fasternet专题

YOLOv8主干网络使用FasterNet替换
1 提出问题 减少GFLOPs就一定能提高模型的运行速度吗?一般人认为这个是理由应当的。但是在FasterNet文章中,作者告诉我们:不一定! 延迟与浮点数运算的关系如下: Latency=FLOPs÷FLOPS FLOPs:模型浮点数运算 FLOPS:每秒浮点数运算 这个你们在实验中可以得到验证,MobileNetV3主干网络替换之后,参数量下降很多,FLOPs也下降很多,但是在GPU平台上
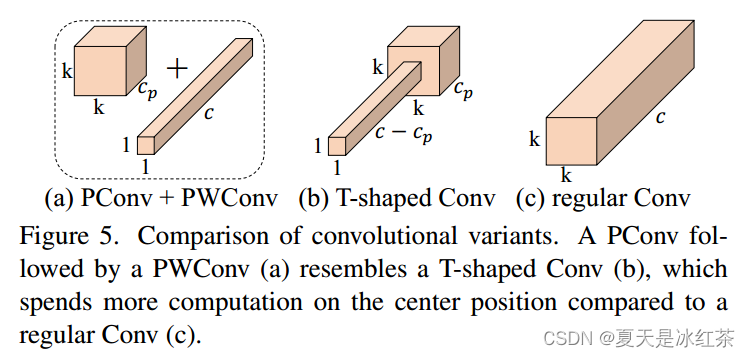
部分卷积与FasterNet模型详解
简介 论文原址:2023CVPR:https://arxiv.org/pdf/2303.03667.pdf 代码仓库:GitHub - JierunChen/FasterNet: [CVPR 2023] Code for PConv and FasterNet 为了设计快速神经网络,很多工作都集中于减少浮点运算(FLOPs)的数量上面,但是作者发现FLOPs的减少不一定会带来延迟的类似程度的
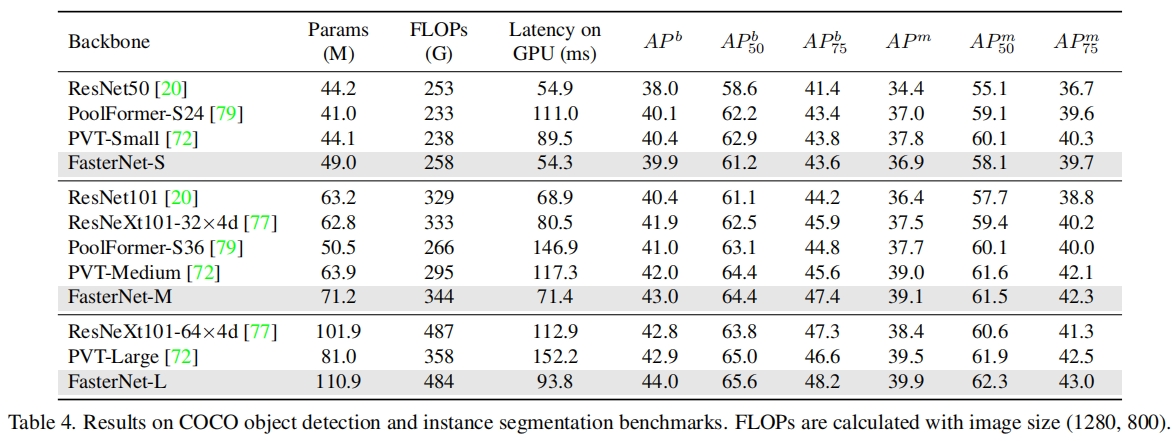
FasterNet(CVPR 2023)论文解读
paper:Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks official implementation:https://github.com/jierunchen/fasternet 存在的问题 为了设计轻量、速度快的网络,许多工作都专注于减少floating-point operations (FLOPs

YOLOv8改进 | 2023主干篇 | FasterNeT跑起来的主干网络( 提高FPS和检测效率)
一、本文介绍 本文给大家带来的改进机制是FasterNet网络,将其用来替换我们的特征提取网络,其旨在提高计算速度而不牺牲准确性,特别是在视觉任务中。它通过一种称为部分卷积(PConv)的新技术来减少冗余计算和内存访问。这种方法使得FasterNet在多种设备上运行速度比其他网络快得多,同时在各种视觉任务中保持高准确率。经过我的实验该主干网络确实能够涨点在大中小三种物体检测上,同时该主干网络也提

论文笔记——FasterNet
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。 为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由于运算符的频繁内存访问,尤其是深度卷积。因此,本文提出了一种新的partial convolution(PCon
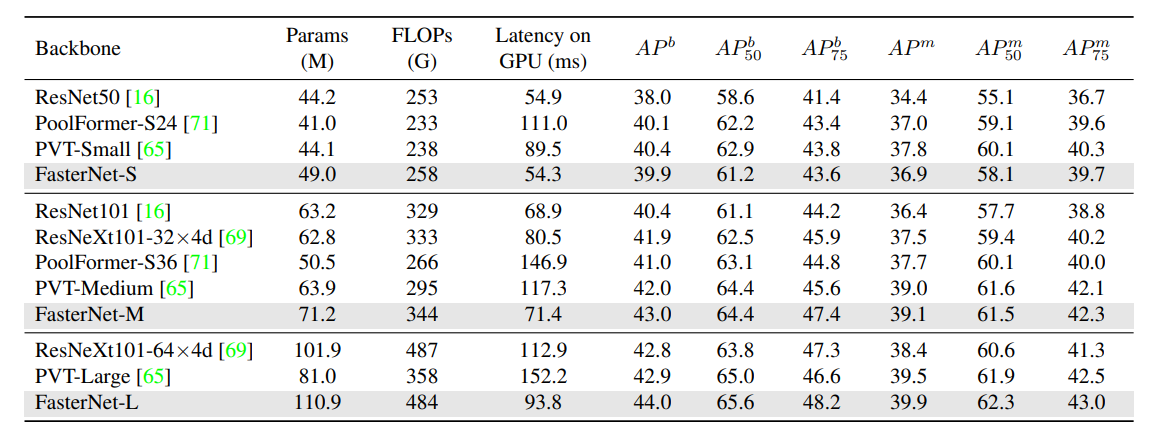
CVPR 2023 | 主干网络FasterNet 核心解读 代码分析
本文分享来自CVPR 2023的论文,提出了一种快速的主干网络,名为FasterNet。 论文提出了一种新的卷积算子,partial convolution,部分卷积(PConv),通过减少冗余计算和内存访问来更有效地提取空间特征。 创新在于部分卷积(PConv),它选择一部分通道的特性进行常规卷积,剩余部分通道的特性保持不变,降低了计算复杂度,从而实现了快速高效的神经网络。 区别于常规卷积
![[卷积神经网络]FasterNet论文解析](https://img-blog.csdnimg.cn/e863039408944f26b0fe8b475aa612a2.png)
[卷积神经网络]FasterNet论文解析
一、概述 FasterNet是CVPR2023的文章,通过使用全新的部分卷积PConv,更高效的提取空间信息,同时削减冗余计算和内存访问,效果非常明显。相较于DWConv,PConv的速度更快且精度也非常高,识别精度基本等同于大型网络Swin-B,但是在GPU上可以提升36%的吞吐量。原文地址和代码地址如下: Run, Don't Walk: Chasing Higher FL
[卷积神经网络]FasterNet论文解析
一、概述 FasterNet是CVPR2023的文章,通过使用全新的部分卷积PConv,更高效的提取空间信息,同时削减冗余计算和内存访问,效果非常明显。相较于DWConv,PConv的速度更快且精度也非常高,识别精度基本等同于大型网络Swin-B,但是在GPU上可以提升36%的吞吐量。原文地址和代码地址如下: Run, Don't Walk: Chasing Higher FL