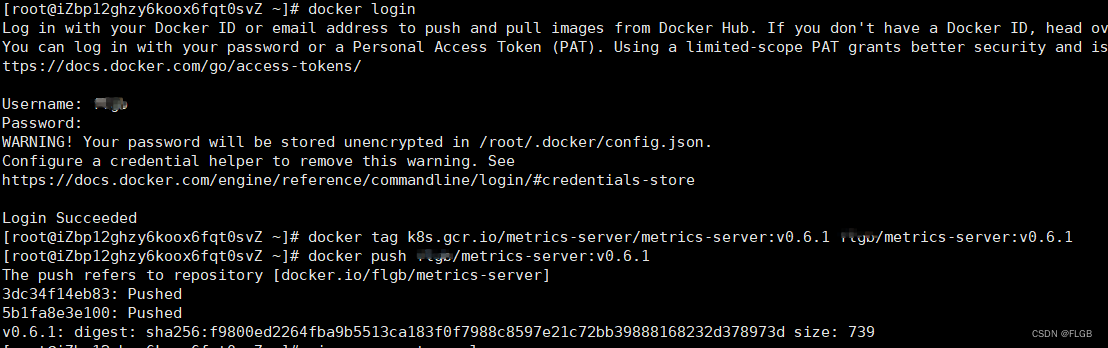
2、编写components.yaml
image: dockerHub名称/metrics-server:v0.6.1 镜像要改成自己的dockerHub用户名
apiVersion: v1
kind: ServiceAccount
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:k8s-app: metrics-serverrbac.authorization.k8s.io/aggregate-to-admin: "true"rbac.authorization.k8s.io/aggregate-to-edit: "true"rbac.authorization.k8s.io/aggregate-to-view: "true"name: system:aggregated-metrics-reader
rules:
- apiGroups:- metrics.k8s.ioresources:- pods- nodesverbs:- get- list- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:k8s-app: metrics-servername: system:metrics-server
rules:
- apiGroups:- ""resources:- nodes/metricsverbs:- get
- apiGroups:- ""resources:- pods- nodesverbs:- get- list- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:labels:k8s-app: metrics-servername: metrics-server-auth-readernamespace: kube-system
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: metrics-servername: metrics-server:system:auth-delegator
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:auth-delegator
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: metrics-servername: system:metrics-server
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:metrics-server
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: v1
kind: Service
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
spec:ports:- name: httpsport: 443protocol: TCPtargetPort: httpsselector:k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
spec:selector:matchLabels:k8s-app: metrics-serverstrategy:rollingUpdate:maxUnavailable: 0template:metadata:labels:k8s-app: metrics-serverspec:containers:- args:- --kubelet-insecure-tls- --cert-dir=/tmp- --secure-port=10250- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname- --kubelet-use-node-status-port- --metric-resolution=15simage: dockerHub名称/metrics-server:v0.6.1imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 3httpGet:path: /livezport: httpsscheme: HTTPSperiodSeconds: 10name: metrics-serverports:- containerPort: 10250name: httpsprotocol: TCPreadinessProbe:failureThreshold: 3httpGet:path: /readyzport: httpsscheme: HTTPSinitialDelaySeconds: 20periodSeconds: 10resources:requests:cpu: 100mmemory: 200MisecurityContext:allowPrivilegeEscalation: falsecapabilities:drop:- ALLreadOnlyRootFilesystem: truerunAsNonRoot: truerunAsUser: 1000seccompProfile:type: RuntimeDefaultvolumeMounts:- mountPath: /tmpname: tmp-dirnodeSelector:kubernetes.io/os: linuxpriorityClassName: system-cluster-criticalserviceAccountName: metrics-servervolumes:- emptyDir: {}name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:labels:k8s-app: metrics-servername: v1beta1.metrics.k8s.io
spec:group: metrics.k8s.iogroupPriorityMinimum: 100insecureSkipTLSVerify: trueservice:name: metrics-servernamespace: kube-systemversion: v1beta1versionPriority: 100执行命令
# 创建脚本文件
vim metrics_server_img
# 赋予脚本执行权限
chmod +x metrics_server_img
# 运行脚本
./metrics_server_img使用 YAML 部署 Metrics Server
kubectl apply -f components.yaml
#
kubectl get pod -n kube-system# 获取pod详情,还常可以查看问题
kubectl describe pod -n kube-system metrics-server-587665fc75-46gr2
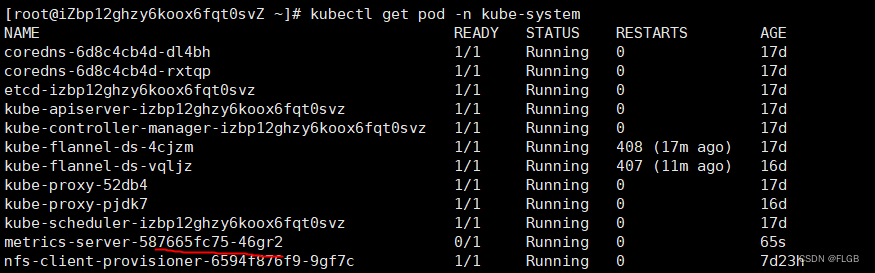
现在有了 Metrics Server 插件,我们就可以使用命令 kubectl top 来查看 Kubernetes 集群当前的资源状态了。它有两个子命令,node 查看节点的资源使用率,pod 查看 Pod 的资源使用率。
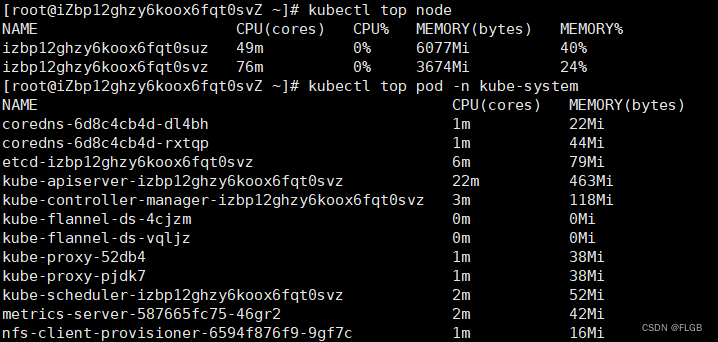
kubectl top node
kubectl top pod -n kube-system
HorizontalPodAutoscaler
Metrics Server另外一个更重要的功能是辅助实现应用的“水平自动伸缩”。
kubectl scale,可以任意增减 Deployment 部署的 Pod 数量,也就是水平方向的“扩容”和“缩容”。但是手动调整应用实例数量还是比较麻烦的,需要人工参与,也很难准确把握时机,难以及时应对生产环境中突发的大流量,所以最好能把这个“扩容”“缩容”也变成自动化的操作。
Kubernetes 为此就定义了一个新的 API 对象,叫做“HorizontalPodAutoscaler”,简称是“hpa”。顾名思义,它是专门用来自动伸缩 Pod 数量的对象,适用于 Deployment 和 StatefulSet,但不能用于 DaemonSet。
HorizontalPodAutoscaler 的能力完全基于 Metrics Server,它从 Metrics Server 获取当前应用的运行指标,主要是 CPU 使用率,再依据预定的策略增加或者减少 Pod 的数量。
使用 HorizontalPodAutoscaler
定义 Deployment 和 Service,创建一个 Nginx 应用,作为自动伸缩的目标对象:
hpa-ngx-pod.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: ngx-hpa-depspec:replicas: 1selector:matchLabels:app: ngx-hpa-deptemplate:metadata:labels:app: ngx-hpa-depspec:containers:- image: nginx:alpinename: nginxports:- containerPort: 80resources:requests:cpu: 50mmemory: 10Milimits:cpu: 100mmemory: 20Mi
---apiVersion: v1
kind: Service
metadata:name: ngx-hpa-svc
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: ngx-hpa-dep
在这个 YAML 里只部署了一个 Nginx 实例,名字是 ngx-hpa-dep。注意在它的 spec 里一定要用 resources 字段写清楚资源配额,否则 HorizontalPodAutoscaler 会无法获取 Pod 的指标,也就无法实现自动化扩缩容。
接下来要用命令 kubectl autoscale 创建一个 HorizontalPodAutoscaler 的样板 YAML 文件,它有三个参数:
- min,Pod 数量的最小值,也就是缩容的下限。
- max,Pod 数量的最大值,也就是扩容的上限。
- cpu-percent,CPU 使用率指标,当大于这个值时扩容,小于这个值时缩容。
为刚才的 Nginx 应用创建 HorizontalPodAutoscaler,指定 Pod 数量最少 2 个,最多 10 个,CPU 使用率指标设置的小一点,5%,方便观察扩容现象:
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl autoscale deploy ngx-hpa-dep --min=2 --max=10 --cpu-percent=5 $out
hpa-ngx.yml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:name: ngx-hpaspec:maxReplicas: 10minReplicas: 2scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: ngx-hpa-deptargetCPUUtilizationPercentage: 5
执行命令
# 生成pod
kubectl apply -f hpa-ngx-pod.yml
# 获取pod
kubectl get deploy ngx-hpa-dep
# 执行自动扩缩容
kubectl apply -f hpa-ngx.yml
# 查看deploy变化
kubectl get deploy ngx-hpa-dep
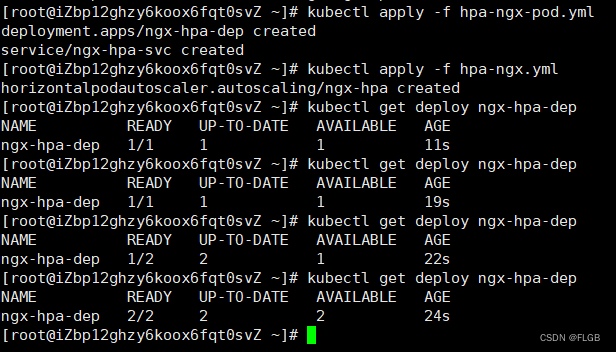
HorizontalPodAutoscaler 会根据 YAML 里的描述,找到要管理的 Deployment,把 Pod 数量调整成 2 个,再通过 Metrics Server 不断地监测 Pod 的 CPU 使用率。
下面来给 Nginx 加上压力流量,运行一个测试 Pod,使用的镜像是“httpd:alpine”,它里面有 HTTP 性能测试工具 ab(Apache Bench):
kubectl run test -it --image=httpd:alpine -- sh
然后我们向 Nginx 发送一百万个请求,持续 1 分钟,再用 kubectl get hpa 来观察 HorizontalPodAutoscaler 的运行状况:
ab -c 10 -t 60 -n 1000000 'http://ngx-hpa-svc/'
-w watch 监控pod变化
kubectl get deploy ngx-hpa-dep -w
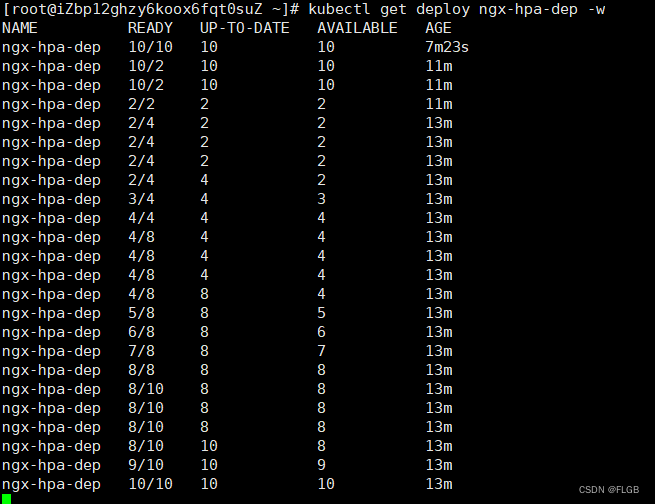
因为 Metrics Server 大约每 15 秒采集一次数据,所以 HorizontalPodAutoscaler 的自动化扩容和缩容也是按照这个时间点来逐步处理的。当它发现目标的 CPU 使用率超过了预定的 5% 后,就会以 2 的倍数开始扩容,一直到数量上限,然后持续监控一段时间,如果 CPU 使用率回落,就会再缩容到最小值。
Prometheus
Metrics Server 能够获取的指标还是太少了,只有 CPU 和内存,想要监控到更多更全面的应用运行状况,还得请出这方面的权威项目“Prometheus”。
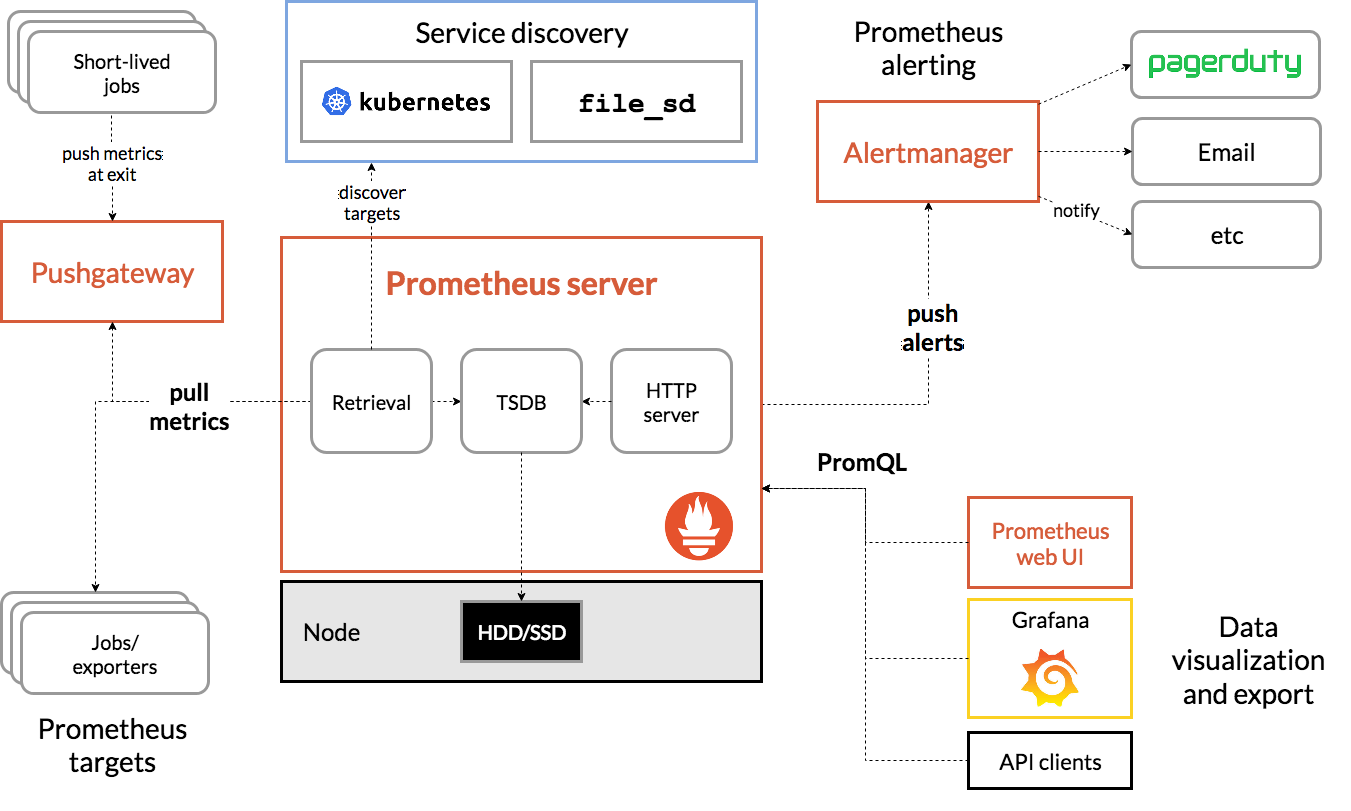
Prometheus 系统的核心是它的 Server,里面有一个时序数据库 TSDB,用来存储监控数据,另一个组件 Retrieval 使用拉取(Pull)的方式从各个目标收集数据,再通过 HTTP Server 把这些数据交给外界使用。
在 Prometheus Server 之外还有三个重要的组件:
- Push Gateway,用来适配一些特殊的监控目标,把默认的 Pull 模式转变为 Push 模式。
- Alert Manager,告警中心,预先设定规则,发现问题时就通过邮件等方式告警。
- Grafana 是图形化界面,可以定制大量直观的监控仪表盘。
选用“kube-prometheus安装Prometheus
1、下载 kube-prometheus 的源码包
#下载文件
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.11.0.tar.gz
#解压
tar -zxvf v0.11.0.tar.gz
2、修改 prometheus-service.yaml、grafana-service.yaml。
添加 type: NodePort直接通过节点的 IP 地址访问
prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:labels:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 2.36.1name: prometheus-k8snamespace: monitoring
spec:type: NodePortports:- name: webport: 9090targetPort: web- name: reloader-webport: 8080targetPort: reloader-webselector:app.kubernetes.io/component: prometheusapp.kubernetes.io/instance: k8sapp.kubernetes.io/name: prometheusapp.kubernetes.io/part-of: kube-prometheussessionAffinity: ClientIPgrafana-service.yaml
apiVersion: v1
kind: Service
metadata:labels:app.kubernetes.io/component: grafanaapp.kubernetes.io/name: grafanaapp.kubernetes.io/part-of: kube-prometheusapp.kubernetes.io/version: 8.5.5name: grafananamespace: monitoring
spec:type: NodePortports:- name: httpport: 3000targetPort: httpselector:app.kubernetes.io/component: grafanaapp.kubernetes.io/name: grafanaapp.kubernetes.io/part-of: kube-prometheus修改 kubeStateMetrics-deployment.yaml、prometheusAdapter-deployment.yaml,因为它们里面有两个存放在 gcr.io 的镜像,国内可能下载不下来
#走迂回路线,先下载下来,推送到自己的dockerHub上,当然也可以直接用
#当然也可以直接用 chronolaw/kube-state-metrics:v2.5.0镜像
docker pull chronolaw/kube-state-metrics:v2.5.0
#改成自己的dockerhub用户名
docker tag chronolaw/kube-state-metrics:v2.5.0 dockerhub用户名/kube-state-metrics:v2.5.0
#推送到自己的dockerHub上
docker push dockerhub用户名/kube-state-metrics/kube-state-metrics:v2.5.0docker pull pengyc2019/prometheus-adapter:v0.9.1
docker tag pengyc2019/prometheus-adapter:v0.9.1 dockerhub用户名/prometheus-adapter:v0.9.1
docker push dockerhub用户名/prometheus-adapter:v0.9.1
然后修改kubeStateMetrics-deployment.yaml、prometheusAdapter-deployment.yaml里面的image为自己的dockerHub中的。或者也可以直接使用chronolaw/kube-state-metrics:v2.5.0、
pengyc2019/prometheus-adapter:v0.9.1这两个镜像地址
image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0
image: k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1image: dockerhub用户名/kube-state-metrics:v2.5.0
image: dockerhub用户名/prometheus-adapter:v0.9.1
执行两个 kubectl create 命令来部署 Prometheus,先是 manifests/setup 目录,创建名字空间等基本对象,然后才是 manifests 目录:
注意目录层级,下面是在 kube-prometheus-0.11.0这层执行的命令
kubectl create -f manifests/setup
kubectl create -f manifests
Prometheus 的对象都在名字空间“monitoring”里,创建之后可以用 kubectl get 来查看状态:
kubectl get pod -n monitoring
稍等一会再执行,目前在创建中
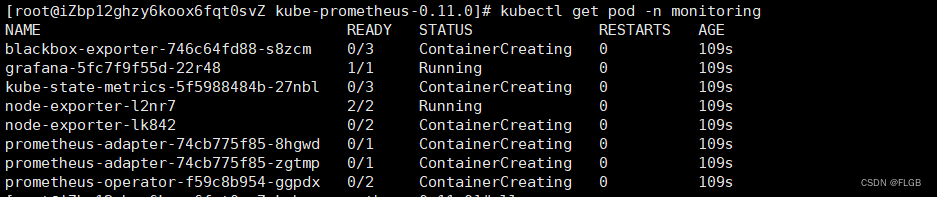
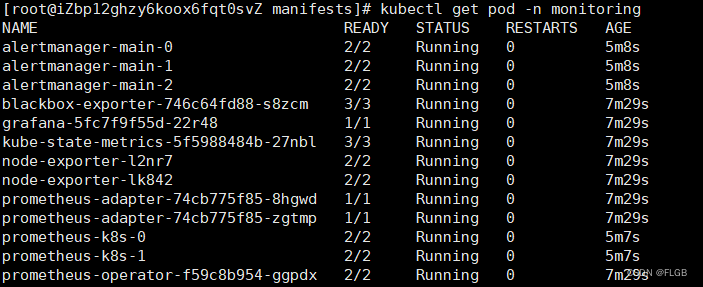 这些 Pod 都运行正常,查看它对外的服务端口:
这些 Pod 都运行正常,查看它对外的服务端口:
kubectl get svc -n monitoring
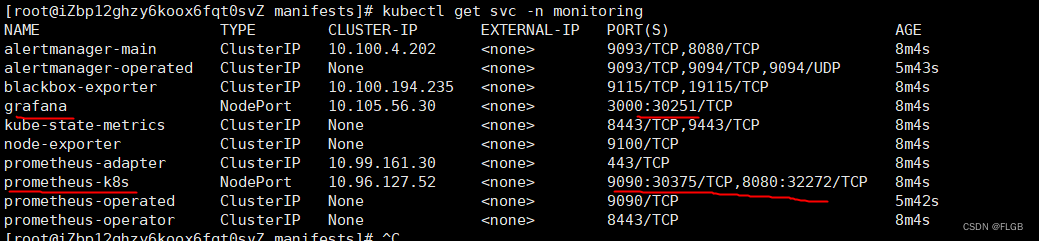
前面修改了 Grafana 和 Prometheus 的 Service 对象,所以这两个服务就在节点上开了端口,Grafana 是“30251”,Prometheus 有两个端口,其中“9090”对应的“30375”是 Web 端口。
在浏览器里输入节点的 IP 地址,再加上端口号“30375”,我们就能看到 Prometheus 自带的 Web 界面,:
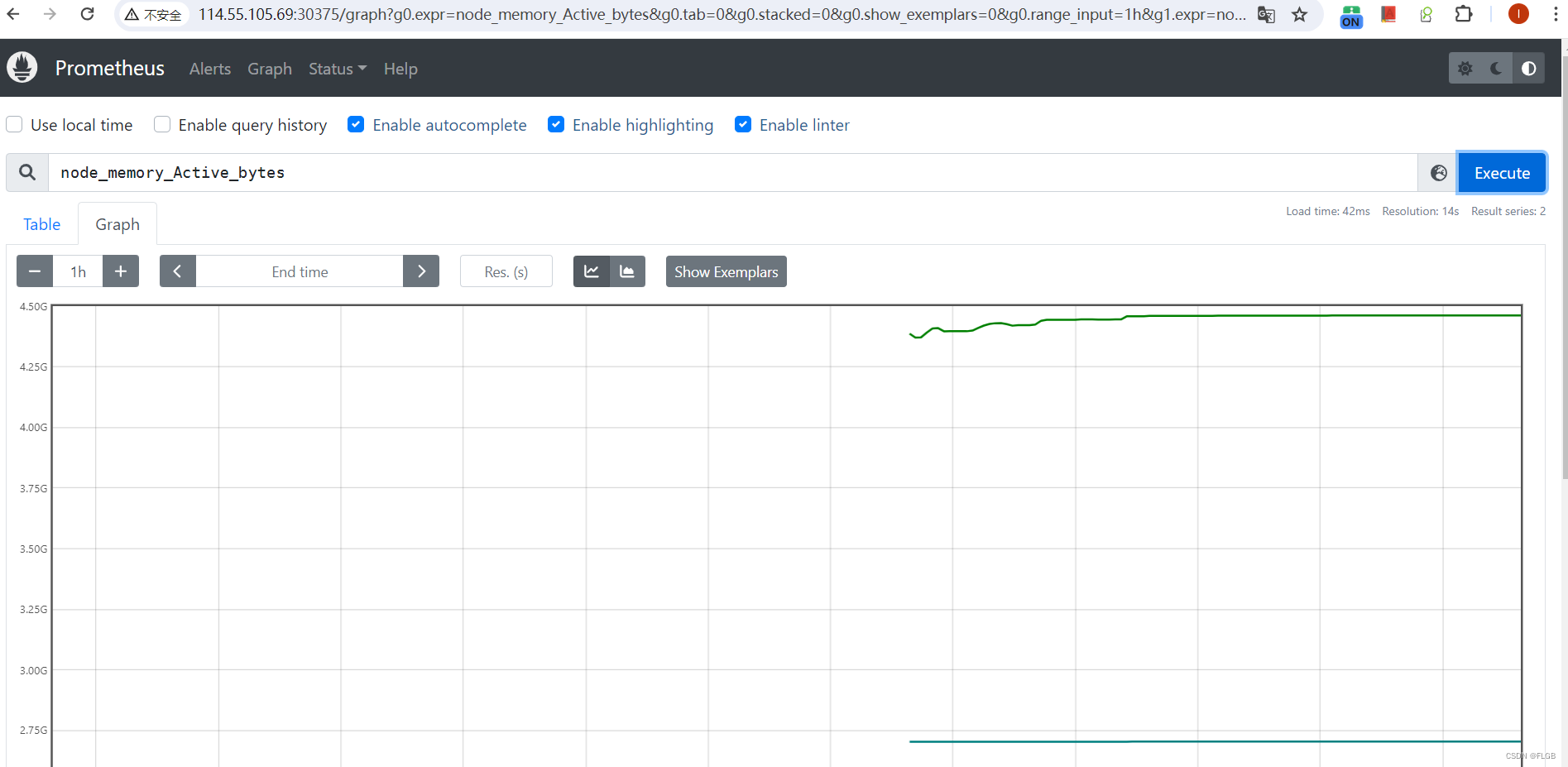
Web 界面上有一个查询框,可以使用 PromQL 来查询指标,生成可视化图表,比如在这个截图里我就选择了“node_memory_Active_bytes”这个指标,意思是当前正在使用的内存容量。
Grafana,访问节点的端口“30251”,它会要求你先登录,默认的用户名和密码都是“admin”:
Grafana 内部已经预置了很多强大易用的仪表盘,你可以在左侧菜单栏的“Dashboards - Browse”里任意挑选一个:
比如我选择了“Kubernetes / Compute Resources / Namespace (Pods)”这个仪表盘,就会出来一个非常漂亮图表,比 Metrics Server 的 kubectl top 命令要好看得多,各种数据一目了然:
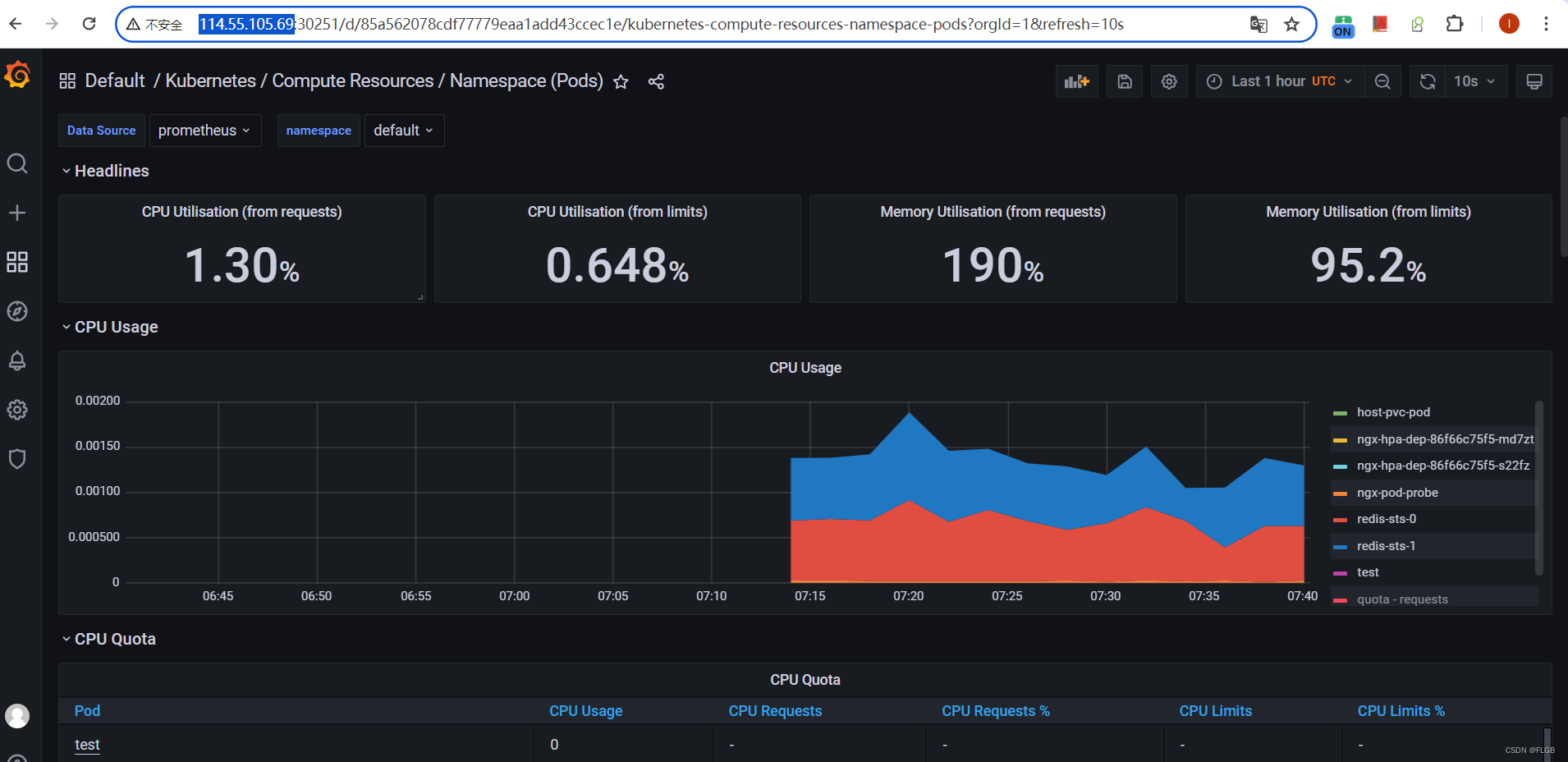
More Prometheus
这篇关于Kubernetes 系统监控Metrics Server、HorizontalPodAutoscaler、Prometheus的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







