mahout专题

Mahout基于余弦相似度的评估
/** 这段程序对于基于余弦相似度的评估* */package byuser;import java.io.File;import org.apache.mahout.cf.taste.common.TasteException;import org.apache.mahout.cf.taste.eval.RecommenderBuilder;import org.apache.mahout
Mahout对于GroupLens数据定制的推荐引擎
/** 这段程序是使用GroupLens定制的DataModel数据模型* 因为这里的数据是以逗号隔开的。* 这里我把数据量加大,变成了20M的数据* 这里使用的数据模型是对于GroupLens定制的GroupLensDataModel* */package byuser;import java.io.File;import java.io.IOException;import java.u

mahout利用布尔型数据评估查准率和查全率
/*利用无偏好值得布尔型* 数据评估查准率和查全率* */package byuser;import java.io.File;import java.io.IOException;import org.apache.mahout.cf.taste.common.TasteException;import org.apache.mahout.cf.taste.eval.DataModelBu

mahout实现查准率和查全率评估的配置与运行
/** 查准率和查全率评估的配置与运行* * */package byuser;import java.io.File;import org.apache.mahout.cf.taste.common.TasteException;import org.apache.mahout.cf.taste.eval.IRStatistics;import org.apache.mahout.cf.t
mahout实现基于用户的Mahout推荐程序
/** 这里做的是一个基于用户的Mahout推荐程序 * 这里利用已经准备好的数据。 * */package byuser;import java.io.File;import java.io.IOException;import java.util.List;import org.apache.mahout.cf.taste.common.TasteException;
准备Mahout所用的向量ApplesToVectors
<strong><span style="font-size:18px;">/**** @author YangXin* @info 准备Mahout所用的向量* 将苹果的信息转化为输入的向量*/package unitEight;import java.util.ArrayList;import java.util.List;import org.apache.hadoop.conf.Co
mahout聚类实例
数据准备 一般的初始数据如下所示,每行代表一组特征值。 28 88 3888 88 888 88 898 78 80 数据预处理 mahout org.apache.mahout.clustering.conversion.InputDriver -i /user/hdfs/cluster_all/test4/text -o /user/hdfs/cluster_all/te
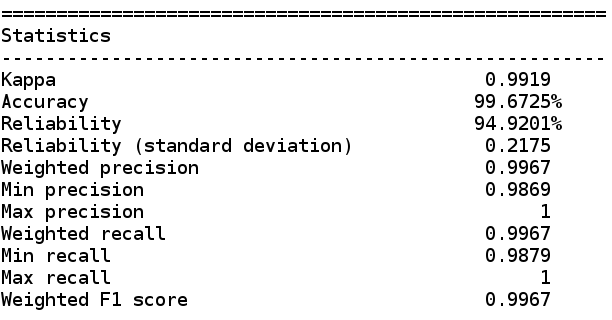
修改mahout的分类指标
mahout的默认分类指标 0.9版的分类统计如下图 0.10及0.11的分类统计如下 可以看到,相比较0.9版,新版的mahout增加了指标查准率(Weighted precision)和查全率(Weighted recall)。 修改mahout的分类指标 在此基础上,我们可以添加新的指标,比如最小查准率(Min precision ),最大查准率(Max preci
mahout之聚类实现
人们常数"物以类聚,人以群分",聚类就是将一个给定的文档集中相似项目分成不同簇的过程。 聚类设计的过程: (1)一个聚类算法( k-means、模糊k-means、canopy等) (2)相似性和不相似性的概念 a.欧式距离 b.平方欧式距离 c. 曼哈顿距离


FuzzyKmeans的Mahout实现
不得不说,google更靠谱,比google更更靠谱的是官网!!! so要好好利用google and official website!!! https://mahout.apache.org/users/clustering/fuzzy-k-means.html Fuzzy K-Means Fuzzy K-Means (also called Fuzzy C-Means

Mahout源码分析之 -- 文档向量化TF-IDF
Mahout之SparseVectorsFromSequenceFiles源码分析 一、原理 TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。 TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词

mahout实现基于物品的协同过滤算法(单机版)
参考: https://www.imooc.com/video/15792 https://blog.csdn.net/greenhandzhang/article/details/18369697 https://www.cnblogs.com/cjsblog/p/8177065.html https://blog.csdn.net/zll441488958/article/details/78

mahout报错classNotFound----jar包问题
只要用maven添加mahout-core和mahout-integration就行了,其他的包会自动依赖添加进去的。就这错,整整一天多的时间,结果发现是jar包版本的问题,妈的,只用maven就好了嘛,省的自个麻烦。
【甘道夫】Win7+Eclipse+Maven进行Mahout编程,使其兼容Hadoop2.2.0环境运行
引言 之前成功在服务器上为Mahout0.9打patch,使其支持Hadoop2.2.0。 今天的需求是:在Win7+Eclipse+Maven环境下开发Mahout程序,打jar包放到集群上,使其在Hadoop2.2.0下正常运行。 过程 步骤一:Eclipse下创建Maven工程 pom.xml: 1.引入mahout依赖 <d
【甘道夫】Mahout推荐算法编程实践
引言 Taste是曾经风靡一时的推荐算法框架,后来被并入 Mahout中,Mahout的部分推荐算法基于Taste实现。 下文介绍基于Taste实现最常用的UserCF和ItemCF。 本文不涉及 UserCF和ItemCF算法的介绍,这方面网上资料很多,本文仅介绍如何基于Mahout编程实现。 欢迎转载,请注明来源: http://blog.csdn.n

hadoop Mahout中相似度计算方法介绍(转)
来自:http://blog.csdn.net/samxx8/article/details/7691868 相似距离(距离越小值越大)优点缺点取值范围 PearsonCorrelation 类似于计算两个矩阵的协方差 不受用户评分偏高 或者偏低习惯影响的影响 1. 如果两个item相似个数小于2时 无法计算相似距离. [可以使用item相似个数门限来解决.] 没有考虑两个用户之间的交

mahout 计算方差标准差
标准差( Standard Deviation),在 概率统计中最常使用作为 统计分布程度(statistical dispersion)上的测量。标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的 平方根。它反映组内个体间的离散程度。测量到分布程度的结果,原则上具有两种 性质: 为非负数值, 与测量 资料具有相同单位。一个总量的标准差或一个 随机变量的标准差,及一个子集合样品数

Mahout协同过滤推荐
协同过滤 —— CollaborativeFiltering 协同过滤简单来说就是根据目标用户的行为特征,为他发现一个兴趣相投、拥有共同经验的群体,然后根据群体的喜好来为目标用户过滤可能感兴趣的内容。 协同过滤推荐—— Collaborative FilteringRecommend 协同过滤推荐是基于一组喜好相同的用户进行推荐。它是基于这样的一种假设:为一用户找到他真正感兴趣的内
Mahout bayes分类器
实现包括三部分:The Trainer(训练器)、The Model(模型)、The Classifier(分类器) 1、训练 首先,要对输入数据进行预处理,转化成Bayes M/R job读入数据要求的格式,即训练器输入的数据是KeyValueTextInputFormat格式,第一个字符是类标签,剩余的是特征属性(即单词)。以20个新闻的例子来说,从官网上下载的原始数据是一
Apache Mahout入门详解
1. Apache Mahout的下载与解压缩 1)发布包 http://archive.apache.org/dist/mahout/ 2)源代码 git clone https://github.com/apache/mahout.git mahout 2. Apache Mahout的环境变量设置(Bash Shell中修改~/.bash_profile,或~
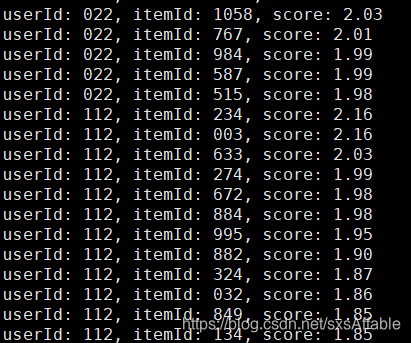
hadoop集群运行MR程序、mahout程序
hadoop集群运行MR程序 1. 启动集群2. 上传程序资源到hdfs3. 修改程序文件路径4. 安装mahout5. 提交程序到集群 本教程在配置完hadoop,可以正常运行的前提下进行 1. 启动集群 # 启动hdfssbin/start-dfs.sh# 启动yarnsbin/start-yarn.sh 使用jps命令,看到如下图所示,启动成功。 2.
![[推荐系统]Mahout中相似度计算方法介绍](https://pic.xiahunao.cn/getimgs/?img=http://images.cnblogs.com/cnblogs_com/dlts26/201206/201206200956589938.png)
[推荐系统]Mahout中相似度计算方法介绍
Mahout中相似度计算方法介绍 在现实中广泛使用的推荐系统一般都是基于协同过滤算法的,这类算法通常都需要计算用户与用户或者项目与项目之间的相似度,对于数据量以及数据类型不同的数据源,需要不同的相似度计算方法来提高推荐性能,在mahout提供了大量用于计算相似度的组件,这些组件分别实现了不同的相似度计算方法。下图用于实现相似度计算的组件之间的关系: 图1、项目相似
数据挖掘系列(5)使用mahout做海量数据关联规则挖掘
上一篇介绍了用开源数据挖掘软件weka做关联规则挖掘,weka方便实用,但不能处理大数据集,因为内存放不下,给它再多的时间也是无用,因此需要进行分布式计算,mahout是一个基于hadoop的分布式数据挖掘开源项目(mahout本来是指一个骑在大象上的人)。掌握了关联规则的基本算法和使用,加上分布式关联规则挖掘后,就可以处理基本的关联规则挖掘工作了,实践中只需要把握业务,理解数据便可游刃有余。
Mahout学习总结
Mahout学习总结 一、Mahout定义 ①Mahout是一个算法库,集成了很多算法; ②Mahout是Apache SoftWare Foundation(ASF)旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序; ③Mahout包含许多实现,包括:聚类、分类、推荐过滤、频繁子项挖掘