本文主要是介绍[卷积神经网络]FasterNet论文解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概述
FasterNet是CVPR2023的文章,通过使用全新的部分卷积PConv,更高效的提取空间信息,同时削减冗余计算和内存访问,效果非常明显。相较于DWConv,PConv的速度更快且精度也非常高,识别精度基本等同于大型网络Swin-B,但是在GPU上可以提升36%的吞吐量。原文地址和代码地址如下:
Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks![]() https://arxiv.org/abs/2303.03667FasterNet
https://arxiv.org/abs/2303.03667FasterNet![]() https://github.com/JierunChen/FasterNet
https://github.com/JierunChen/FasterNet
二、基本结构
1.PConv
FasterNet的核心是PConv(Partial Conv),PConv有比常规Conv更低的FLOPs和比DWConv和GConv更高的FLOPs,能更好的利用设备的计算能力。

整个FasterNet的网络结构如上图所示。PConv的工作原理是:仅将输入特征图的一部分通道用于特征提取,其他的通道保持不变(即到
通道),使用部分的通道数为
。可以认为输入特征图和输出特征图具有相同的通道。而PConv的FLOPS可以表示为:
其中和
一起组成分离比:
,在
时,PConv仅有Conv
的FLOPS,同时PConv还有更小的内存访问量:
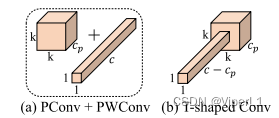
2.T型Conv
通过将逐点卷积(PWConv)附加到PConv上,使得输入特征图上的有效感受野看起来像一个T型的Conv,这种卷积会更加关注中心位置。
3.作为通用骨干网络
使用PConv搭建的FasterNet如上面所示,其能以较快的速度处理多种视觉任务。FasterNet具备4个Stage,每个Stage之前有一个嵌入层(Embedding;步长为4的4x4 Conv)或一个合并层(Mereging;步长为2的2x2 Conv),使用哪种间隔与其是否需要下采样有关。
每一个Faster Block的后面跟着两个PWConv层,最后统一放置一个全局池化(Global Pool)和一个全连接层(FC)
三、结论
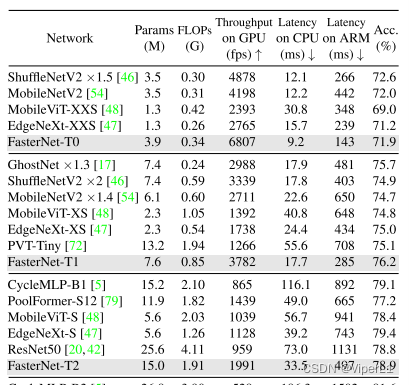
FasterNet的主要优势在于保证一定精度的同时提升运算速度。在对比实验中,FasterNet的参数量略大于MobileNet等轻型骨干网络,GFLOPS也略高于轻型骨干网络。但网络延迟却更低。
这篇关于[卷积神经网络]FasterNet论文解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





