keypoint专题
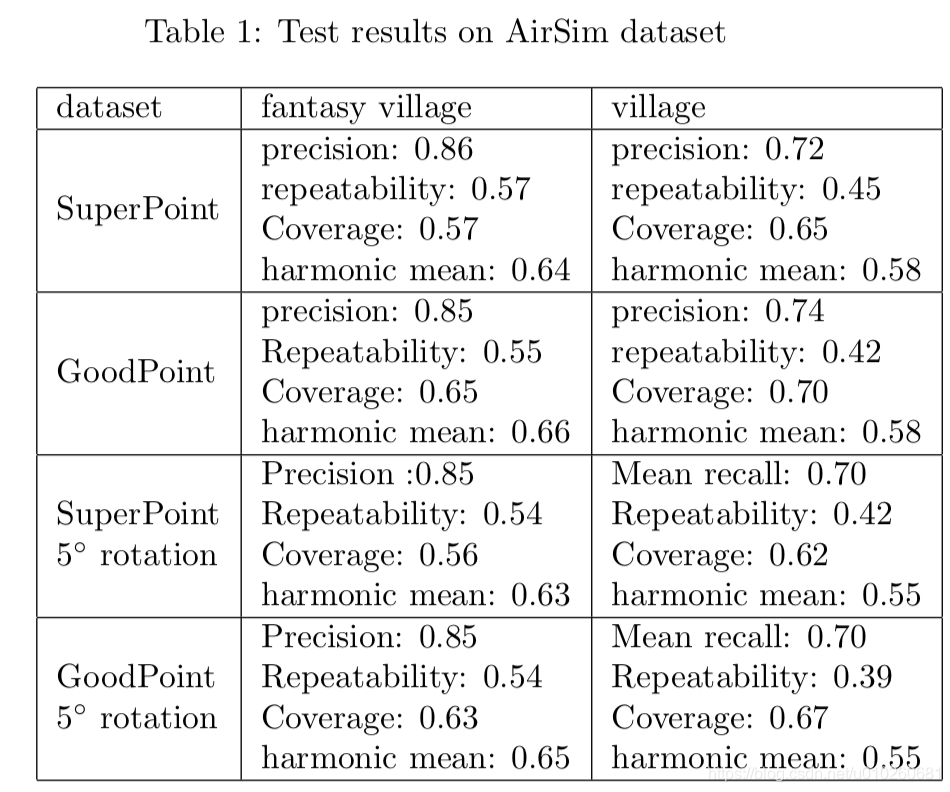
GoodPoint: unsupervised learning of keypoint detection and description∗
主要提供了一种无监督的deep feature的提取方式 good point应该满足: they should be distributed more or less evenly throughout the image; have good repeatability between different view- points; be recognizable a

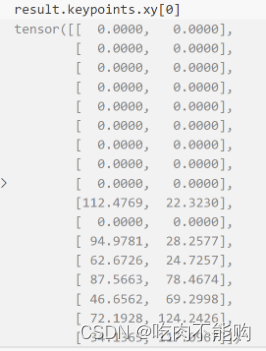
Python版Opencv记录:安装扩展版OpenCV及提取KeyPoint中的x,y坐标
目录 由KeyPoint格式的特征点中提取出x,y坐标安装扩展版OpenCV 由KeyPoint格式的特征点中提取出x,y坐标 points2f = cv2.KeyPoint_convert(keypoints) #将KeyPoint格式数据中的xy坐标提取出来。 安装扩展版OpenCV pip uninstall opencv-pythonpip install op
yolov8 pose keypoint解读
yolov8进行关键点检测的代码如下: from ultralytics import YOLO# Load a modelmodel = YOLO('yolov8n.pt') # pretrained YOLOv8n model# Run batched inference on a list of imagesresults = model(['im1.jpg', 'im2.jpg']
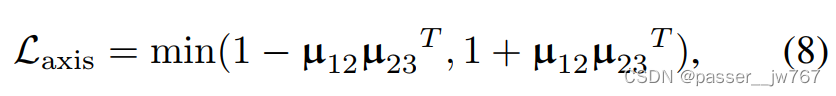
【计算机图形学】3D Implicit Transporter for Temporally Consistent Keypoint Discovery
对3D Implicit Transporter for Temporally Consistent Keypoint Discovery的简单理解 文章目录 1. 现有方法限制和文章改进2. 方法2.1 寻找时间上一致的3D特征点2.1.1 3D特征Transporter2.1.2 几何隐式解码器2.1.3 损失函数 2.2 使用一致特征点的操纵 1. 现有方法限制和文章改
pts_1.push_back ( pixel2cam( keypoint_1[m.queryIdx].pt, K)
pixel2cam(意思是pixel to camera)该函数的功能是完成两幅图像中匹配特征点的像素坐标到相机坐标的转换。最终的结果是得到一个2d的相机坐标(x,y),该坐标存储在pts_1与pts_2中。 pts_1.push_back ( pixel2cam( keypoint_1[m.queryIdx].pt, K) );//pixel2cam(这不是opencv提供的),用来将像素坐

det_keypoint_unite的C++部署(jetson)
文章目录 环境准备硬件软件 trt参数配置CMakeLists.txt编译和运行运行结果 环境准备 硬件 Jetson AGX Orin 64GB 软件 gcc/g++ >= 5.4(推荐8.2)cmake >= 3.10.0jetpack >= 4.6.1 如果需要集成Paddle Inference后端,在Paddle Inference预编译库页面根据开发环境选择

基于det_keypoint_unite的ROS功能包(jetson部署)
文章目录 硬件软件FastDeploy编译CMakeLists.txt头文件源代码 硬件 Jetson AGX Orin 64GB 软件 gcc/g++ >= 5.4(推荐8.2)cmake >= 3.10.0jetpack >= 4.6.1opencv=4.2.0 FastDeploy编译 git clone https://github.com/PaddlePadd

CornerNet:经典keypoint-based方法,通过定位角点进行目标检测 | ECCV2018
论文提出了CornerNet,通过检测角点对的方式进行目标检测,与当前的SOTA检测模型有相当的性能。CornerNet借鉴人体姿态估计的方法,开创了目标检测领域的一个新框架,后面很多论文都基于CorerNet的研究拓展出新的角点目标检测 来源:晓飞的算法工程笔记 公众号 论文: CornerNet: Detecting Objects as Paired Keypoints 论
![[论文阅读]Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression](https://img-blog.csdnimg.cn/3c257eceb842475b88de9817a67fcf85.png)
[论文阅读]Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
该论文发表于CVPR2021 Background 背景 该论文关注的是的是自底向上的关键点回归人体姿态估计,作者认为回归关键点坐标的特征必须集中注意到关键点周围的区域,才能够精确回归出关键点坐标。因此提出了一种名为解构式关键点回归(DEKR)的方法。这种直接回归坐标的方法超过了以前的关键点热度图检测并组合的方法,并且在 COCO 和 CrowdPose 两个数据集上达到了目前自底向上姿态
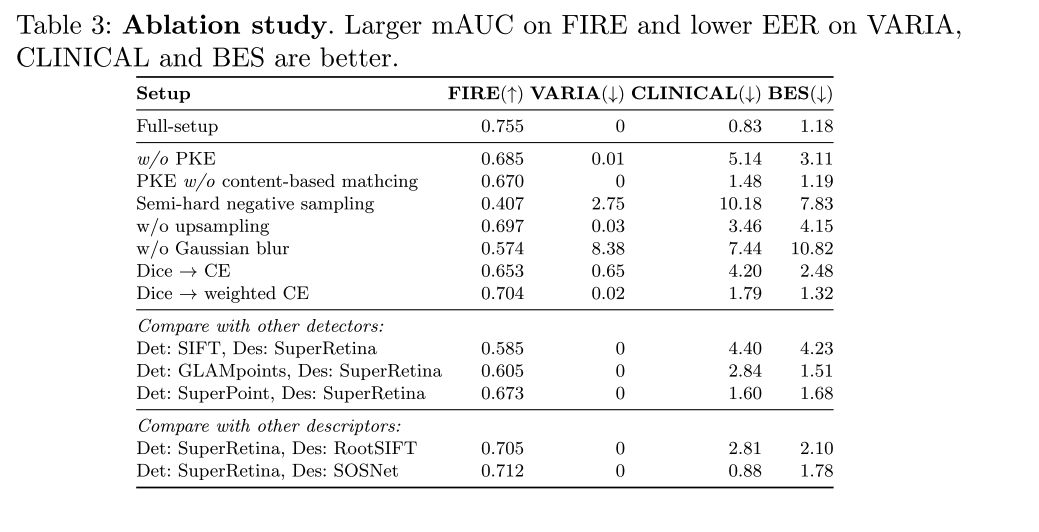
【论文阅读】Semi-Supervised Keypoint Detector and Descriptor for Retinal Image Matching (ECCV2022)
文章目录 题目论文概述:摘要引言相关工作视网膜图像匹配(Retinal Image Matching,RIM)的进展自然图像匹配的进展 方法网络结构训练算法基于特征点的视网膜图像匹配 实验验证通用设置任务一:视网膜图像配准任务二:基于视网膜的身份认证 结论 题目 Semi-Supervised Keypoint Detector and Descriptor for Retin

FREAK: Fast Retina Keypoint全文翻译
英文论文和翻译链接:https://pan.baidu.com/s/1HKHH5bFopQBX3EslVsICPg 提取码:yyds FREAK: Fast Retina Keypoint FREAK:快速视网膜关键点 摘要 大量的视觉应用程序依赖于匹配图像中的关键点。过去十年的特点是朝着更快、更鲁棒的关键点和关联算法的军备竞赛:尺度不变换特征(SIFT)[17],加速鲁棒特征(SURF)[4