hanlp专题

elasticsearch hanlp 插件安装操作
elasticsearch hanlp 插件安装操作 下载 hanlp 插件上传hanlp插件到elasticsearch服务器安装hanlp插件kibana测试 下载 hanlp 插件 这里大家根据自己对应的 elasticsearch 版本下载匹配版本的 hanlp 插件,由于 hanlp 及 elasticsearch 各个版本之间差别较大,如果版本不匹配可能导致 hanl
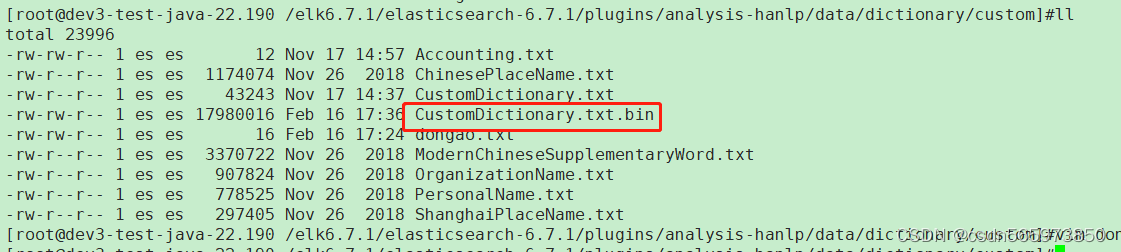
elasticsearch hanlp插件自定义词典配置
elasticsearch hanlp插件自定义词典配置 背景自定义词典配置新增自定义词典修改 hanlp.properties自动加载词典 自定义词典测试 背景 在使用 elasticsearch 的过程中,总会遇到与分词相关的需求,这里将针对常用的 elasticsearch hanlp (后面统称为 es hanlp)分词插件进行讲解演示配置自定义业务字典,提高 es ha

hanlp for elasticsearch(基于hanlp的es分词插件)
摘要:elasticsearch是使用比较广泛的分布式搜索引擎,es提供了一个的单字分词工具,还有一个分词插件ik使用比较广泛,hanlp是一个自然语言处理包,能更好的根据上下文的语义,人名,地名,组织机构名等来切分词 elasticsearch-analysis-hanlp插件地址:https://github.com/pengcong90/elasticsearch-analysis-han
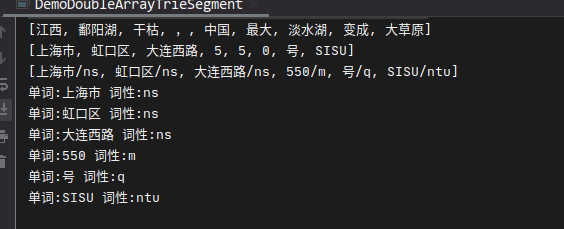
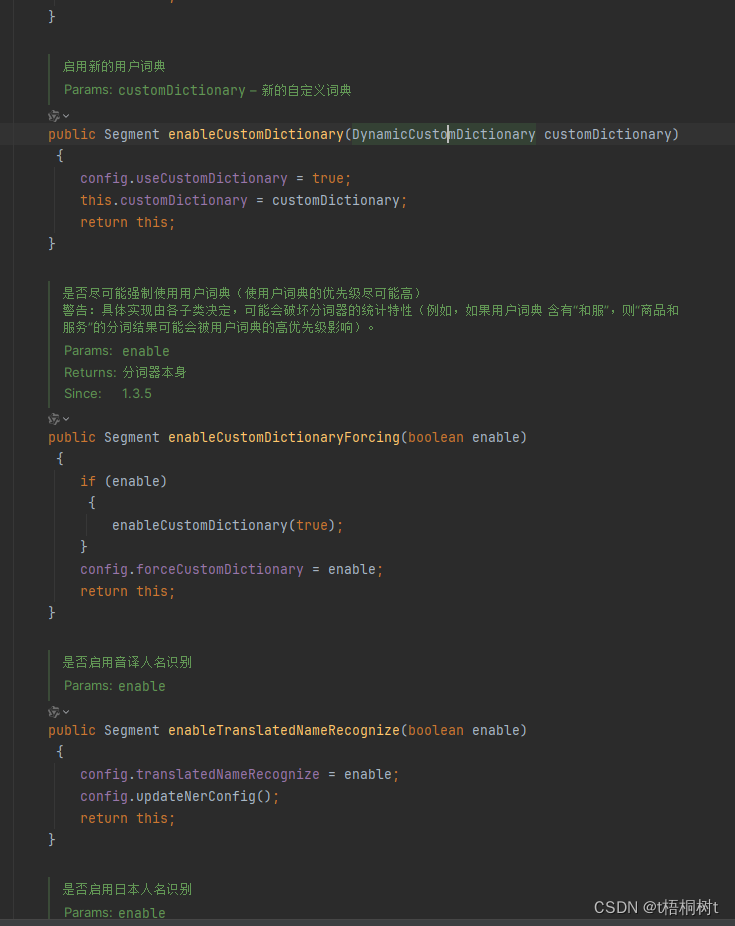
hanlp中文分词器(ing...)
目前的工作中需要对文本进行分词分析词性,找出热词,经过一系列的调研感觉hanlp这个库还不错,想先试用看看 介绍 HanLP(Han Language Processing)是一个由一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。HanLP分词器是其中的一个重要组件,用于将连续的中文文本切分成一个个有意义的词语。python和java它都支持, 现在要是用的是ja
![pip install hanlp[full]无法安装](/front/images/it_default.gif)
pip install hanlp[full]无法安装
如果最近不能使用hanlp或是版本问题 解决方案: 1. pip install hanlp[full] 2. 如果出现权限问题: sudo pip install hanlp[full] 如果在安装过程中出现zsh不兼容:no matches found的问题 解决方案: ~/.zprofile 文件加入,mac在终端输入: setopt no_nomatch 之后,更新配置

hanlp,pkuseg,jieba,cutword分词实践
总结:只有jieba,cutword,baidu lac成功将色盲色弱成功分对,这两个库字典应该是最全的 hanlp[持续更新中] https://github.com/hankcs/HanLP/blob/doc-zh/plugins/hanlp_demo/hanlp_demo/zh/tok_stl.ipynb import hanlp# hanlp.pretrained.tok.ALL

java调用Hanlp分词器获取词性;自定义词性字典
若解读用户输入的一段话,找出输入内容的构成(名词、动词、形容词、地名、人名等)以便进一步的处理。 一、配置pom,导包: <dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><version>portable-1.6.8</version></dependency> 二、java代码实现分词:
Java实现汉字拼音转换和关键字分词(pinyin4j、hanlp)
文章目录 pinyin4jhanlp关键字分词 pinyin4j 添加maven依赖 <dependency><groupId>com.belerweb</groupId><artifactId>pinyin4j</artifactId><version>2.5.0</version></dependency> 获取文本拼音 /*** 获取文本拼音* @param c

HanLP的依存分析
# 前言 HanLP2.1支持包括简繁中英日俄法德在内的104种语言上的10种联合任务:分词(粗分、细分2个标准,强制、合并、校正3种词典模式)、词性标注(PKU、863、CTB、UD四套词性规范)、命名实体识别(PKU、MSRA、OntoNotes三套规范)、依存句法分析(SD、UD规范)、成分句法分析、语义依存分析(SemEval16、DM、PAS、PSD四套规范)、语义角色标注、词

SpringBoot进行自然语言处理,利用Hanlp进行文本情感分析
. # 📑前言 本文主要是SpringBoot进行自然语言处理,利用Hanlp进行文本情感分析,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页放风讲故事 🌄每日一句:努力一点,优秀一点 目录 文章目录 **目录**一、说明二、自然语言处理简介三、Hanlp文本分类与情感分析基本概念语料库用Map描述用文件夹描述数据
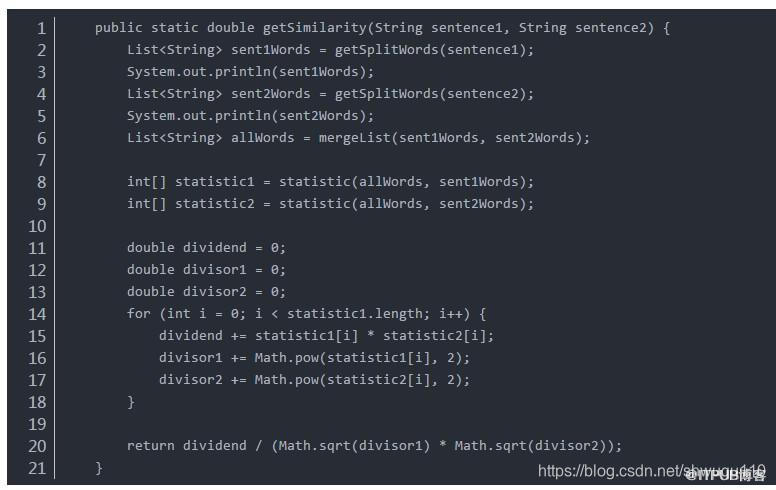
Java利用hanlp完成语句相似度分析的方法详解
在做kaoshi系统需求时,后台题库系统提供录入题目的功能。在录入题目的时候,由于题目来源广泛,且参与录入题目的人有多位,因此容易出现录入重复题目的情况。所以需要实现语句相似度分析功能,从而筛选出重复的题目并人工处理之。 下面介绍如何使用 Java 实现上述想法,完成语句相似度分析: 1 、使用 HanLP 完成分词: 首先,添加 HanLP 的依赖:( jsoup 是为了处理题干中的 ht
Java利用hanlp完成语句相似度分析的方法详解
在做kaoshi系统需求时,后台题库系统提供录入题目的功能。在录入题目的时候,由于题目来源广泛,且参与录入题目的人有多位,因此容易出现录入重复题目的情况。所以需要实现语句相似度分析功能,从而筛选出重复的题目并人工处理之。 下面介绍如何使用 Java 实现上述想法,完成语句相似度分析: 1 、使用 HanLP 完成分词: 首先,添加 HanLP 的依赖:( jsoup 是为了处理题干中的 ht

作为一名程序员,到现在你还不知道HanLP.com吗?
作为一名程序员,到现在你还不知道HanLP.com吗? 现如今,NLP已经越来越渗透进人们的生活,从事NLP行业的人们也越来越多,所以市场上的NLP软件规模逐渐庞大,技术也逐渐成熟。 NLTK,“Natural Language Toolkit”。由宾夕法尼亚大学研发。 CoreNLP,由斯坦福大学研发。 LTP,由哈尔滨工业大学研发。

FoolNLTK 及 HanLP使用
个人接触的分词器 安装 调用 jieba“结巴”中文分词:做最好的 Python 中文分词组件https://github.com/fxsjy/jieba 清华大学THULAC:一个高效的中文词法分析工具包 https://github.com/thunlp/THULAC-Python FoolNLTK可能不是最快的开源中文分词,但很可能是最准的开源中文分词 https://gith
中文分词工具比较 6大中文分词器测试(哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba、FoolNLTK、HanLP)
中文分词工具比较 6大中文分词器测试(jieba、FoolNLTK、HanLP、THULAC、nlpir、ltp) 哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba 个人接触的分词器 安装 调用 jieba“结巴”中文分词:做最好的 Python 中文分词组件https://github.com/fxsjy/jieba THULAC清华大学:一个高效的中文词法分析工具包
Linux系统运行HanLP时候 TypeError: startJVM() got an unexpected keyword argument ‘convertStrings‘
在Linux下安装hanlp的时候,万事具备却遇到了TypeError: startJVM() got an unexpected keyword argument 'convertStrings’这样的问题 解决方法:找到 启动JVM的代码块做出如下修改 我的代码块是在 speech/lib/python3.6/sit-packages/pyhanlp 下的__init__.py 文件,spee

Python 实战 | 进阶中文分词之 HanLP 词典分词(上)
更多内容点击查看Python 实战 | 进阶中文分词之 HanLP 词典分词(上) Python教学专栏,旨在为初学者提供系统、全面的Python编程学习体验。通过逐步讲解Python基础语言和编程逻辑,结合实操案例,让小白也能轻松搞懂Python! >>>点击此处查看往期Python教学内容 本文目录 一、引言 二、加载 HanLP 词典 三、切分规则 四、实现 HanLP 词典
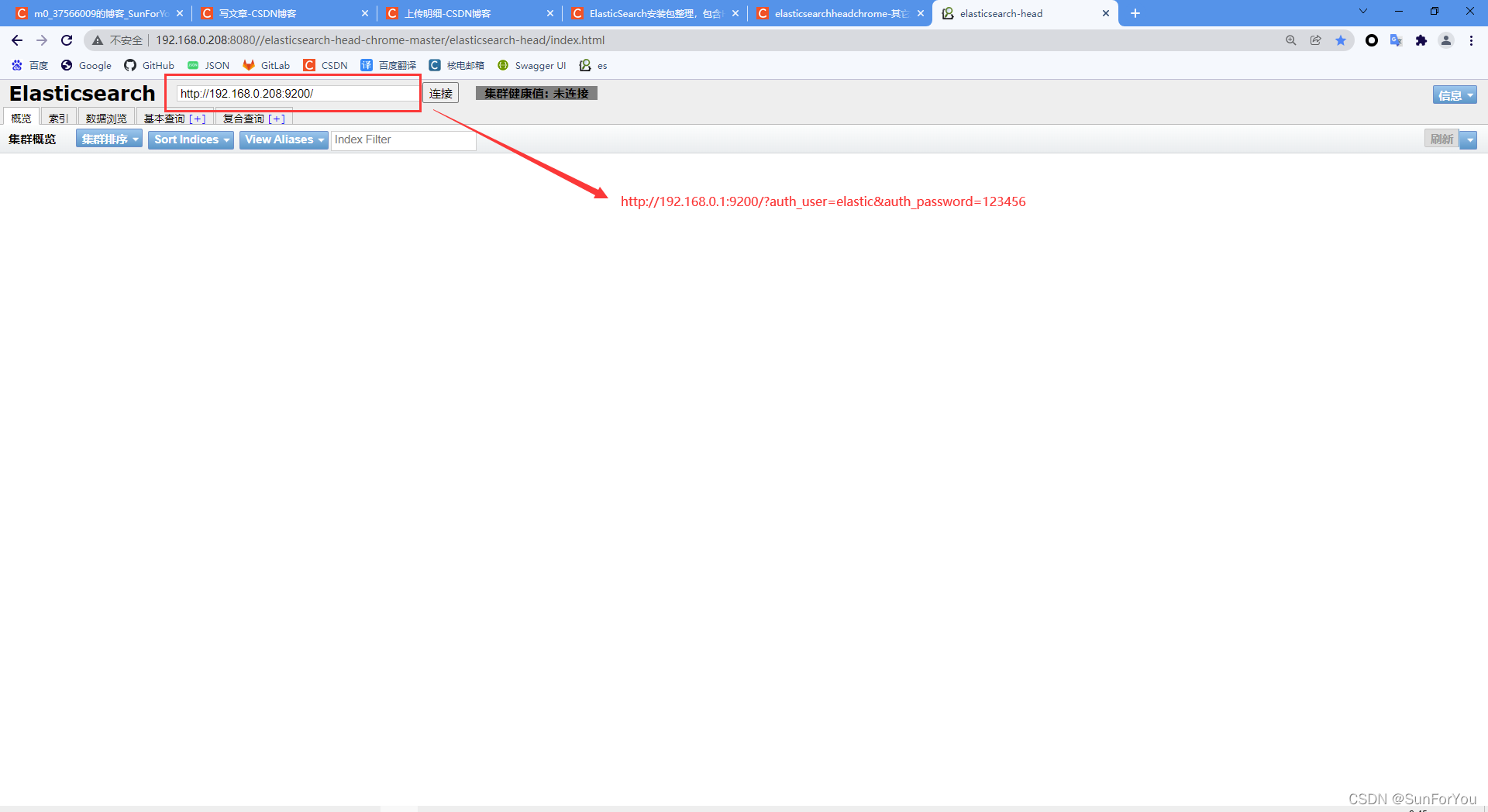
ElasticSearch 集群 7.9.0 linux (CentOS 7部署)包含Mysql动态加载同义词、基础词、停用词,Hanlp分词器,ik分词器,x-pack)
linux服务器配置要求: /etc/sysctl.conf文件最后添加一行 vm.max_map_count=262144 /sbin/sysctl -p 验证是否生效 修改文件/etc/security/limits.conf,最后添加以下内容。 * soft nofile 65536* hard nofile 65536* soft nproc 32000* hard npr
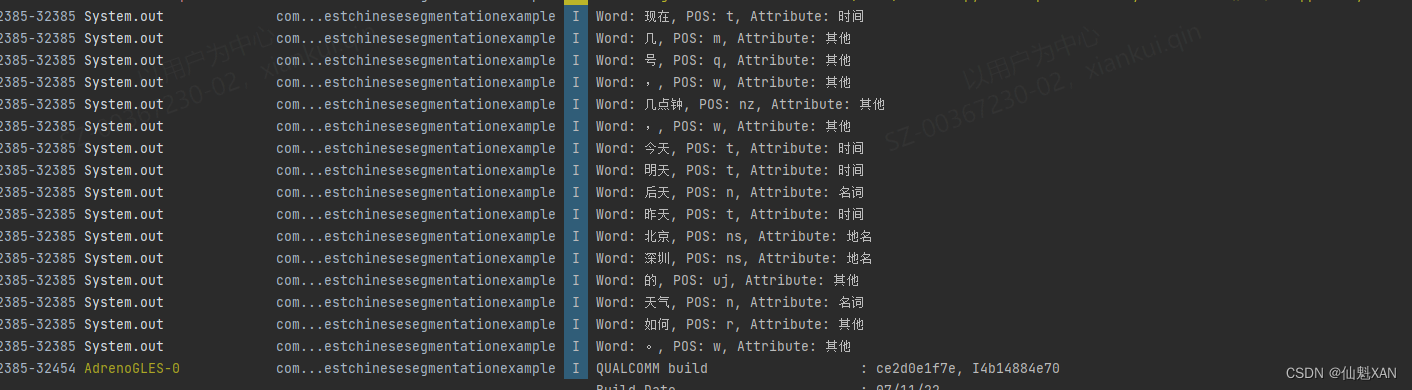
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理 目录 Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理 一、简单介绍 二、实现原理 三、注意事项 四、效果预览 五、实现步骤 六、关键代码 附录:在 HanLP 中,Term 对象
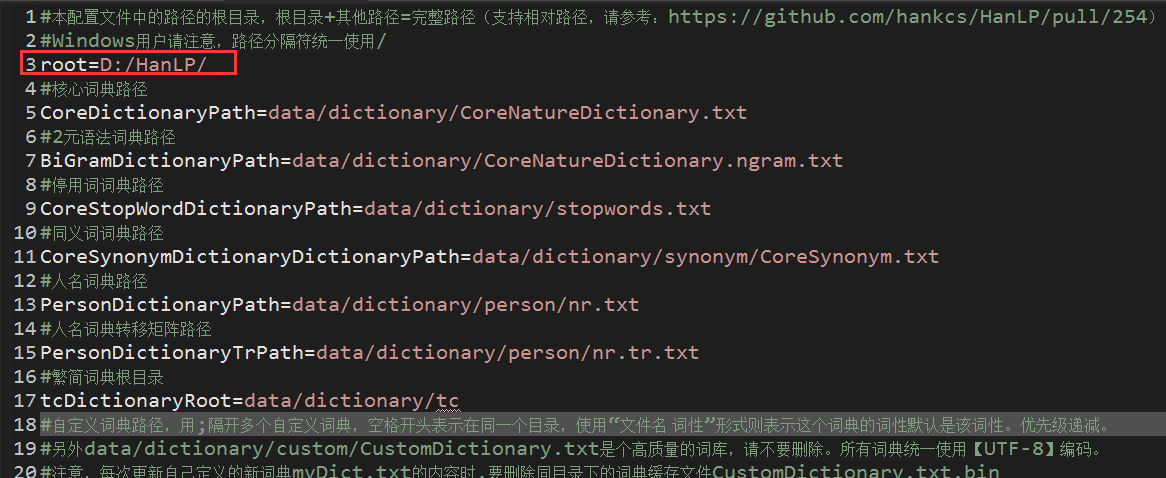
基于电影知识图谱的智能问答系统(四) --HanLP分词器
上一篇:基于电影知识图谱的智能问答系统(三) -- Spark环境搭建 一、什么是分词器? 分词器,是将用户输入的一段文本,分析成符合逻辑的一种工具。到目前为止呢,分词器没有办法做到完全的符合人们的要求。和我们有关的分词器有英文的和中文的分词器:输入文本-关键词切分-去停用词-形态还原-转为小写中文的分词器分为: 单子分词 例:中国人 分成中,国,人 二分法人词

基于HanLP分词的命名实体提取
文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。对于文本来说,由于语言组织形式各异,表达方式多样,文本里面提到的很多要素,如人名、手机号、组织名、地名等都称之为实体。在工程领域,招投标文件里的这些实体信息至关重要。利用自然语言处理技术从形式各异的文件中提取出这些实体,能有效提高工作效率和挖掘实体之间的潜在联系。 文本预处理 1、文本

hanlp源码解析word2vec词向量算法
欢迎关注鄙人公众号,技术干货随时看! one-hot表示法 词向量就是把一个词用向量的形式表示,以前的经典表示法是one-hot,这种表示法向量的维度是词汇量的大小。它的处理方式简单粗暴,一般就是统计词库包含的所有V个词,然后将这V个词固定好顺序,然后每个词就可以用一个V维的稀疏向量来表示,向量中只有在该词出现的位置的元素才为1,其它元素全为0。比如下面这几个词,第一个元素为1的表示中国,第

HanLP Java 配置和初步使用
HanLP Java IDEA配置和初步使用 HanLP介绍HanLP安装(Java)方式一:Maven仓库方式二:自行下载jar、data、hanlp.properties。 HanLP初步使用NLP分词初体验 HanLP介绍 HanLP是一款面向生产环境的自然语言处理工具包。 具有的功能如下: 中文分词 词性标注 命名实体识别 依存句法分析 语义依存分析 新词发现 关键词短

自然语言处理hanlp------9基于双数组字典树的AC自动机
文章目录 前言一、原理二、实现测试总结 前言 双数组字典树能在O( l l l)的时间内高速完成单串匹配,并且消耗的内存可控,软肋在于多模式匹配。如果要匹配多个模式串,必须先前缀查询,然后频繁截取文本的后缀才行。但是上一节测评的AC多模式匹配又还不如双数组字典树快,所以,本节就采用二者结合。称为AhoCorasickDoubleArrayTire(简称ACDAT) 一、