本文主要是介绍【Chrome】使用k8s、docker部署无头浏览器Headless,Java调用示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是无头浏览器?
无头浏览器是一种没有图形用户界面的浏览器。无头浏览器不通过其图形用户界面(GUI)控制浏览器的操作,而是使用命令行。
为什么要用Chrome无头?
Chrome Headless用于抓取(谷歌)、测试(开发者)和黑客(黑客)。- 搜索引擎,使用它来呈现页面、生成动态内容和索引来自单页
Web应用程序的数据。 SEO工具,用来分析网站,提出如何改进的建议。- 监控工具,用于监控
Web应用中JavaScript的执行时间。 - 一个测试工具,用于呈现页面并将其与以前的版本进行比较,以跟踪用户界面的变化。
- 使用
Headless Chrome的主要优势在于,用户可以编写脚本以编程方式运行浏览器,并快速、大规模地执行抓取、分析或成像网站等任务,而无需打开浏览器的GUI并点击一百万个东西。 - 要做到这一点需要三样东西:无头
Chrome、DevTools协议和木偶师。 - 你已经见过
Chrome Headless了。Dev Protocol是Chrome DevTools的远程实例,在另一个浏览器中打开。它允许你“通过你的眼睛”看到无头Chrome,而不需要运行浏览器GUI。Puppeteer是一个节点库,它为开发者提供了通过DevTools协议编程控制无头Chrome的工具。 - 把三者结合起来,就可以用
Headless Chrome编写重复的大规模动作脚本,并快速大规模运行。
安装chrome浏览器并测试
基本上每个程序员都会安装chrome浏览器,如果没有安装的可以去下载安装,安装好之后,可以直接利用chrome浏览器执行无头浏览器的命令,假设chrome浏览器安装路径是: C:\Users\administrator\AppData\Local\Google\Chrome\Application\chrome.exe,可以执行如下命令
C:\Users\best5\AppData\Local\Google\Chrome\Application\chrome.exe --headless --hide-scrollbars --disable-gpu --screenshot=e:\chrome.jpg --window-size=1280,1696 https://www.baidu.com
会生成一个chrome.jpg文件
Docker运行
- 拉取镜像:
docker pull browserless/chrome:latest - 运行容器:
docker run -p 3000:3000 browserless/chrome:latest - 使用浏览器访问:
http://localhost:3000/
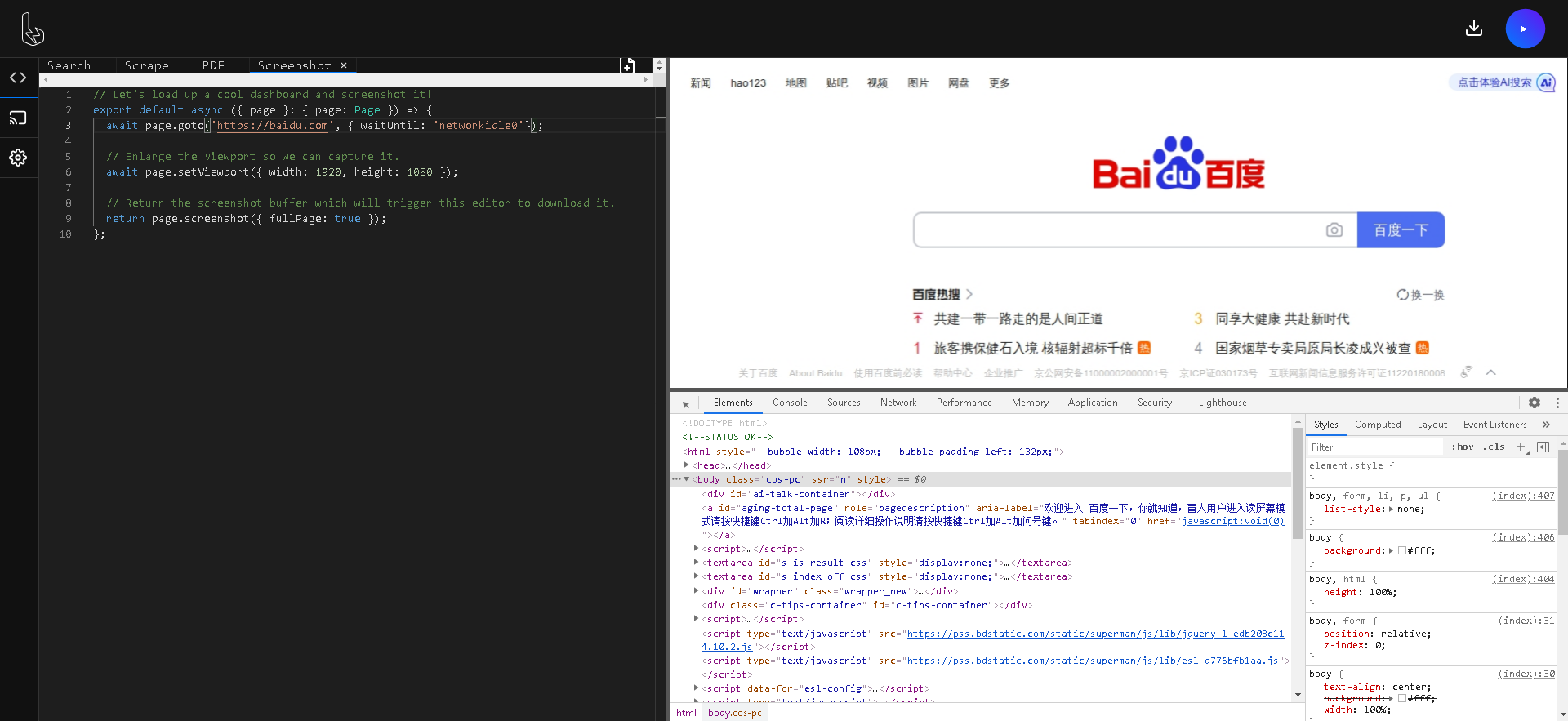
看起来很厉害的样子
k8s部署
- 编写部署
ymal文件,并命名browserless-chrome.yaml
---
apiVersion: v1
kind: Service
metadata:name: browserless-chromenamespace: kube-publiclabels:app: browserless-chrome
spec:type: NodePortports:- name: websocketport: 30000targetPort: 3000nodePort: 30000selector:app: browserless-chrome
---
apiVersion: apps/v1
kind: Deployment
metadata:name: browserless-chromenamespace: kube-public
spec:replicas: 1revisionHistoryLimit: 0 #Replica Sets中的历史数量selector:matchLabels:app: browserless-chrometemplate:metadata:labels:app: browserless-chromespec:containers:- name: browserless-chromeimagePullPolicy: Alwaysimage: browserless/chrome:latestenv:- name: PORTvalue: "3000"securityContext:runAsNonRoot: truerunAsUser: 999runAsGroup: 999ports:- containerPort: 3000livenessProbe:tcpSocket:port: 3000initialDelaySeconds: 5failureThreshold: 2periodSeconds: 60readinessProbe:tcpSocket:port: 3000initialDelaySeconds: 5periodSeconds: 10startupProbe:tcpSocket:port: 3000failureThreshold: 30periodSeconds: 10resources:requests:cpu: 0.2memory: 300Milimits:cpu: 1memory: 1GiimagePullSecrets:- name: puller
kubectl apply -f browserless-chrome.yaml
把镜像推送到私有仓库
- 给镜像重新打标签:
docker tag browserless/chrome:latest xxx.cn/base/browserless-chrome:latest - 推送到私有仓库:
docker push imgsreg.ipipa.cn:20443/base/browserless-chrome:latest
Java调用示例
- 在
pom.xml中添加以下依赖
<dependency><groupId>io.github.fanyong920</groupId><artifactId>jvppeteer</artifactId><version>1.1.5</version>
</dependency>
- 使用本地
chrome程序调用示例代码
public class BrowserTest {@SneakyThrows@Testvoid test() {//自动下载,第一次下载后不会再下载
// BrowserFetcher.downloadIfNotExist(null);ArrayList<String> arrayList = new ArrayList<>();//生成pdf必须在无头模式下才能生效LaunchOptions options = new LaunchOptionsBuilder().withExecutablePath("C:\\Users\\administrator\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe").withArgs(arrayList).withHeadless(true).build();arrayList.add("--no-sandbox");arrayList.add("--disable-setuid-sandbox");Browser browser = Puppeteer.launch(options);Page page = browser.newPage();page.goTo("https://www.baidu.com");PDFOptions pdfOptions = new PDFOptions();pdfOptions.setPath("test.pdf");page.pdf(pdfOptions);page.close();browser.close();}
}
- 使用
wetsocket远程调用chrome示例代码
public class BrowserTest {@SneakyThrows@Testvoid test() {//自动下载,第一次下载后不会再下载
// BrowserFetcher.downloadIfNotExist(null);ArrayList<String> arrayList = new ArrayList<>();//生成pdf必须在无头模式下才能生效LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();arrayList.add("--no-sandbox");arrayList.add("--disable-setuid-sandbox");Browser browser = Puppeteer.connect(options, "ws://localhost:3000", null, null);Page page = browser.newPage();page.goTo("https://www.baidu.com");PDFOptions pdfOptions = new PDFOptions();pdfOptions.setPath("test.pdf");page.pdf(pdfOptions);page.close();browser.close();}
}
在工程目录下会生成test.pdf文件,可以打开看看效果
这篇关于【Chrome】使用k8s、docker部署无头浏览器Headless,Java调用示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






