headless专题

树莓派 4 使用 WiFi 从 SSD Headless 启动
树莓派 4 使用 WiFi 从 SSD Headless 启动 树莓派已经默认支持从 SSD 启动,可以根据官方提供的工具初始化树莓派系统并启动;尝试通过安装 Ubuntu Server,不使用网线、显示器、键盘等,从 SSD 直接启动 依赖 树莓派 4MacSSD 安装 Ubuntu Server 1. 安装 Raspberry Pi Imager Raspberry Pi Imag

爬虫 headless 访问 知道创宇 加速乐 CDN 网站
通过 requests.get 直接请求网站首页,返回 521 错误提示码,返回结果是js代码。这是采用加速乐反爬技术,在访问前先判断客户端的cookie是否正确,如果不正确,返回521状态码和一段js代码,并且进行set-cookie操作,返回的js代码经过浏览器执行又会生成新的cookie,这两个cookie一起发送给服务器,才会返回正确的网页内容 试了下代码demo如下,有cookie就带上

chromedriver headless 模式屏蔽日志
headless无头浏览器模式下有很多日志信息,如下, 将日志等级设定为 3 即可 chrome_options.add_argument('log-level=3')#info(default) = 0#warning = 1#LOG_ERROR = 2#LOG_FATAL = 3 DevTools listening on ws://127.0.0.1:55019/devtoo

使用 Headless Chrome 进行页面渲染
本文主要介绍了使用 Node.js 利用 Chrome Remote Protocol 远程控制 Headless Chrome 渲染界面的基础用法。 全文阅读:使用 Headless Chrome 进行页面渲染 了解更多前沿技术资讯,获取深度技术文章推荐,请关注CSDN研发频道微博。 欢迎加入“CSDN前端开发者”群,与更多专家、技术同行进行热点、难点技术交流。请扫描以下二维码

The program 'jps' can be found in the following packages: * openjdk-8-jdk-headless * openjdk-9-jdk
参考:https://www.chendalei.com/jps_can_be_found 输入env 查看系统环境变量是否存在JAVA_HOME,发现不存在。 在~添加JAVA环境变量: root@xxxx:~# vim ~/.profile 在末尾添加: root@xxxx:~# source ~/.profile 再次查看env,JAVA_HOME已成功添加
译文:Puppeteer 与 Chrome Headless —— 从入门到爬虫
随时随地技术实战干货,获取项目源码、学习资料,请关注源代码社区公众号(ydmsq666) from:http://csbun.github.io/blog/2017/09/puppeteer/ Puppeteer 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具。正因为这个官方声明,许多业内自动化测试库都已经停止维护,包括 PhantomJS。Sele
Go使用chromedp库操作headless-chrome爬取JS画出来的网站
随着类似Vue、Angular这类通过JS将web页面"画"出来的前端框架的流行,爬取网页不再像以前那样随便发个GET请求,解析HTML就能搞定了。对于使用这类框架制作的SPA(Single Page Web Application)网站来说,必须使用一个全功能浏览器将JS脚本执行一遍才能获得想要的数据,除此之外别无他法。这里我们介绍如何使用Go语言的chromedp库来操作headless-ch
![[Meachines][Easy]Headless](https://img-blog.csdnimg.cn/img_convert/9c5f5a228c376eae770072abd6155e9c.jpeg)
[Meachines][Easy]Headless
Tools https://github.com/MartinxMax/MDOG 针对XXS攻击 Main $ nmap -sC -sV 10.10.11.8 --min-rate 1000 类似于留言板 通过目录扫描,发现一个仪表盘 $ gobuster dir -u "http://10.10.11.8:5000" -w /usr/share/wordlists/di

探索Headless组件与Tailwind CSS的魔力——前端开发的新选择
探索Headless组件与Tailwind CSS的魔力——前端开发的新选择 引言 前端技术日新月异,新的框架和工具层出不穷。今天,我将与大家深入探讨两个在前端开发中备受瞩目的技术:Headless组件和Tailwind CSS。它们各自在前端领域有着独特的价值和影响力,结合起来更是能够为我们带来前所未有的开发体验。接下来,我将为大家介绍它们在实际应用场景中的表现。 Headless组件:功
实例:使用puppeteer headless方式抓取JS网页
puppeteer google chrome团队出品的puppeteer 是依赖nodejs和chromium的自动化测试库,它的最大优点就是可以处理网页中的动态内容,如JavaScript,能够更好的模拟用户。 有些网站的反爬虫手段是将部分内容隐藏于某些javascript/ajax请求中,致使直接获取a标签的方式不奏效。甚至有些网站会设置隐藏元素“陷阱”,对用户不可见,脚本触发则认为是机
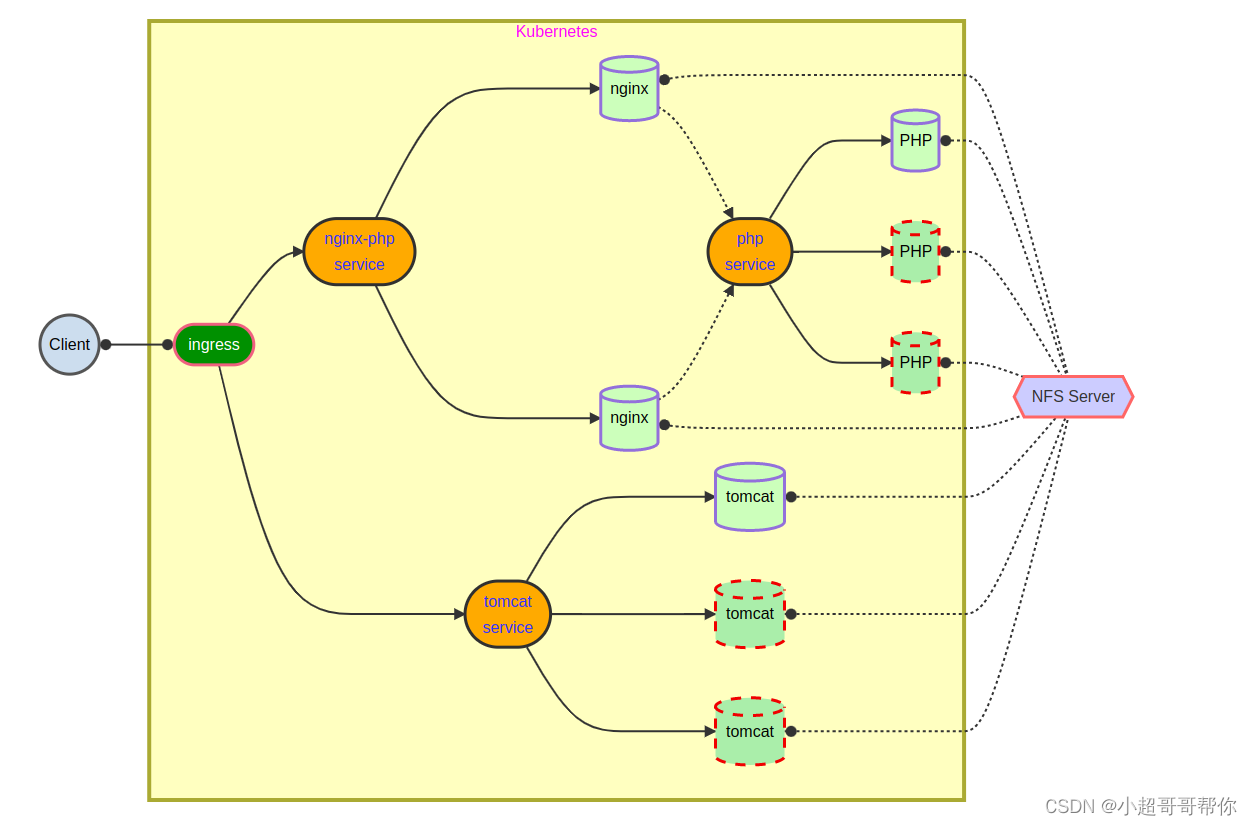
控制器详解、临时任务与计划任务、Headless服务/弹性云服务部署(HPA)、弹性云项目实战
kubernetes 控制器 Deployment Deploy 图例 Deploy 控制器 # 清理 Pod ,使用控制器创建[root@master ~]# kubectl delete pod --all# 资源对象模板[roo
在Java SE平台中使用Headless模式
https://www.oracle.com/technical-resources/articles/javase/headless.html
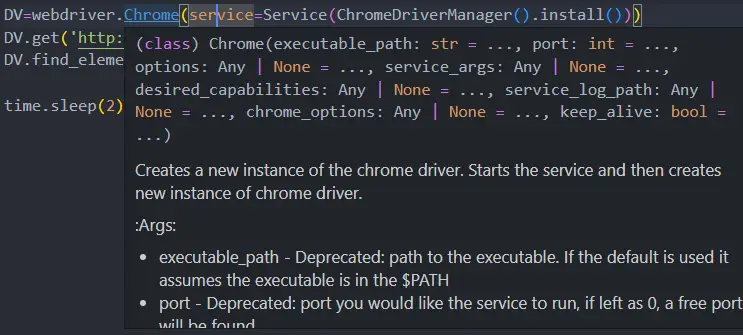
Python Selenium Headless:以 Headless 模式打开 Chrome 浏览器
本篇文章介绍了如何在 Python 中使用 Selenium 运行浏览器无头模式。 在 Python 中使用 Selenium 以无头模式运行 Chrome 浏览器 要说 headless 浏览器,你也可以称它们为真正的浏览器,只不过它们是在后台运行的; 您将无法在任何地方看到它们,但它们仍在后台运行。 在某些情况下您会需要这种无头浏览器。 因为当您在普通浏览器中工作时,您将看到 UI
AD9371 官方例程 NO-OS 主函数 headless 梳理(二)
AD9371 系列快速入口 AD9371+ZCU102 移植到 ZCU106 : AD9371 官方例程构建及单音信号收发 ad9371_tx_jesd -->util_ad9371_xcvr接口映射: AD9371 官方例程之 tx_jesd 与 xcvr接口映射 AD9371 官方例程 时钟间的关系与生成 : AD9371 官方例程HDL详解之JESD204B TX侧时钟生成(一) J
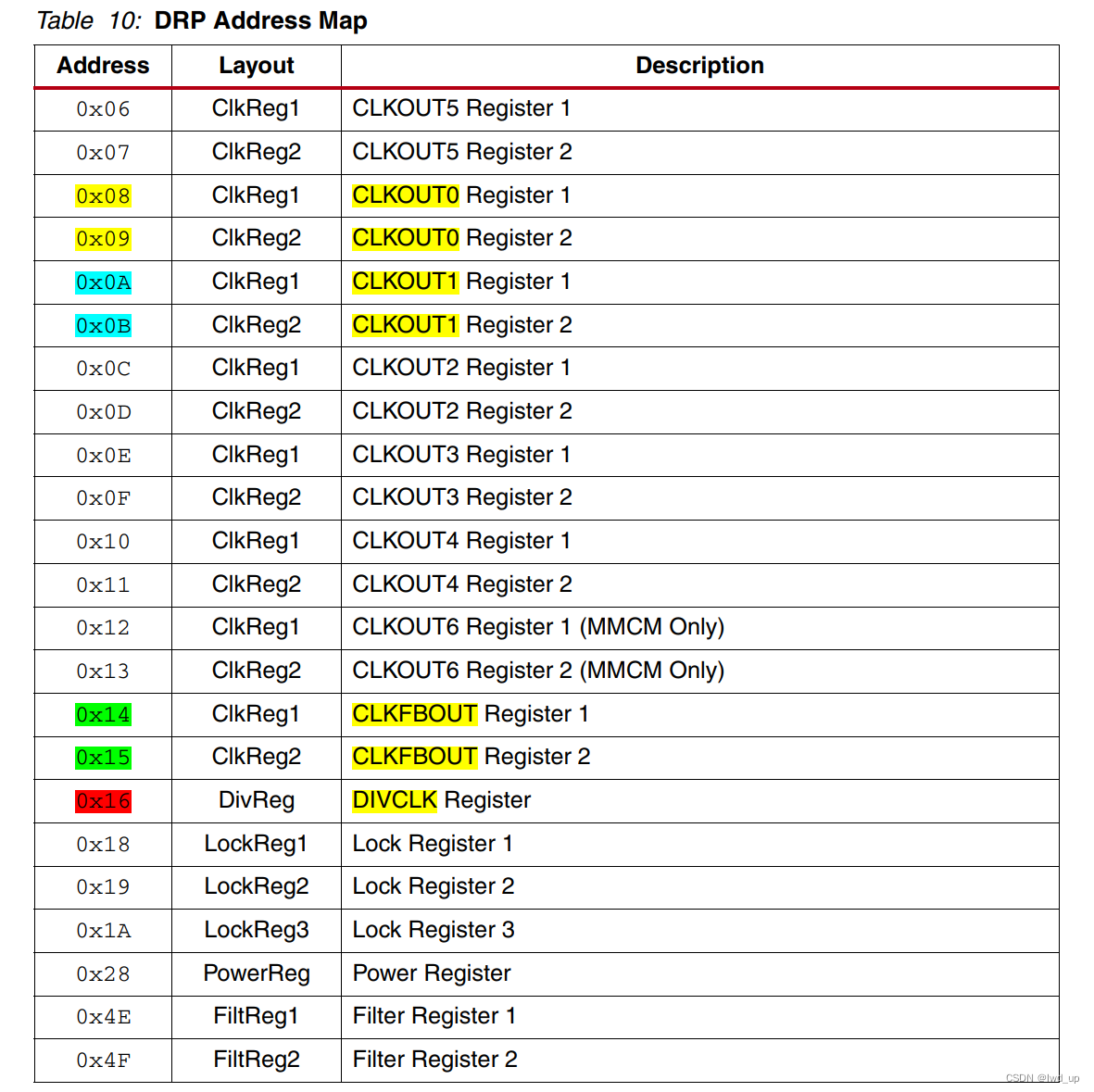
AD9371 官方例程 NO-OS 主函数 headless 梳理(一)
AD9371 系列快速入口 AD9371+ZCU102 移植到 ZCU106 : AD9371 官方例程构建及单音信号收发 ad9371_tx_jesd -->util_ad9371_xcvr接口映射: AD9371 官方例程之 tx_jesd 与 xcvr接口映射 AD9371 官方例程 时钟间的关系与生成 : AD9371 官方例程HDL详解之JESD204B TX侧时钟生成(一) J
基于Headless构建高可用spark+pyspark集群
1、创建Headless Service服务 Headless 服务类型并不分配容器云虚拟 IP,而是直接暴露所属 Pod 的 DNS 记录。没有默认负载均衡器,可直接访问 Pod IP 地址。因此,当我们需要与集群内真实的 Pod IP 地址进行直接交互时,Headless 服务就很有用。 其中Service的关键配置如下:clusterIP: None,不让其获取clusterIP , DN
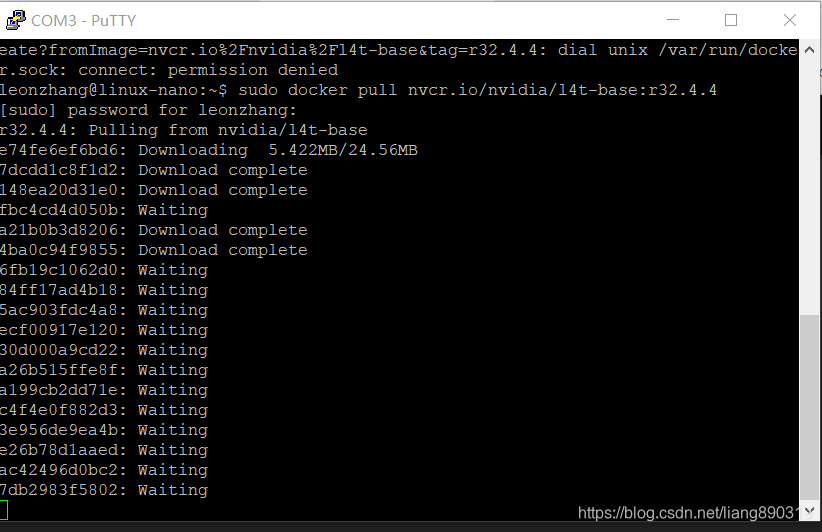
JETSON NANO 2G使用笔记1-开箱 装系统-headless模式。无桌面。无显示器
Getting Started with Jetson Nano 2GB Developer Kit https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-2gb-devkit#prepare sd格式化软件 镜像软件和镜像烧录软件 https://www.sdcard.org/downloads/f
【Chrome】使用k8s、docker部署无头浏览器Headless,Java调用示例
什么是无头浏览器? 无头浏览器是一种没有图形用户界面的浏览器。无头浏览器不通过其图形用户界面(GUI)控制浏览器的操作,而是使用命令行。 为什么要用Chrome无头? Chrome Headless用于抓取(谷歌)、测试(开发者)和黑客(黑客)。搜索引擎,使用它来呈现页面、生成动态内容和索引来自单页Web应用程序的数据。SEO工具,用来分析网站,提出如何改进的建议。监控工具,用于监控Web应
![VirtualBox Headless Frontend_error:g_bGuestPowerOff fastpipeapi.cpp:1161——[Solution]](https://img-blog.csdnimg.cn/07f4cf4806ce44af9eae345b5d9f66bf.jpeg)
VirtualBox Headless Frontend_error:g_bGuestPowerOff fastpipeapi.cpp:1161——[Solution]
1.win+R 2.输入cmd指令,进入命令行窗口。 3.运行如下命令 bcdedit /set hypervisorlaunchtype off 提示操作完成后,重启电脑即可。 Markdown 是什么? Markdown 是一种轻量级的标记语言,可用于在纯文本文档中添加格式化元素。Markdown 由 John Gruber 于 2004 年创建,如今已成为世
2017年网页抓取:先进的Headless Chrome技巧
原文:Web Scraping in 2017: Advanced Headless Chrome Tips & Tricks 作者: Martin Tapia 翻译:不二 Headless Chrome是Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有 Chrome 支持的特性运行程序。相比于现代浏览器,Headless Chrome 更加方便测试web应用,获
Headless CMS(strapi)
Headless CMS(strapi) 玩了玩微信小程序的cms,感觉还挺好的,不过目前处于公测阶段,后续应该还是要收费的,不过这个操作还挺好的。文档地址 不过其获取图片的时候默认用到的是小城云开发环境的链接样式,如果用在公开网站上的话,需要中间有一步换取临时链接的步骤。文档地址。 总体来说目前这个功能还是很好的,可以减少了很大的开发工作。 然后发现了个关键词,这个叫做 headless c