本文主要是介绍hanlp中文分词器(ing...),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目前的工作中需要对文本进行分词分析词性,找出热词,经过一系列的调研感觉hanlp这个库还不错,想先试用看看
介绍
HanLP(Han Language Processing)是一个由一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。HanLP分词器是其中的一个重要组件,用于将连续的中文文本切分成一个个有意义的词语。python和java它都支持, 现在要是用的是java版本的
安装依赖
<dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><version>portable-1.8.4</version></dependency>使用
这是一个最简单的例子,它运行完之后自动分词并标注出词性
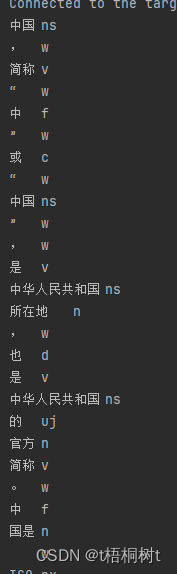
public static void main(String[] args) {String text = "中国,简称“中”或“中国”,是中华人民共和国所在地,也是中华人民共和国的官方简称。" +"中国是 ISO 3166-1-alpha-2 国家代码中的“CN”,是 ISO 3166-1-alpha-3 国家代码中的“CHN”," +"是 ISO 3166-1-numeric 国家代码中的“156”。" +"中国是 ISO 3166-2 国家子领域代码中的“CN-”开头的子领域代码。";// 创建分词器实例Segment segment = HanLP.newSegment().enableCustomDictionary(false);// 对文本进行分词和词性标注for (Term term : segment.seg(text)) {System.out.println(term.word + "\t" + term.nature);}}可以看一下,默认情况下它分出来的词还是比较粗糙的
Segment这个类中还是有很多自定义的配置项的目前来说由于时间有限还没有深入去了解自定义配置以后会是什么效果,在后续搞清楚后再继续更新
ing...
这篇关于hanlp中文分词器(ing...)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






