本文主要是介绍复现百度云智实验出的bug:使用paddle的fluid出现please use fluid.metrics.EditDistance instead.报错问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近看了百度云智学院的OCR的实验,简直不能更坑,以后还是好好在github上或者CSDN上搜搜案例来实践,商业公司的即使是BAT的也糟糕透了,英文不好不然就去微软的学学。
百度的车牌识别:
http://abcxueyuan.cloud.baidu.com/newlab/#/lab_detail/lab_exp_book?id=121
学习流程: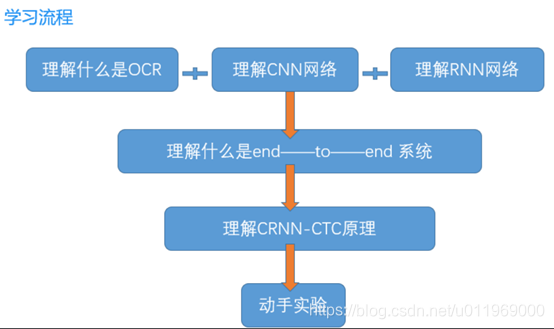
实验目录:
用paddlepaddle框架搭建CRNN-CTC算法
用CRNN-CTC算法来实现文字识别,并进行训练和预测
1、OCR介绍
OCR (Optical Character Recognition,光学字符识别),将图像中的文字进行识别,并以文本的形式返回。
OCR一般分为两个大步骤:图像预处理+文字识别。
OCR的文字识别流程:

OCR运用的深度学习算法:
(1)CNN卷积神经网络:
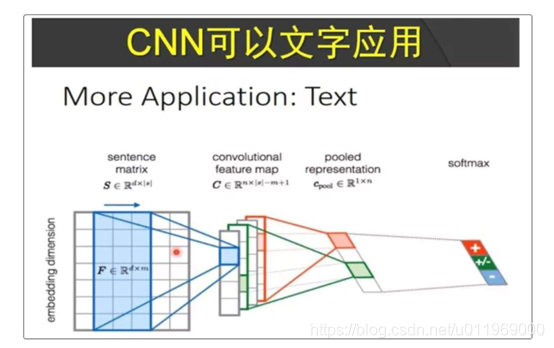
(2)RNN循环神经网络
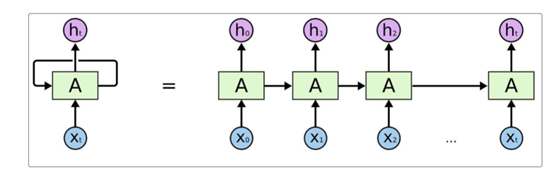
本次实验的目的
1、使用paddle框架搭建CRNN-CTC算法
2、使用CRNN-CTC算法来实现文字识别,并进行训练和预测
2、OCR算法介绍
OCR技术路线
a.用CNN对固定长度的文字进行识别效果较好,比如验证码,CNN适用于单字符识别,不适合全文识别
b.对于序列问题RNN是强项,场景文字,手写字符和乐谱
对于序列问题的处理,出现了两类算法
第一类:CNN+RNN+CTC
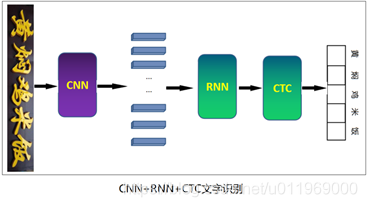
第二类:CNN+RNN+Attention
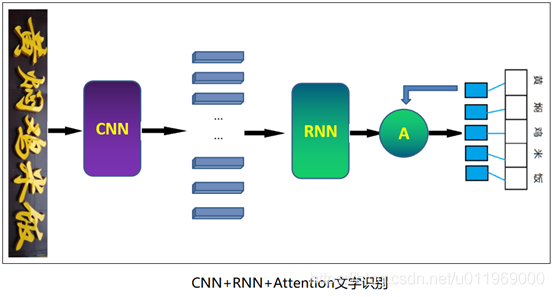
区别:
输出层,方法一在对其的时候采用CTC算法,方法二采用attention机制
3.CRNN-CTC算法介绍
第一类算法:CRNN-CTC 原理介绍
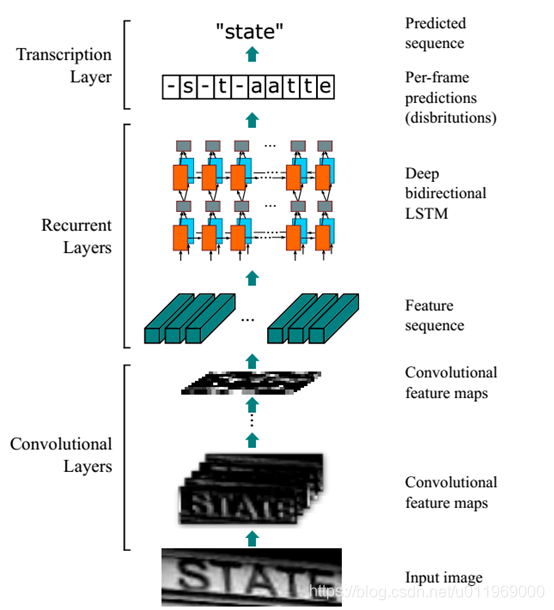
从下到上:
卷积层,使用CNN,作用是从输入图像中提取特征序列
循环层,使用RNN或lstm,作用是预测从卷积层获取的特征序列的标签(真实值)分布
转录层,使用CTC,作用是从循环层获取的标签分布通过去重整合等操场转换成最终的识别结果
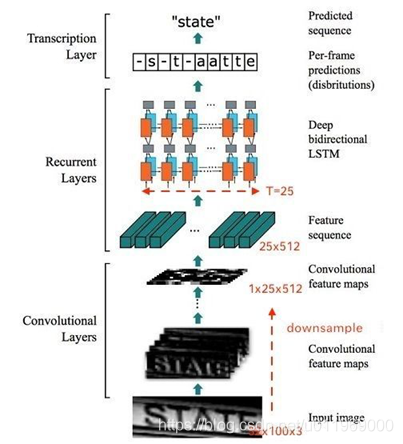
假设输入图像大小为 (32, 100,3),注意:提及图像都是 H,W,C 形式。
这里的卷积层就是一个普通的CNN网络,用于提取输入图像的Convolutional feature maps,即将大小为 (32, 100,3) 的图像转换为 (1,25,512) 大小的卷积特征矩阵。
为了将特征输入到LSTM层,整体网络结构上做了做如下处理:
1、首先会将图像缩放到 32× W×3 大小
2、然后经过CNN后变为 1× (W/4)×512
3、接着针对LSTM,设置 T=(W/4) , D=512 ,即可将特征输入LSTM。
注意:在处理输入图像的时候,尽量保证长宽比,将高缩放为32,相对保证不破坏文本细节,否则性能下降。
整体网络配置表如下:

k:核大小
s:步长
p:填充大小
第1行input顶层,k,s,p分别表示核大小,步长和填充大小。
卷积层的架构是基于VGG-VeryDeep的架构。为了使其适用于识别英文文本,对其进行了调整。
在第3和第4个最大池化层中,我们采用1×2大小的矩形池化窗口而不是传统的平方形。
这种调整产生宽度较大的特征图,因此具有更长的特征序列。
例如,包含10个字符的图像通常为大小为100×32,可以从其生成25帧的特征序列。这个长度超过了大多数英文单词的长度。最重要的是,矩形池窗口产生矩形感受野,这有助于识别一些具有窄形状的字符,例如i和l。
CRNN-CTC网络不仅有深度卷积层,而且还有循环层。我们知道这两者都是难以训练的。但是,我们发现“批归一化技术”对于训练这种深度网络非常有用。
于是作者分别在第5和第6卷积层之后插入两个批归一化层。使用批归一化层可以使训练过程大大加快。
【卷积层】CNN部分
在CRNN模型中,采用标准CNN模型(去除了全连接层),来从输入图像中提取序列特征。在进入网络之前,所有的图像需要缩放到相同的高度。然后从卷积后产生的特征图中提取特征向量序列,这些特征向量序列作为循环层的输入。具体来说,特征序列的每一个特征向量在特征图上按列从左到右生成。这意味着第i个特征向量是所有特征图第i列的连接。在我们的设置中每列的宽度固定为单个像素。

由于卷积层,最大池化层和激活函数是在局部区域上执行的,因此它们是平移不变的。因此,特征图的每列对应于原始图像的一个矩形区域(称为感受野),并且这些矩形区域与特征图上从左到右的相应列具有相同的顺序。如上图所示,特征序列中的每个向量关联一个感受野,并且可以被认为是该区域的图像描述符。
【循环层】RNN部分
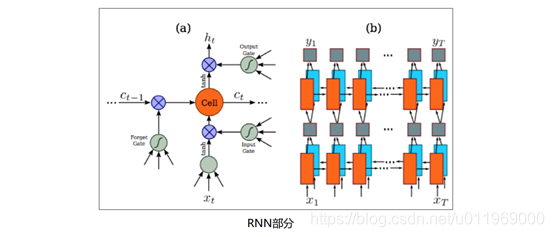
卷积层的顶部是一个深度双向循环神经网络,作为循环层。
循环层的优点有三个:
1、RNN具有很强的捕获序列内上下文信息的能力。对于基于图像的序列识别使用上下文提示比独立处理每个符号更稳定且更有帮助。以场景文本识别为例,宽字符可能需要一些连续的帧来完全描述。此外,一些模糊的字符在观察其上下文时更容易区分,例如,通过对比字符高度更容易识别“il”而不是分别识别它们中的每一个。
2、RNN可以将误差值反向传播到其输入,即上一步的卷积层,从而允许我们在统一的网络中共同训练循环层和卷积层。
3、RNN能够从头到尾对任意长度的序列进行操作。
【转录层】
转录层是将RNN所做的每帧预测转换成标签序列的过程。从数学上分析,转录是根据每帧预测找到具有最高概率的标签序列。在实践中,存在两种转录模式,即无词典转录和基于词典的转录。词典是一组标签序列,预测受拼写检查字典约束。在无词典模式中,预测时没有任何词典。在基于词典的模式中,通过选择具有最高概率的标签序列进行预测。
CTC-loss

CTC的工作原理
CTC是一种Loss计算方法,用CTC代替Softmax Loss,训练样本无需对齐。他通过引入blank字符,解决了有些位置没有字符的问题;同时,CTC通过递推,可以快速计算梯度。 用ctc loss时会出现这种情况,如果input的长度远远大于label的长度,那么训练的时候,一开始的收敛会比较慢。在其中有一段时间cost几乎不变。此刻一定要有耐心,最终一定会收敛的。在ocr识别的这个例子上最终可以收敛到95%的精度。
3.CRNN-CTC算法实现
训练过程:
3.1、 导入库
首先,载入几个需要用到的python库,以及paddlepaddle深度学习框架。此外,因为本次项目比较大,代码比较多,为了便于学习,我们定义了几个py文件,这些py文件主要用来读取数据,或者参数设定等:
#导入我们需要的库,以及编写好的py文件
#coding:utf-8
#加上这一句coding:utf-8,解码汉字
#导入我们需要的库,以及编写好的py文件
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np #一个python的基本库,用于科学计算
import time #python的time模块,time.time()返回当前时间的时间戳
import os #Python 的 os 模块封装了常见的文件和目录操作
from paddle.fluid.layers.learning_rate_scheduler import _decay_step_counter #引入可变学习率
from paddle.fluid.initializer import * #paddle中用于初始化的库
from easydict import EasyDict #我们后面传入参数时会用到这个库
from utility import * #utility文件里面定义了一些添加参数、打印参数的函数
import functools #functools模块用于高阶函数
import argparse #argparse是python用于解析命令行参数和选项的标准模块
import sys #sys模块包含了与Python解释器和它的环境有关的函数
import data_reader
import math
import six
CRNN-CTC网络的搭建:
下面就进入到了本次实验的核心部分了:CRNN-CTC网络的搭建。
3.2、第一部分:定义函数
首先定义几个调用的函数:
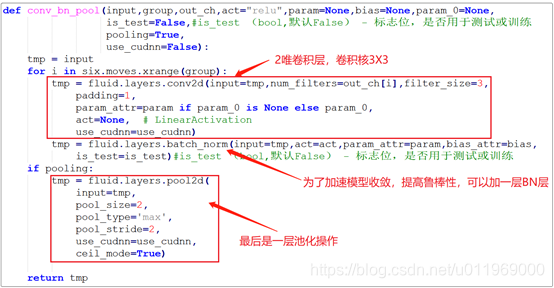
conv_bn_pool()卷积、池化操作
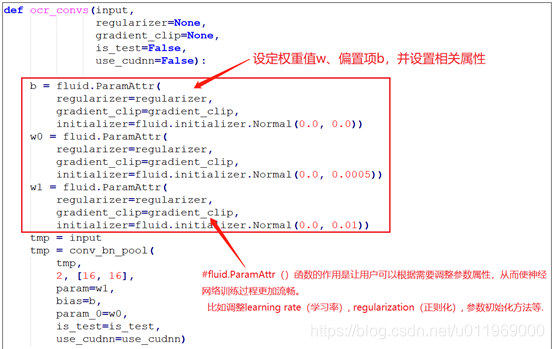
ocr_convs()设定的权重值和偏置项,并进行了初始化
encoder_net()函数主要作用是把conv层提取到的特征,转换成序列,再传入到双向RNN模块
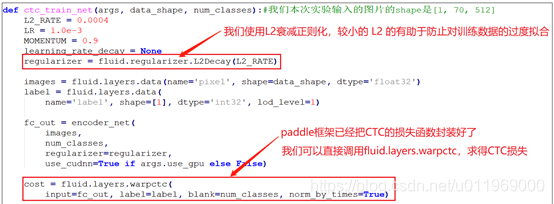
ctc_train_net()ctc的训练网络,里面含有CTC-loss,还有优化器的配置。
conv_bn_pool()函数:
这个函数含有卷积核池化操作。
ocr_convs()函数:
这个函数有conv_bn_pool()函数构成,里面含有我们设定的权重值和偏置项。并进行了初始化

ctc_train_net()函数:
这个函数就是ctc的训练网络,里面含有CTC-loss,还有优化器的配置。
实现优化器的配置:
参数创建完成后,我们需要定义一个优化器optimizer,为了改善模型的训练速度以及效果,学术界先后提出了很多优化算法,包括: Momentum、RMSProp、Adam 等,已经被封装在fluid内部,读者可直接调用。本次我们使用含有速度状态的Simple Momentum 优化器。 API介绍如下:
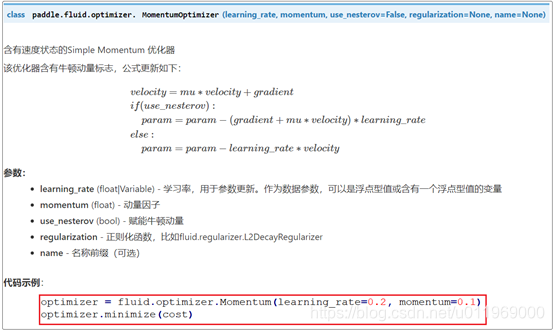
optimizer = fluid.optimizer.Momentum(learning_rate=0.2,momentum=0.1)
optimizer = minimize(cost)
3.3、第二部分定义train函数
可以定义一个 train() 函数,把以上内容放在里面,等将来可以直接调用这个函数进行训练
3.4、第三部分设置参数
在jupyter上操作,所以对于参数的传递,就不能像在命令行里面执行:python --xxx --xxx 那样了。
可以直接以下图所示的形式,利用EasyDict的字典功能,把需要设定的参数在这

参数的含义解释:
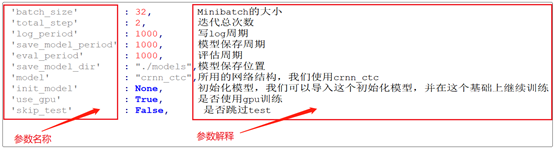
args = EasyDict({
'batch_size' : 32,
'total_step' : 2,
'log_period' : 1000,
'save_model_period' : 1000,
'eval_period' : 1000,
'save_model_dir' : "./models",
'model' : "crnn_ctc",
#'init_model' : "./init_models/model_144000",
'init_model' : None,
'use_gpu' : True,
'skip_test' : False,
})
把设置的参数再打印出来,检查一下是否真的把参数传入了我们的网络中:
print_arguments(args)
----------- Configuration Arguments -----------
batch_size: 32
eval_period: 1000
init_model: None
log_period: 1000
model: crnn_ctc
save_model_dir: ./models
save_model_period: 1000
skip_test: False
total_step: 2
use_gpu: True
------------------------------------------------
3.5、启动训练
可以执行train(args)方法,来启动训练了,训练时的输出应该是这样:
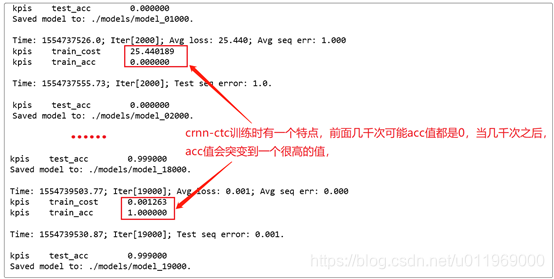
最后bug出现了
坑开始了

问题:
Warning: The EditDistance is deprecated, because maintain a modified program inside evaluator cause bug easily, please use fluid.metrics.EditDistance instead.
于是我就按它说的换成了
#计算一下输出值和label值的距离,得到error_evaluator
error_evaluator = fluid.evaluator.EditDistance(
input=decoded_out, label=casted_label)
中的fluid.evaluator.EditDistance
fluid.metrics.EditDistance
于是去paddle官网研究了一下paddle的EditDistance
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/metrics_cn/EditDistance_cn.html
import paddle.fluid as fluid
import numpy as np# 假设batch_size为128
batch_size = 128# 初始化编辑距离管理器
distance_evaluator = fluid.metrics.EditDistance("EditDistance")
# 生成128个序列对间的编辑距离,此处的最大距离是10
edit_distances_batch0 = np.random.randint(low = 0, high = 10, size = (batch_size, 1))
seq_num_batch0 = batch_sizedistance_evaluator.update(edit_distances_batch0, seq_num_batch0)
avg_distance, wrong_instance_ratio = distance_evaluator.eval()
print("the average edit distance for batch0 is %.2f and the wrong instance ratio is %.2f " % (avg_distance, wrong_instance_ratio))edit_distances_batch1 = np.random.randint(low = 0, high = 10, size = (batch_size, 1))
seq_num_batch1 = batch_sizedistance_evaluator.update(edit_distances_batch1, seq_num_batch1)
avg_distance, wrong_instance_ratio = distance_evaluator.eval()
print("the average edit distance for batch0 and batch1 is %.2f and the wrong instance ratio is %.2f " % (avg_distance, wrong_instance_ratio))
EditDistance 用于管理字符串的编辑距离。
编辑距离是通过计算将一个字符串转换为另一个字符串所需的最小编辑操作数(添加、删除或替换)来量化两个字符串(例如单词)彼此不相似的程度一种方法。
参数:
distances – 一个形状为(batch_size, 1)的numpy.array,每个元素代表两个序列间的距离。
seq_num – 一个整型/浮点型值,代表序列对的数量。
返回两个浮点数:
avg_distance:使用更新函数更新的所有序列对的平均距离。
avg_instance_error:编辑距离不为零的序列对的比例。
实操三个步骤
第1步:清空存储结果 reset()
第2步:跟新存储结果 update(distances, seq_num)
第3步:返回 eval()
原代码中的输入是两个距离,输出错误估计
error_evaluator = fluid.evaluator.EditDistance(input=decoded_out, label=casted_label)
需要研究一下fluid中的evaluator和metrics的差异
https://www.bookstack.cn/read/PaddlePaddle-1.3-fluid/103.md
太晚了,暂时暂停debug。百度太坑
下回继续补充
这篇关于复现百度云智实验出的bug:使用paddle的fluid出现please use fluid.metrics.EditDistance instead.报错问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





