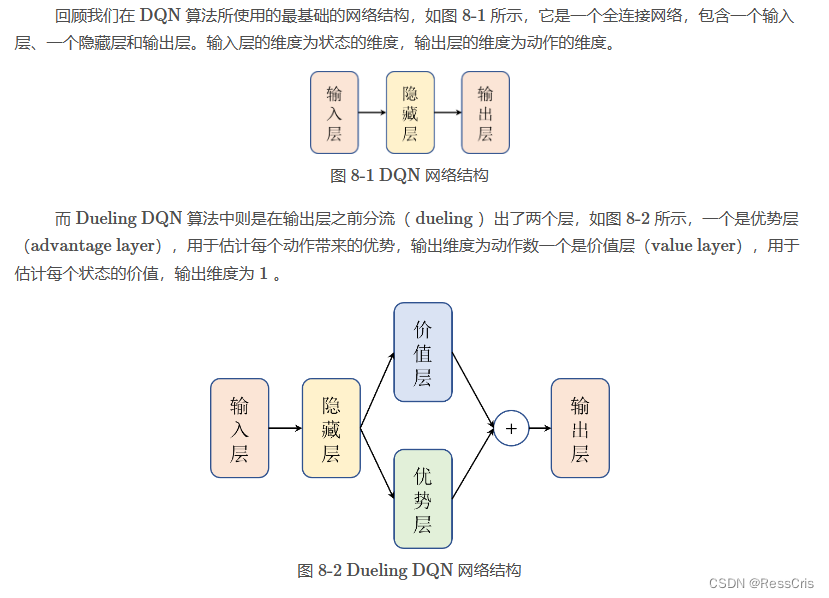
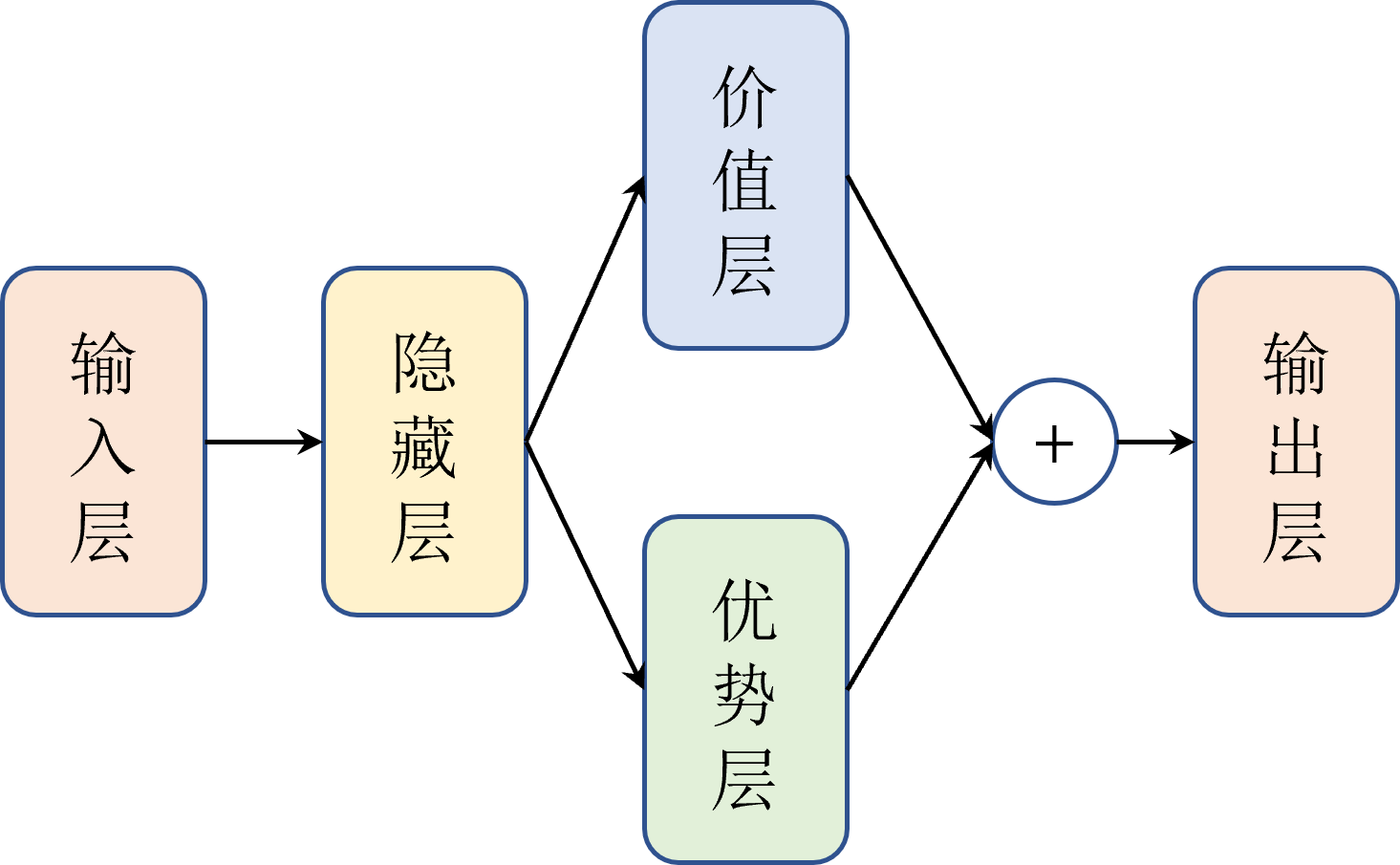
dqn专题

小琳AI课堂:DQN强化神经
大家好,这里是小琳AI课堂!今天我们来聊聊一个超级酷炫的算法——DQN(深度Q网络)!🤖 它可是深度学习和强化学习的完美结合,就像把两股超级英雄的力量合二为一,解决了那些高维输入空间的决策问题。这个算法是由DeepMind公司开发的,2015年一提出就震惊了整个AI界!🌟 先解释一下DQN是怎么工作的。🎨 DQN的基本原理: 强化学习背景:想象一下,有个小机器人(智能体)在一个充满挑战的环

先挖个坑等着填DQN PolicyGradient
问题 1.不能反向传播 2.计算出的loss用不用加和平均 import torch.nn as nnimport torch.nn.functional as Fimport torchimport gymimport numpy as npimport torch.optim as optimimport randomimport collectionsfrom torch
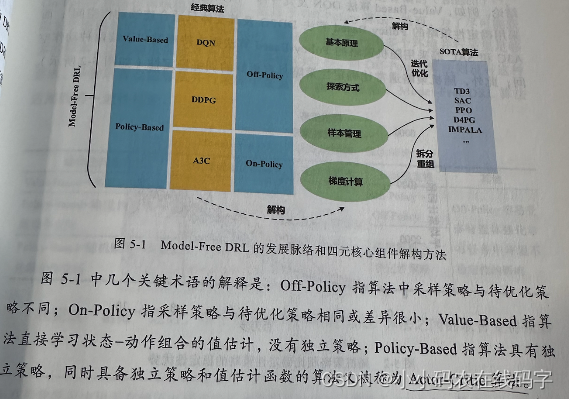
【强化学习-Mode-Free DRL】深度强化学习如何选择合适的算法?DQN、DDPG、A3C等经典算法Mode-Free DRL算法的四个核心改进方向
【强化学习-DRL】深度强化学习如何选择合适的算法? 引言:本文第一节先对DRL的脉络进行简要介绍,引出Mode-Free DRL。第二节对Mode-Free DRL的两种分类进行简要介绍,并对三种经典的DQL算法给出其交叉分类情况;第三节对Mode-Free DRL的四个核心(改进方向)进行说明。第四节对DQN的四个核心进行介绍。 DRL的发展脉络 DRL沿着Mode-Based和Mode

深度强化学习开端——DQN算法求解车杆游戏
深度强化学习开端——DQN算法求解车杆游戏 DQN,即深度Q网络(Deep Q-Network),是一种结合了深度学习和强化学习的算法,其主要用于解决序列决策问题,并且在许多复杂的决策任务中展现出了显著的效果。DQN算法的发明历史可以追溯到2013年,当时DeepMind团队首次提出了一种名为DQN(Deep Q-Network)的新型强化学习算法。这一算法标志着深度学习和强化学习成功结合的开始

论文结果难复现?本文教你完美实现深度强化学习算法DQN
选自arXiv 作者:Melrose Roderick等 机器之心编译 论文的复现一直是很多研究者和开发者关注的重点,近日有研究者详细论述了他们在复现深度 Q 网络所踩过的坑与训练技巧。本论文不仅重点标注了实现过程中的终止条件和优化算法等关键点,同时还讨论了实现的性能改进方案。机器之心简要介绍了该论文,更详细的实现细节请查看原论文。 过去几年来,深度强化学习逐渐流
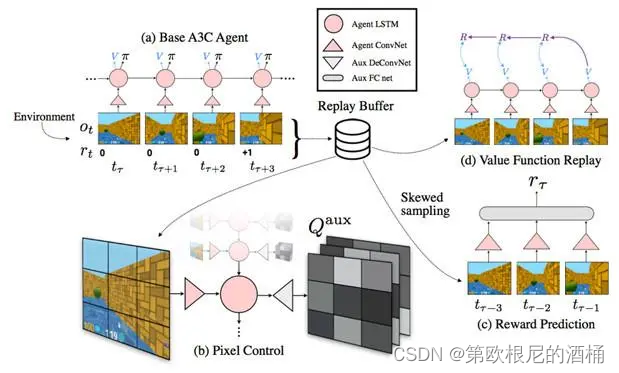
深度学习十大算法之深度Q网络(DQN)
一、简介 深度Q网络(DQN)是一种结合了深度学习和强化学习的算法,它在近年来成为了人工智能领域的一个热点。DQN首次被引入是在2013年,由DeepMind的研究人员开发。它标志着深度学习技术在解决高维度决策问题上的一大突破。 DQN的定义 DQN是一种算法,它使用深度神经网络来逼近最优的Q函数。在传统的Q学习中,Q函数用于估计在给定状态下采取特定动作的期望回报。DQN通过训练神经网络来学
self-attention mechanism DQN 算法和DQN算法的区别在哪
self-attention mechanism DQN 算法与标准的 DQN 算法之间的主要区别在于其在网络结构中引入了自注意力机制(self-attention mechanism)。下面是两者之间的主要区别: 网络结构: 标准的 DQN 通常使用深度神经网络(如卷积神经网络或全连接神经网络)来近似状态动作值函数(Q 函数)。这些网络结构主要由卷积层或全连接层组成,用于从状态中提取特征,并
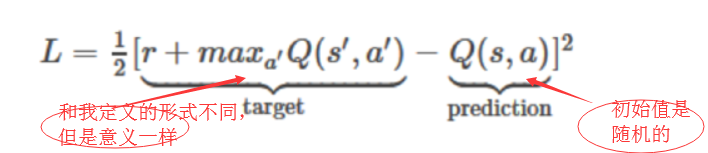
强化学习与Deep Q-Network(DQN)
什么是强化学习?难点是甚么? 1.有监督?无监督?是有稀疏并延时的标签---奖励(reword) 2.信用分配问题,得分可能跟你现在的行为没有直接的关系(不好表述) 3.对于现有得分,搜索/不搜索 ps:强化学习就是一个不断学习来提升自己的一个模型,当前的决策由现在或者未来决定的。 ps:滴滴的司机派单,阿尔法狗的棋谱学习,都有强化学习的影子。 马尔可夫决策过程 模型: 有限序
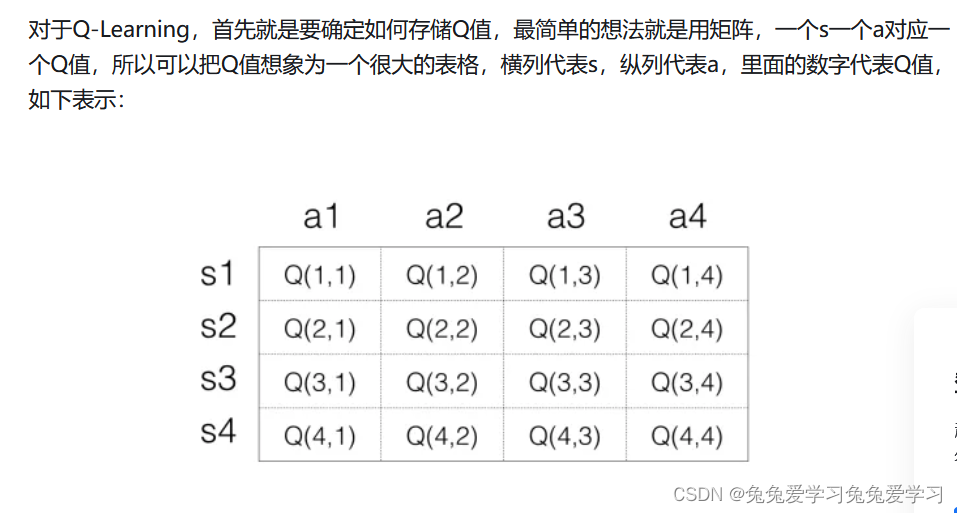
pytorch强化学习(2)——重写DQN
思路 在q-learning当中,Q函数的输入是状态state和action,输出是q-value。 而DQN就是使用神经网络来拟合Q函数,所以从直观上来说,我觉得神经网络的输入应该是状态state和action,输出应该是q-value。 但是,网上绝大多数DQN的代码实现都把state作为网络输入,把所有action的q-value的组合作为网络输出。我觉得这是不直观的、令人费解的,于是

DQN+Active Learning
关于MarkDown公式详细编辑可以参考博客 Initialize replay memory M M M to capacity NNN Initialize action-value function Q Q Q with random weights for episode = 1,2,...,N1,2,...,N1, 2,...,N do Dl D l
Double-DQN算法
Double-DQN算法的原理简介、与DQN对比等。 参考深度Q网络进阶技巧 1. 原理简介 在DQN算法中,虽然有target_net和eval_net,但还是容易出现Q值高估的情况,原因在于训练时用通过target_net选取最优动作 a ⋆ = argmax a Q ( s t + 1 , a ; w − ) a^{\star}=\underset{a}{\operatorname

【零基础强化学习】100行代码教你实现基于DQN的gym登山车
基于DQN的gym登山车🤔 写在前面show me code, no bb界面展示写在最后谢谢点赞交流!(❁´◡`❁) 更多代码: gitee主页:https://gitee.com/GZHzzz 博客主页: CSDN:https://blog.csdn.net/gzhzzaa 写在前面 作为一个新手,写这个强化学习-基础知识专栏是想和大家分享一下自己强化学习

DQN的理论研究回顾
DQN的理论研究回顾 1. DQN简介 强化学习(RL)(Reinforcement learning: An introduction, 2nd, Reinforcement Learning and Optimal Control)一直是机器学习的一个重要领域,近几十年来获得了大量关注。RL 关注的是通过与环境的交互进行连续决策,从而根据当前环境制定指导行动的策略,目标是实现长期回报最大化
强化学习原理python篇06(拓展)——DQN拓展
强化学习原理python篇06(拓展)——DQN拓展 n-steps代码结果 Double-DQN代码结果 Dueling-DQN代码结果 Ref 拓展篇参考赵世钰老师的教材和Maxim Lapan 深度学习强化学习实践(第二版),请各位结合阅读,本合集只专注于数学概念的代码实现。 n-steps 假设在训练开始时,顺序地完成前面的更新,前两个更新是没有用的,因为当前Q(
强化学习原理python篇06——DQN
强化学习原理python篇05——DQN DQN 算法定义DQN网络初始化环境开始训练可视化结果 本章全篇参考赵世钰老师的教材 Mathmatical-Foundation-of-Reinforcement-Learning Deep Q-learning 章节,请各位结合阅读,本合集只专注于数学概念的代码实现。 DQN 算法 1)使用随机权重 ( w ← 1.0 ) (w←
强化学习 - Deep Q Network (DQN)
什么是机器学习 Deep Q Network(DQN)是一种结合深度学习和强化学习的方法,用于解决离散动作空间的强化学习问题。DQN 是由DeepMind团队提出的,首次应用于解决Atari游戏,但也被广泛用于其他领域,如机器人学和自动驾驶。 以下是一个使用Python和TensorFlow / Keras 实现简单的DQN的示例代码。请注意,这是一个基本的实现,实际应用中可能需要进行更多的优
Datawhale 强化学习笔记(二)马尔可夫过程,DQN 算法
文章目录 参考马尔可夫过程DQN 算法(Deep Q-Network)如何用神经网络来近似 Q 函数如何用梯度下降的方式更新网络参数强化学习 vs 深度学习 提高训练稳定性的技巧经验回放目标网络 代码实战 DQN 算法进阶Double DQNDueling DQN 算法代码实战 参考 在线阅读文档 github 教程 开源框架 JoyRL datawhalechina/joyr
DQN、Double DQN、Dueling DQN、Per DQN、NoisyDQN 学习笔记
文章目录 DQN (Deep Q-Network)说明伪代码应用范围 Double DQN说明伪代码应用范围 Dueling DQN实现原理应用范围伪代码 Per DQN (Prioritized Experience Replay DQN)应用范围伪代码 NoisyDQN伪代码应用范围 部分内容与图片摘自:JoyRL 、 EasyRL DQN (Deep Q-Net
强化学习11——DQN算法
DQN算法的全称为,Deep Q-Network,即在Q-learning算法的基础上引用深度神经网络来近似动作函数 Q ( s , a ) Q(s,a) Q(s,a) 。对于传统的Q-learning,当状态或动作数量特别大的时候,如处理一张图片,假设为 210 × 160 × 3 210×160×3 210×160×3,共有 25 6 ( 210 × 60 × 3 ) 256^{(210×6
Deep Q-Network (DQN)理解
DQN(Deep Q-Network)是深度强化学习(Deep Reinforcement Learning)的开山之作,将深度学习引入强化学习中,构建了 Perception 到 Decision 的 End-to-end 架构。DQN 最开始由 DeepMind 发表在 NIPS 2013,后来将改进的版本发表在 Nature 2015。 NIPS 2013: Playing Atari w
【六】强化学习之DQN---PaddlePaddlle【PARL】框架{飞桨}
相关文章: 【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学 【二】-Parl基础命令 【三】-Notebook、&pdb、ipdb 调试 【四】-强化学习入门简介 【五】-Sarsa&Qlearing详细讲解 【六】-DQN 【七】-Policy Gradient 【八】-DDPG 【九】-四轴飞行器仿真
【六】强化学习之DQN---PaddlePaddlle【PARL】框架{飞桨}
相关文章: 【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学 【二】-Parl基础命令 【三】-Notebook、&pdb、ipdb 调试 【四】-强化学习入门简介 【五】-Sarsa&Qlearing详细讲解 【六】-DQN 【七】-Policy Gradient 【八】-DDPG 【九】-四轴飞行器仿真

【OpenAI Q* 超越人类的自主系统】DQN :Q-Learning + 深度神经网络
深度 Q 网络:用深度神经网络,来近似Q函数 强化学习介绍离散场景,使用行为价值方法连续场景,使用概率分布方法实时反馈连续场景:使用概率分布 + 行为价值方法 DQN(深度 Q 网络)= 深度神经网络 + Q-LearningQ-Learning模型结构损失函数经验回放探索策略流程关联 DQN 优化DDQN:双 DQN,实现无偏估计Dueling DQN:提高决策的准确性和效率Noisy D

深度强化学习DQN训练避障
目录 一.前言 二.代码 2.1完整代码 2.2运行环境 2.3动作空间 2.4奖励函数 2.5状态输入 2.6实验结果 一.前言 深度Q网络(DQN)是深度强化学习领域的一项革命性技术,它成功地将深度学习的强大感知能力与强化学习的决策能力相结合。在过去的几年里,DQN已经在许多复杂的问题上展示了其卓越的性能,从经典的Atari游戏到更复杂的机器人控制任务。特别值得一提

4.9 高级神经网络结构-什么是 DQN
目录 1.写在前面 2.强化学习与神经网络 3.神经网络的作用 4.更新神经网络 5.DQN 两大利器 1.写在前面 今天我们会来说说强化学习中的一种强大武器, Deep Q Network 简称为 DQN. Google Deep mind 团队就是靠着这 DQN 使计算机玩电动玩得比我们还厉害. 2.强化学习与神经网络 之前我们所谈论到