本文主要是介绍部分卷积与FasterNet模型详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
论文原址:2023CVPR:https://arxiv.org/pdf/2303.03667.pdf
代码仓库:GitHub - JierunChen/FasterNet: [CVPR 2023] Code for PConv and FasterNet
为了设计快速神经网络,很多工作都集中于减少浮点运算(FLOPs)的数量上面,但是作者发现FLOPs的减少不一定会带来延迟的类似程度的减少。这源于每秒低浮点运算(FLOPs)的效率低下,而这源于FLOPs的运算符频繁访问内存,尤其是深度卷积,因此,提出了Partial Convolution,通过同时减少冗余计算和内存访问可以更有效地提取空间特征。并以此提出了FasterNet。
部分卷积
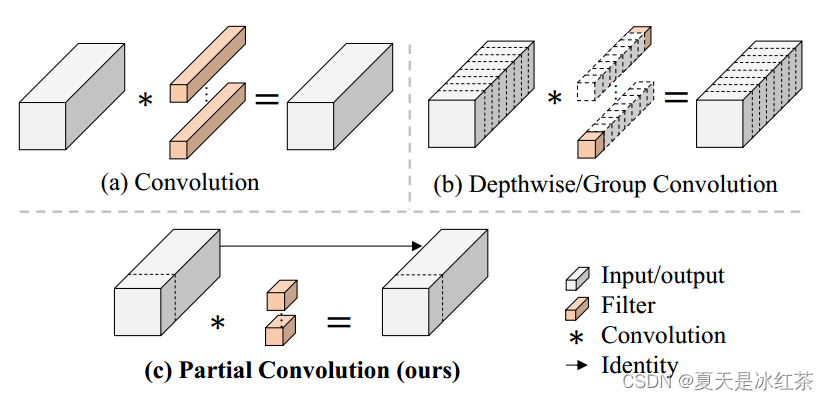
DWConv是Conv的一种流行变体,已被广泛用作许多神经网络的关键构建块,虽然DWConv(通常后跟逐点卷积或PWConv)可以有效地减少FLOPs,但不能简单地用于取代常规Conv,因为它会导致严重的精度下降。
在计算效率方面,PConv的FLOPs(浮点运算数)仅为常规卷积的一小部分,具体来说,当部分比例(partial ratio)为1/4时,FLOPs仅为常规卷积的1/16。内存访问量也显著减少,尤其在部分比例为1/4时,仅为常规卷积的1/4。
class PartialConv(nn.Module):def __init__(self, dim, n_div=4, kernel_size=3, forward='split_cat'):"""PartialConv 模块Args:dim (int): 输入张量的通道数。n_div (int): 分割通道数的分母,用于确定部分卷积的通道数。forward (str): 使用的前向传播方法,可选 'slicing' 或 'split_cat'。"""super().__init__()self.dim_conv3 = dim // n_divself.dim_untouched = dim - self.dim_conv3self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, kernel_size, 1, 1, bias=False)if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x):# only for inferencex = x.clone() # !!! Keep the original input intact for the residual connection laterx[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return xdef forward_split_cat(self, x):# for training/inferencex1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return x在代码当中设计了两种前向传播方式:
"forward_slicing" 主要用于推理阶段,在推理时,复制输入张量,然后仅在部分通道上进行卷积操作,保持其余通道不变。避免了对原始输入张量的修改,使得原始输入张量可以在后续的计算中被保留,如用于残差连接。
"forward_split_cat" 可用于训练和推理阶段, 在训练和推理时,该方法将输入张量分割成两部分,对第一部分进行卷积操作,然后将结果与原始未修改的第二部分拼接回来。对于训练过程,通过在部分通道上进行卷积,模型可以学到更适应当前任务的特征。同时,保留了原始未修改的通道,以用于后续的计算。
FasterNet作为Backbone

它分为四个阶段(Stage),每个阶段包含一系列的FasterNet块(FasterNet Block),并在每个阶段之前有一个嵌入(Embedding)或合并(Merging)层。最后的三个层用于特征分类。
在每个FasterNet块内部,采用了Partial Convolution (PConv) 操作,其后接两个Pointwise Convolution (PWConv) 操作。这一结构有效利用了所有通道的信息,形成一个T形的卷积结构,使得模型更加关注中心位置的特征。在PConv操作后,只在中间层之后加入归一化和激活层,以保持特征的多样性和降低计算延迟。
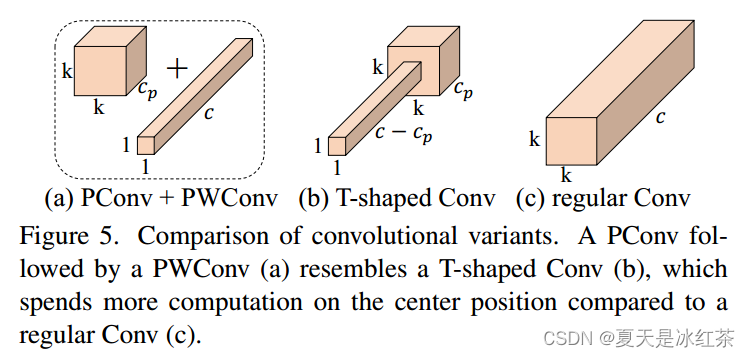
对于激活函数的选择,根据计算预算的大小,选择了GELU(对于较小的FasterNet变体)和ReLU(对于较大的FasterNet变体)。最后三层,即全局平均池化、Conv 1x1和全连接层,用于进行特征变换和分类。
为了满足不同的计算预算,提供了四个不同大小的FasterNet变体,分别为FasterNet-T0/1/2、FasterNet-S、FasterNet-M和FasterNet-L。这些变体在深度和宽度上略有差异,但整体架构相似。详细的架构规格可在附录中找到。
下面的网络复现是参考的原作者以及下面paddle版本的实现:
"""
Paper address: <https://arxiv.org/pdf/2303.03667.pdf>
Reference from: https://github.com/JierunChen/FasterNet/blob/master/models/fasternet.py
Blog records: https://blog.csdn.net/m0_62919535/article/details/136334105
"""
import torch
import torch.nn as nn
from pyzjr.Models.bricks import DropPath__all__=["FasterNet", "FasterNetBlock", "fasternet_t0", "fasternet_t1", "fasternet_t2","fasternet_s", "fasternet_m", "fasternet_l"]class PartialConv(nn.Module):def __init__(self, dim, n_div=4, kernel_size=3, forward='split_cat'):"""PartialConv 模块Args:dim (int): 输入张量的通道数。n_div (int): 分割通道数的分母,用于确定部分卷积的通道数。forward (str): 使用的前向传播方法,可选 'slicing' 或 'split_cat'。"""super().__init__()self.dim_conv3 = dim // n_divself.dim_untouched = dim - self.dim_conv3self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, kernel_size, 1, 1, bias=False)if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x):# only for inferencex = x.clone() # !!! Keep the original input intact for the residual connection laterx[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return xdef forward_split_cat(self, x):# for training/inferencex1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return xclass FasterNetBlock(nn.Module):def __init__(self, dim, expand_ratio=2, act_layer=nn.ReLU, drop_path_rate=0.0, forward='split_cat'):super().__init__()self.pconv = PartialConv(dim, forward=forward)self.conv1 = nn.Conv2d(dim, dim * expand_ratio, 1, bias=False)self.bn = nn.BatchNorm2d(dim * expand_ratio)self.act_layer = act_layer()self.conv2 = nn.Conv2d(dim * expand_ratio, dim, 1, bias=False)self.drop_path = DropPath(drop_path_rate) if drop_path_rate > 0.0 else nn.Identity()def forward(self, x):residual = xx = self.pconv(x)x = self.conv1(x)x = self.bn(x)x = self.act_layer(x)x = self.conv2(x)x = residual + self.drop_path(x)return xclass FasterNet(nn.Module):def __init__(self, in_channel=3, embed_dim=40, act_layer=None,num_classes=1000, depths=None, drop_rate=0.0):super().__init__()# Embeddingself.stem = nn.Sequential(nn.Conv2d(in_channel, embed_dim, 4, stride=4, bias=False),nn.BatchNorm2d(embed_dim),act_layer())drop_path_list = [x.item() for x in torch.linspace(0, drop_rate, sum(depths))]self.feature = []embed_dim = embed_dimfor idx, depth in enumerate(depths):self.feature.append(nn.Sequential(*[FasterNetBlock(embed_dim, act_layer=act_layer, drop_path_rate=drop_path_list[sum(depths[:idx]) + i]) for i in range(depth)]))if idx < len(depths) - 1:# Mergingself.feature.append(nn.Sequential(nn.Conv2d(embed_dim, embed_dim * 2, 2, stride=2, bias=False),nn.BatchNorm2d(embed_dim * 2),act_layer()))embed_dim = embed_dim * 2self.feature = nn.Sequential(*self.feature)self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv1 = nn.Conv2d(embed_dim, 1280, 1, bias=False)self.act_layer = act_layer()self.fc = nn.Linear(1280, num_classes)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.constant_(m.bias, 0)def forward(self, x):x = self.stem(x)x = self.feature(x)x = self.avg_pool(x)x = self.conv1(x)x = self.act_layer(x)x = self.fc(x.flatten(1))return xdef fasternet_t0(num_classes, drop_path_rate=0.0):return FasterNet(embed_dim=40,act_layer=nn.GELU,num_classes=num_classes,depths=[1, 2, 8, 2],drop_rate=drop_path_rate)def fasternet_t1(num_classes, drop_path_rate=0.02):return FasterNet(embed_dim=64,act_layer=nn.GELU,num_classes=num_classes,depths=[1, 2, 8, 2],drop_rate=drop_path_rate)def fasternet_t2(num_classes, drop_path_rate = 0.05):return FasterNet(embed_dim=96,act_layer=nn.ReLU,num_classes=num_classes,depths=[1, 2, 8, 2],drop_rate=drop_path_rate)def fasternet_s(num_classes, drop_path_rate = 0.03):return FasterNet(embed_dim=128,act_layer=nn.ReLU,num_classes=num_classes,depths=[1, 2, 13, 2],drop_rate=drop_path_rate)def fasternet_m(num_classes, drop_path_rate = 0.05):return FasterNet(embed_dim=144,act_layer=nn.ReLU,num_classes=num_classes,depths=[3, 4, 18, 3],drop_rate=drop_path_rate)def fasternet_l(num_classes, drop_path_rate = 0.05):return FasterNet(embed_dim=192,act_layer=nn.ReLU,num_classes=num_classes,depths=[3, 4, 18, 3],drop_rate=drop_path_rate)if __name__=="__main__":import torchsummarydevice = 'cuda' if torch.cuda.is_available() else 'cpu'input = torch.ones(2, 3, 224, 224).to(device)net = fasternet_t2(num_classes=4)net = net.to(device)out = net(input)print(out)print(out.shape)torchsummary.summary(net, input_size=(3, 224, 224))# t0 Total params: 2,629,624 Estimated Total Size (MB): 57.70# t1 Total params: 6,319,492 Estimated Total Size (MB): 100.02# t2 Total params: 13,707,012 Estimated Total Size (MB): 165.87# s Total params: 29,905,156 Estimated Total Size (MB): 304.56# m Total params: 52,245,588 Estimated Total Size (MB): 568.01# l Total params: 92,189,316 Estimated Total Size (MB): 843.09参考文章
CVPR 2023 | 最新主干FasterNet!远超MobileViT等模型-CSDN博客
【CVPR2023】FasterNet:追逐更高FLOPS、更快的神经网络-CSDN博客
FasterNet实战:使用FasterNet实现图像分类任务(二)_fasternet代码实现-CSDN博客
这篇关于部分卷积与FasterNet模型详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




