本文主要是介绍CVPR 2023 | 主干网络FasterNet 核心解读 代码分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文分享来自CVPR 2023的论文,提出了一种快速的主干网络,名为FasterNet。
论文提出了一种新的卷积算子,partial convolution,部分卷积(PConv),通过减少冗余计算和内存访问来更有效地提取空间特征。
创新在于部分卷积(PConv),它选择一部分通道的特性进行常规卷积,剩余部分通道的特性保持不变,降低了计算复杂度,从而实现了快速高效的神经网络。
区别于常规卷积:PConv只对输入通道的一部分应用卷积,而保留其余部分不变。
论文地址:Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
代码地址:https://github.com/JierunChen/FasterNet/tree/master
目录
一、PConv算子设计原理
二、PConv算子的代码解析
三、FasterNet模型原理
四、FasterNet模型测试
五、实验分析
背景:
- MobileNet、ShuffleNet和GhostNet等利用深度卷积(DWConv)或 组卷积(GConv)来提取空间特征。
- 然而,在减少FLOPs的过程中,算子经常会受到内存访问增加的副作用的影响。
- MicroNet进一步分解和稀疏网络,将其FLOPs推至极低水平。尽管这种方法在FLOPs方面有所改进,但其碎片计算效率很低。
- 上述网络通常伴随着额外的数据操作,如级联、Shuffle和池化,这些操作的运行时间对于小型模型来说往往很重要。
一、PConv算子设计原理
1、这种部分卷积的核心思想是对输入特征图的部分通道应用卷积操作,而保留其他通道不变。这种操作可以有效地减少计算冗余,提高计算效率。

对于连续或规则的内存访问,将第一个或最后一个连续的通道视为整个特征图的代表进行计算。
在不丧失一般性的情况下认为输入和输出特征图具有相同数量的通道。
设计原因
通过利用特征图的冗余度可以进一步优化成本。
如下图所示,特征图在不同通道之间具有高度相似性。许多其他著作也涵盖了这种冗余,但很少有人以简单而有效的方式充分利用它。

于是出了PConv,对输入特征图的部分通道应用卷积操作,而保留其他通道不变,同时减少计算冗余和内存访问。
2、为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到PConv。
它们在输入特征图上的有效感受野看起来像一个T形Conv,与均匀处理补丁的常规Conv相比,它更专注于中心位置。
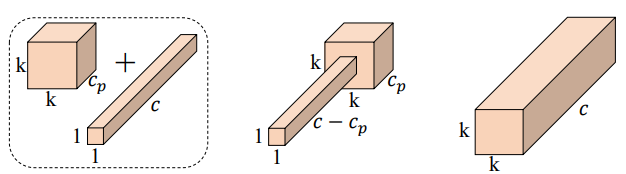
通过实验表明:中心位置是卷积操作中最常见的突出位置,即中心位置的权重比周围的更重。这与集中于中心位置的T形计算一致。
虽然T形卷积可以直接用于高效计算,但作者表明,将T形卷积分解为PConv和PWConv更好,因为该分解利用了卷积操作间冗余并进一步节省了FLOPs。
二、PConv算子的代码解析
PConv算子的代码:
'''
输入三个参数:dim(输入特征图的通道数),n_div(分割的组数)和forward(前向传播的方法)
输出:卷积后的特征图
'''
class Partial_conv3(nn.Module):def __init__(self, dim, n_div, forward):super().__init__()self.dim_conv3 = dim // n_div # 计算出卷积部分的通道数self.dim_untouched = dim - self.dim_conv3 # 计算出不需要卷积部分的通道数# 定义一个3*3卷积,输入通道数为self.dim_conv3,输出通道数也为self.dim_conv3,步长为1,填充为1,且不使用bias。self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedError# 只适合推理def forward_slicing(self, x: Tensor) -> Tensor:# 对输入x进行深拷贝,以保持原始输入的完整性。后面的操作不会改变原始输入x。x = x.clone() # 对输入x中前self.dim_conv3个通道应用卷积操作,并将结果保存回x中对应的位置。x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return x# 适合训练/推理def forward_split_cat(self, x: Tensor) -> Tensor:# 使用torch.split函数将输入x沿着通道维度(即第1维,索引从0开始)分割成两个部分,# 分别为x1和x2。分割的长度为[self.dim_conv3, self.dim_untouched],# 即分割后的x1的通道数为self.dim_conv3,x2的通道数为self.dim_untouched。x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return x
这段代码定义了一个名为 Partial_conv3 的 PyTorch 模块,它是nn.Module的子类。这个模块主要实现了一种部分卷积(Partial Convolution);
这种部分卷积的核心思想是对输入特征图的部分通道应用卷积操作,而保留其他通道不变。这种操作可以有效地减少计算冗余,提高计算效率。
方式1:slicing
# 只适合推理def forward_slicing(self, x: Tensor) -> Tensor:# 对输入x进行深拷贝,以保持原始输入的完整性。后面的操作不会改变原始输入x。x = x.clone() # 对输入x中前self.dim_conv3个通道应用卷积操作,并将结果保存回x中对应的位置。x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return x方式2:split_cat
# 适合训练/推理def forward_split_cat(self, x: Tensor) -> Tensor:# 使用torch.split函数将输入x沿着通道维度(即第1维,索引从0开始)分割成两个部分,# 分别为x1和x2。分割的长度为[self.dim_conv3, self.dim_untouched],# 即分割后的x1的通道数为self.dim_conv3,x2的通道数为self.dim_untouched。x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return x三、FasterNet模型原理
基于部分卷积算子PConv和逐点卷积PWConv,作为主要的算子,进一步提出FasterNet。
这是一个新的神经网络家族,运行速度非常快,对许多视觉任务有效。模型架构如下:
它有4个层次级,每个层次级前面都有一个嵌入层(步长为4的常规4×4卷积)或一个合并层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。每个阶段都有一堆FasterNet块。
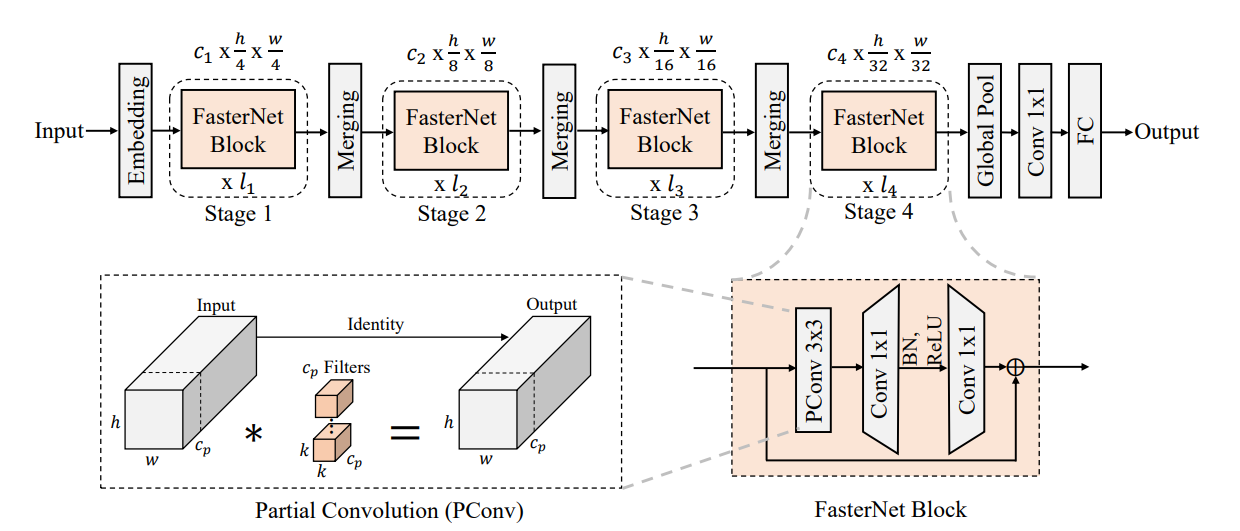
每个FasterNet块有一个PConv层,后跟2个PWConv(或Conv 1×1)层。它们一起显示为倒置残差块,其中中间层具有扩展的通道数量,并且放置了Shorcut以重用输入特征。
最后两个阶段中的块消耗更少的内存访问,并且倾向于具有更高的FLOPS,因此,放置了更多FasterNet块,并相应地将更多计算分配给最后两个阶段。
补充一下标准化和激活层:
标准化和激活层对于高性能神经网络也是不可或缺的。
然而,许多先前的工作在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能。它还可以降低整体计算速度。
相比之下,只将它们放在每个中间PWConv之后,以保持特征多样性并实现较低的延迟。
四、FasterNet模型测试
使用默认的参数构建FasterNet
mlp_ratio=2.0,
embed_dim=96,
depths=(1, 2, 8, 2),
drop_path_rate=0.10,
看一下的模型参数 :
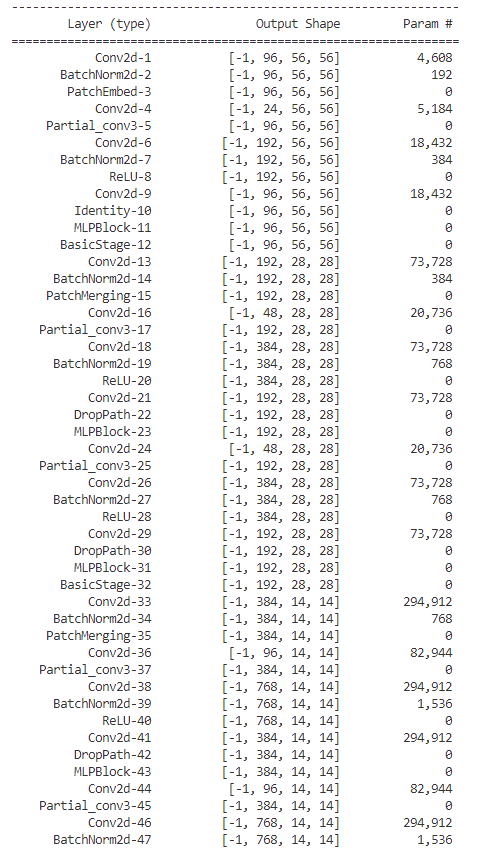
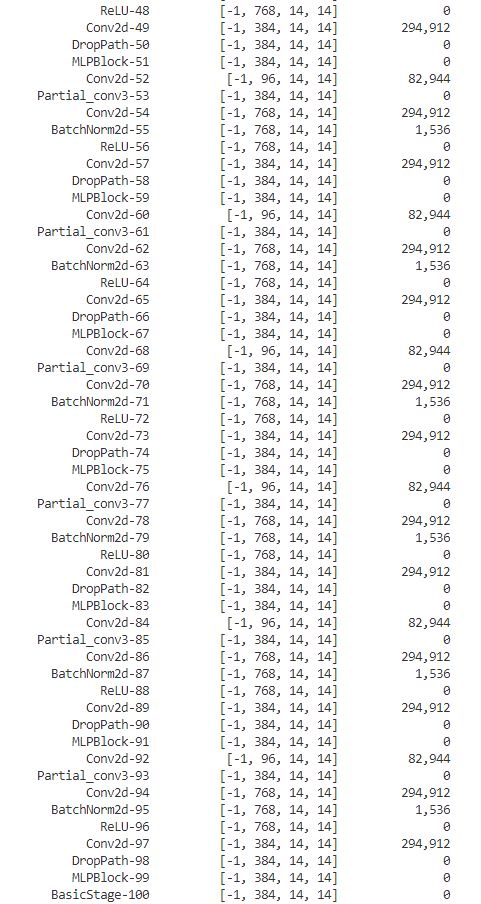
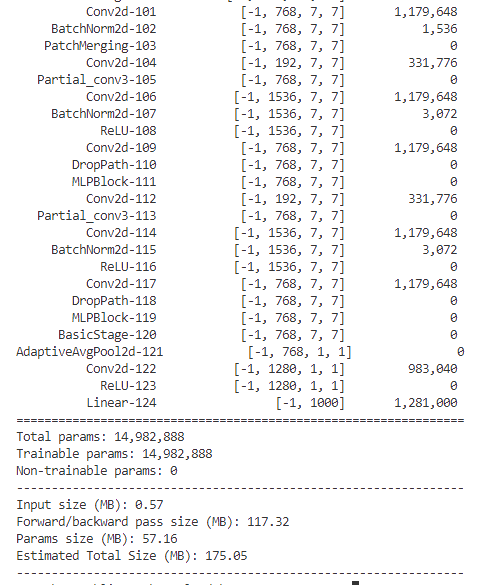
感觉模型也不小的。。。。。。。
测试代码分享给大家(代码存放路径:models/model_summary.py)
import torch.nn as nn
from fasternet import FasterNet
from torchsummary import summary# 默认参数
def fasternet(**kwargs):model = FasterNet(**kwargs)return model# S
def fasternet_s(**kwargs):model = FasterNet(mlp_ratio=2.0,embed_dim=128,depths=(1, 2, 13, 2),drop_path_rate=0.15,act_layer='RELU',fork_feat=True,**kwargs)return model# M
def fasternet_m(**kwargs):model = FasterNet(mlp_ratio=2.0,embed_dim=144,depths=(3, 4, 18, 3),drop_path_rate=0.2,act_layer='RELU',fork_feat=True,**kwargs)return model# L
def fasternet_l(**kwargs):model = FasterNet(mlp_ratio=2.0,embed_dim=192,depths=(3, 4, 18, 3),drop_path_rate=0.3,act_layer='RELU',fork_feat=True,**kwargs)return modelprint("fasternet:", fasternet)
model = fasternet()
summary(model, input_size=(3, 224, 224))print("fasternet_s:", fasternet_s)
model = fasternet_s()
summary(model, input_size=(3, 224, 224))print("fasternet_m:", fasternet_m)
model = fasternet_m()
summary(model, input_size=(3, 224, 224))print("fasternet_l:", fasternet_l)
model = fasternet_l()
summary(model, input_size=(3, 224, 224))
github有各个版本的预训练模型,大家可以测试一下。
| name | resolution | acc | #params | FLOPs | model |
|---|---|---|---|---|---|
| FasterNet-T0 | 224x224 | 71.9 | 3.9M | 0.34G | model |
| FasterNet-T1 | 224x224 | 76.2 | 7.6M | 0.85G | model |
| FasterNet-T2 | 224x224 | 78.9 | 15.0M | 1.90G | model |
| FasterNet-S | 224x224 | 81.3 | 31.1M | 4.55G | model |
| FasterNet-M | 224x224 | 83.0 | 53.5M | 8.72G | model |
| FasterNet-L | 224x224 | 83.5 | 93.4M | 15.49G | model |
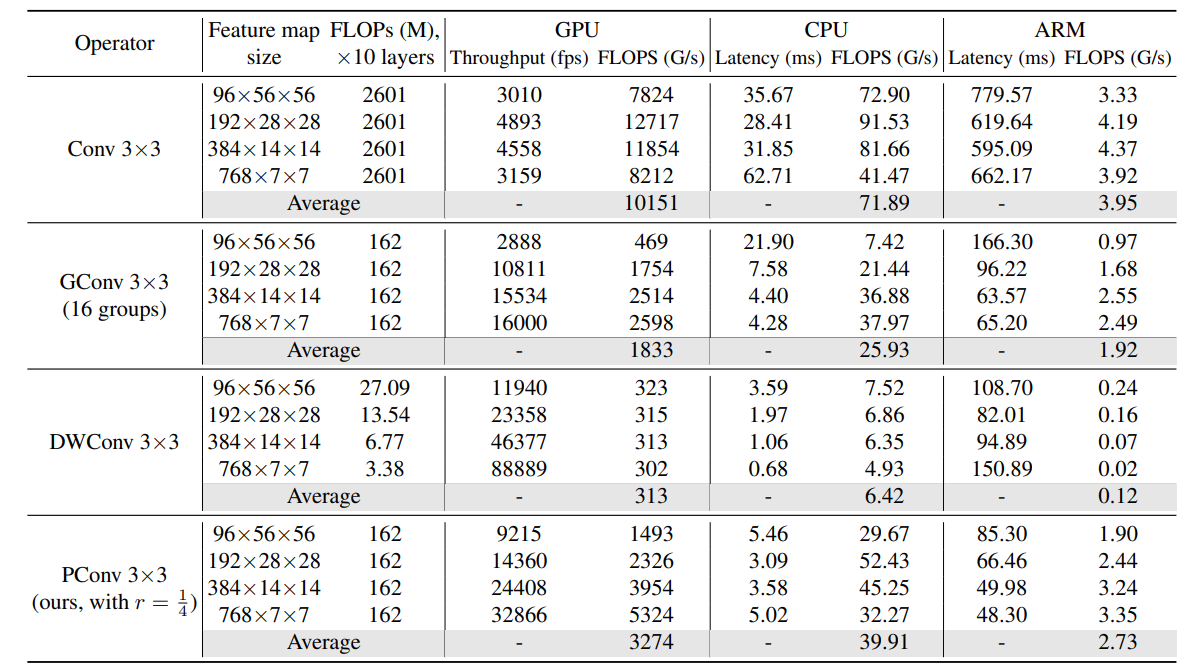
官方给的数据:
五、实验分析
FasterNet在不同设备(CPU、GPU、ARM),精度-吞吐量和精度-延迟权衡方面具有最高的效率。

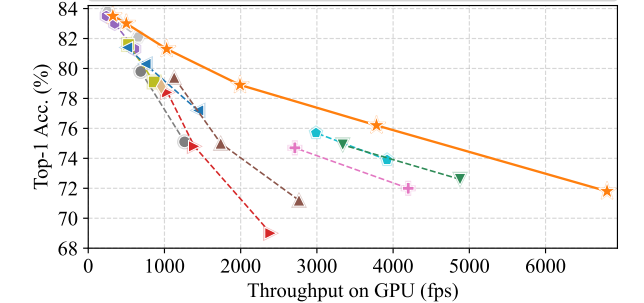

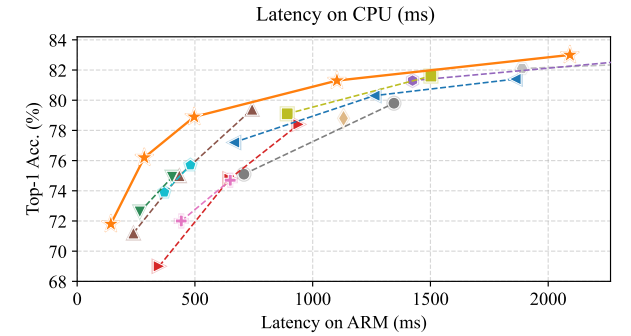
图像分类中,比较ImageNet-1k基准。具有类似TOP-1精度的模型被组合在一起。除MobileViT和EdgeNeXt的分辨率为256×256外,所有型号的分辨率均为224×224。OOM是内存不足的缩写。


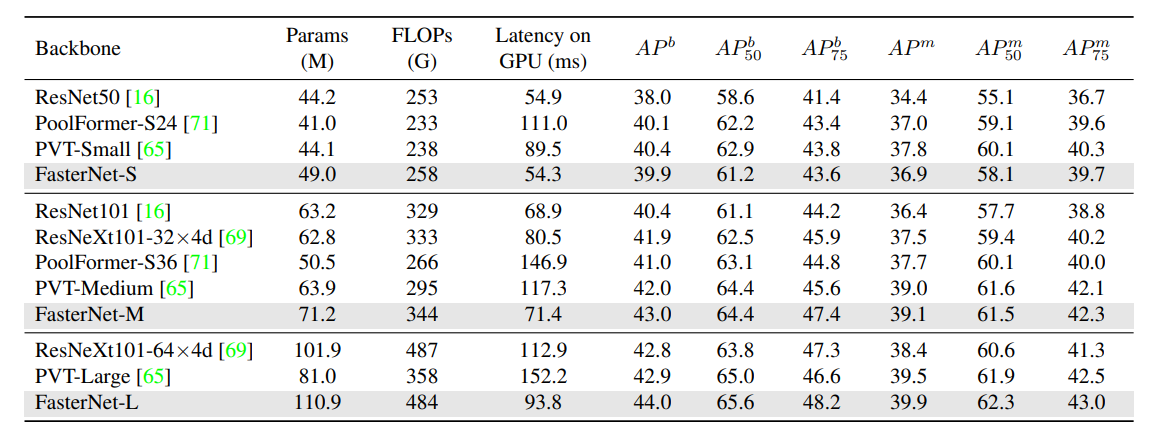
关于COCO目标检测和实例分割基准的结果,Flop是根据图像大小(1280,800)计算的。
分享完成~
这篇关于CVPR 2023 | 主干网络FasterNet 核心解读 代码分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






