本文主要是介绍[论文阅读]Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

该论文发表于CVPR2021
Background 背景
该论文关注的是的是自底向上的关键点回归人体姿态估计,作者认为回归关键点坐标的特征必须集中注意到关键点周围的区域,才能够精确回归出关键点坐标。因此提出了一种名为解构式关键点回归(DEKR)的方法。这种直接回归坐标的方法超过了以前的关键点热度图检测并组合的方法,并且在 COCO 和 CrowdPose 两个数据集上达到了目前自底向上姿态检测的最好结果

上图作者选取了鼻子和两个脚踝共三个关键点展示了模型在回归关键点时注意到的区域,左图为Baseline,右图使用了DEKR方法,可以很明显的看出 DEKR 的自适应卷积和多分支结构确实让特征更加集中注意到关键点周围的区域。
创新点
DEKR 方法有两个重要内容:
1.自适应卷积(感觉就是可变卷积);
2.多分支结构,每个分支都会针对某种关键点利用自适应卷积学习,专注于关键点周围的像素特征,并且利用该特征回归该关键点的位置。
Method 方法
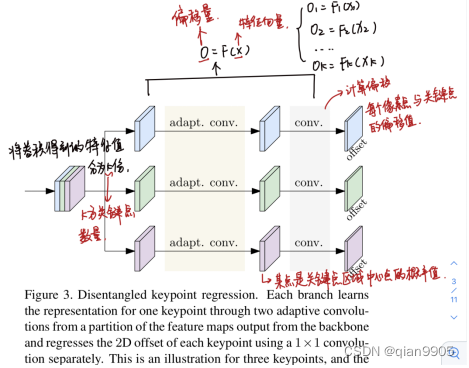
上图就是解构式关键点回归(DEKR)的框架
作者将骨干网络生成的特征分为K份,每份送入一个单独的分支。每个分支用各自的自适应卷积去学习一种关键点的特征,最后用一个卷积输出一个这种关键点的二维偏移值向量。在图中,为了表示方便,假设了 K=3,事实上,在 COCO 数据集的实验中,K 为17。
该方法运用了一个多分支平行自适应卷积去学习特征以得到K个关键点的回归值,这样就能够使得每个特征都是关注于它所对应的那个关键点区域的。
O = F(X),是关键点回归公式,其中:O代表关键点坐标回归预测得出的偏移向量。X代表backbone输出的特征。F就是一个单独分支,用全图特征预测出所有的关键点偏移量。而作者提出使用多分支的结构,每个分支都使用自适应的卷积网络然后可以为每个相对应的单个关键点回归偏移量。这里的backbone使用的是HRNet。
因此就把上述的X特征图输出分为K份特征图,即X1.X2.X3````(这里将特征分为K份的话,每个关键点学习的特征图都不一样,那么会不会使得有些关键点结果好,有一些关键点结果没那么好。)
并且对每个关键点得到的对应特征图预测得出相应的便宜向量Ok.相应的公式如下:
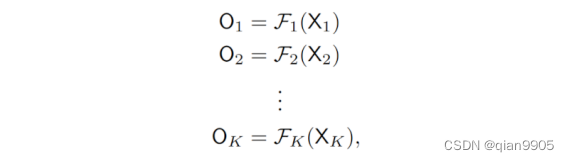
上述每个公式都代表了其中一个分支为了回归一种关键点所进行的操作。可以看出,这些分支结构相同,但是被相互独立地训练(相互独立地训练可能可以通过优化特征图的分解来改善各个关键点的回归结果)。

其实就是找一个像素点q的周围九个点(激活),上面的那个G就是偏移量。用该像素点周围特征进行预测。

从上图可以看出,该任务激活的关键点周围的九个点,使用了自适应卷积使得卷积核的形状可以改变。
贡献
- 提出了需要准确地回归关键点坐标的特征就需要关注于关键点周围的区域的观点。
- 提出的DEKR方法能够通过两个简单的模式获得解构式的特征。这两个简单的方法模式分别是自适应卷积网络和多分支结构,因此,每个特征都关注于一个关键点区域并且通过对应关键点的这个特征得出的预测是准确的。
- 这个提出来的直接回归方法在COCO和CrowdPose上表现良好,在自底向上的姿态估计工作中达到了SOTA。
这篇关于[论文阅读]Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
