本文主要是介绍Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
目录
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
一、简单介绍
二、实现原理
三、注意事项
四、效果预览
五、实现步骤
六、关键代码
附录:在 HanLP 中,Term 对象的 nature 字段表示词性
一、简单介绍
Android 开发中的一些基础操作,使用整理,便于后期使用。
本节介绍,在Android中, 使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理。
在 Android 平台上,除了 HanLP,还有其他一些可以用于中文分词处理的算法和工具。以下是一些常见的中文分词算法,以及 HanLP 在分词中的一些优势:
常见的中文分词算法和工具:
ansj_seg: ansj_seg 是一个基于 CRF 和 HMM 模型的中文分词工具,适用于 Java 平台。它支持细粒度和粗粒度的分词,并具有一定的自定义词典和词性标注功能。
jieba: jieba 是一个在 Python 中广泛使用的中文分词库,但也有其 Java 版本。它采用了基于前缀词典的分词方法,并在速度和效果方面表现出色。
lucene-analyzers-smartcn: 这是 Apache Lucene 项目中的一个中文分词器,使用了基于规则的分词算法。它在 Lucene 搜索引擎中被广泛使用。
ictclas4j: ictclas4j 是一个中科院计算所开发的中文分词工具,基于 HMM 模型。它支持自定义词典和词性标注。
HanLP 分词的优势:
多领域适用性: HanLP 被设计为一个面向多领域的中文自然语言处理工具包,不仅包括分词,还支持词性标注、命名实体识别、依存句法分析等多种任务。
性能和效果: HanLP 在多个标准数据集上进行了训练和优化,具有较好的分词效果和性能。
灵活的词典支持: HanLP 支持自定义词典,你可以根据需要添加专业领域的词汇,以提升分词效果。
开放源代码: HanLP 是开源的,你可以自由使用、修改和分发,有利于定制和集成到你的项目中。
多语言支持: HanLP 不仅支持中文,还支持其他语言,如英文、日文等,为跨语言处理提供了便利。
社区活跃: HanLP 拥有活跃的社区和维护团队,有助于解决问题和获取支持。
总之,HanLP 是一个功能丰富且性能优越的中文自然语言处理工具,适用于各种应用场景,特别是在多领域的文本处理任务中表现出色。然而,最终的选择取决于你的具体需求和项目背景。
HanLP 官网:HanLP | 在线演示
HanLP GitHub:GitHub - hankcs/HanLP: 中文分词 词性标注 命名实体识别 依存句法分析 成分句法分析 语义依存分析 语义角色标注 指代消解 风格转换 语义相似度 新词发现 关键词短语提取 自动摘要 文本分类聚类 拼音简繁转换 自然语言处理
二、实现原理
1、使用 StandardTokenizer.segment(text) 传入文本 Text 内容进行分词
2、使用 Term.word; 获取分词内容,Term.nature.toString() 获取分词的属性
三、注意事项
1、中文的词会有对应较为准确的此属性,英文可能没有
四、效果预览
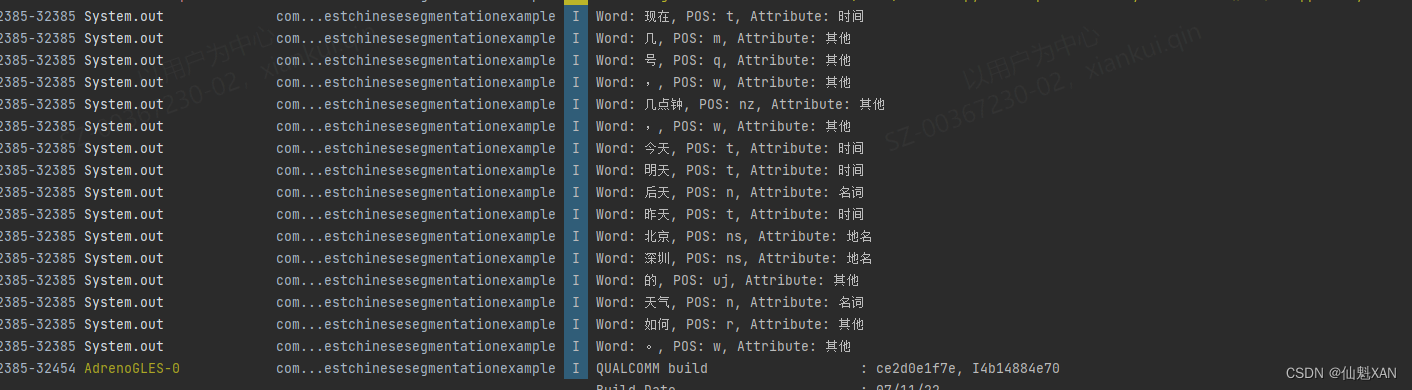
五、实现步骤
1、打开 Android Studio 创建一个空工程,在build.gradle 中引入 HanLP
implementation 'com.hankcs:hanlp:portable-1.7.5' 记得 Sync nNow

2、创建脚本 ChineseSegmentationExample ,实现分词功能
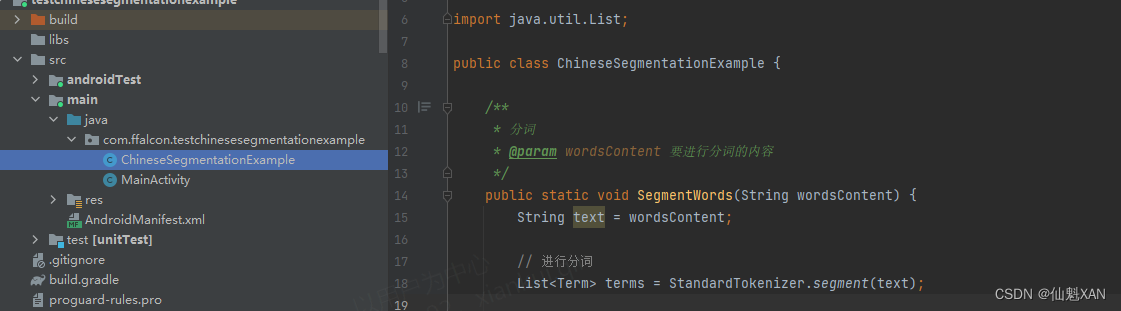
3、在 主脚本中调用,输入要分词的内容

4、打包在Android 机子上运行,效果如上
六、关键代码
1、ChineseSegmentationExample
package com.xxxx.testchinesesegmentationexample;import com.hankcs.hanlp.seg.common.Term;
import com.hankcs.hanlp.tokenizer.StandardTokenizer;import java.util.List;public class ChineseSegmentationExample {/*** 分词* @param wordsContent 要进行分词的内容*/public static void SegmentWords(String wordsContent) {String text = wordsContent;// 进行分词List<Term> terms = StandardTokenizer.segment(text);// 遍历分词结果,判断词性并打印for (Term term : terms) {String word = term.word;String pos = term.nature.toString();String posInfo = getPosInfo(pos); // 判断词性属性System.out.println("Word: " + word + ", POS: " + pos + ", Attribute: " + posInfo);}}/*** 判断词性属性* @param pos* @return 属性*/static String getPosInfo(String pos) {// 这里你可以根据需要添加更多的判断逻辑来确定词性属性if (pos.equals("n")) {return "名词";} else if (pos.equals("v")) {return "动词";} else if (pos.equals("ns")) {return "地名";}else if (pos.equals("t")) {return "时间";}else {return "其他";}}}
2、MainActivity
ackage com.xxxxx.testchinesesegmentationexample;import androidx.appcompat.app.AppCompatActivity;import android.os.Bundle;public class MainActivity extends AppCompatActivity {@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_main);ChineseSegmentationExample.SegmentWords("现在几号,几点钟,今天明天后天昨天北京深圳的天气如何。");}
}附录:在 HanLP 中,Term 对象的 nature 字段表示词性
在 HanLP 中,
Term对象的nature字段表示词性(Part of Speech,POS)。HanLP 使用了一套标准的中文词性标注体系,每个词性都有一个唯一的标识符。以下是一些常见的中文词性标注及其含义:
名词类:
n:普通名词nr:人名ns:地名nt:机构名nz:其他专名nl:名词性惯用语ng:名词性语素时间类:
t:时间词动词类:
v:动词vd:副动词vn:名动词vshi:动词"是"vyou:动词"有"形容词类:
a:形容词ad:副形词副词类:
d:副词代词类:
r:代词rr:人称代词rz:指示代词rzt:时间指示代词连词类:
c:连词助词类:
u:助词数词类:
m:数词量词类:
q:量词语气词类:
y:语气词叹词类:
e:叹词拟声词类:
o:拟声词方位词类:
f:方位词状态词类:
z:状态词介词类:
p:介词前缀类:
h:前缀后缀类:
k:后缀标点符号类:
w:标点符号请注意,上述只是一些常见的词性标注及其含义,实际情况可能更复杂。你可以根据需要调查 HanLP 的文档来了解更多词性标注的详细信息。根据这些词性标注,你可以编写代码来判断词的属性(如动词、名词、地名等)并进行相应的处理。
这篇关于Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




