本文主要是介绍DQN、Double DQN、Dueling DQN、Per DQN、NoisyDQN 学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- DQN (Deep Q-Network)
- 说明
- 伪代码
- 应用范围
- Double DQN
- 说明
- 伪代码
- 应用范围
- Dueling DQN
- 实现原理
- 应用范围
- 伪代码
- Per DQN (Prioritized Experience Replay DQN)
- 应用范围
- 伪代码
- NoisyDQN
- 伪代码
- 应用范围
部分内容与图片摘自:JoyRL 、 EasyRL
DQN (Deep Q-Network)
说明
DQN通过深度学习技术处理高维状态空间,它的核心是使用深度神经网络来近似Q值函数。传统Q-learning依赖于一个查找表(Q表)来存储每个状态-动作对的Q值,但这在高维空间中变得不可行。DQN通过训练一个神经网络来学习这个映射关系。
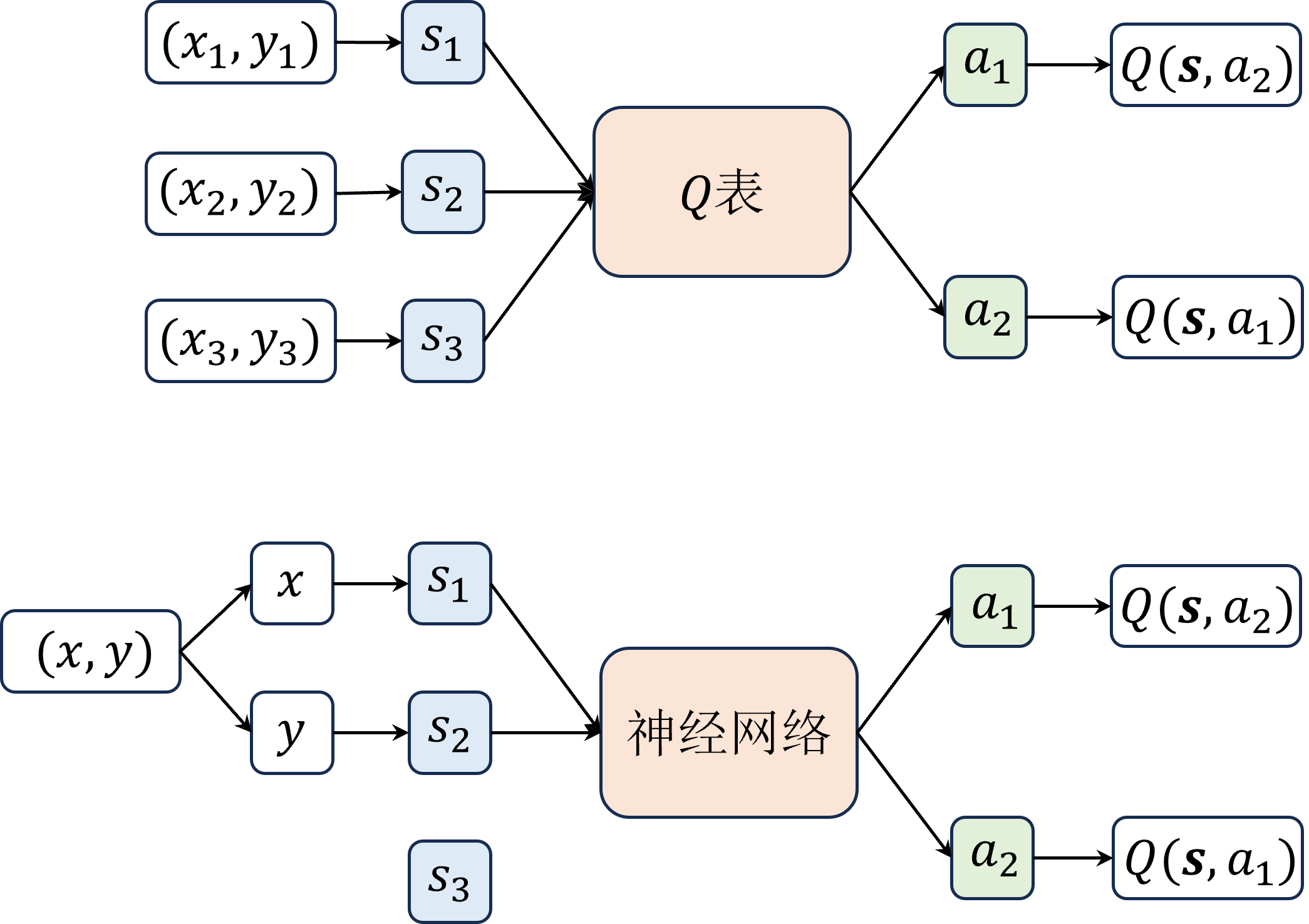
除了用深度网络代替 Q表之外,DQN算法还引入了一些技巧,如经验回放和目标网络。
经验回放:通过存储代理的经验(状态,动作,奖励,新状态)在回放缓存中,并在训练时从中随机抽样,这样做可以打破数据间的时间相关性,提高学习的稳定性和效率。
目标网络:DQN使用了两个网络:一个用于估计当前的Q值(在线网络),另一个用于生成目标Q值(目标网络)。这种分离有助于稳定训练过程,因为它减少了目标值随学习过程快速变化的问题。
伪代码
initialize replay memory D
initialize action-value function Q with random weights
for episode = 1, M doinitialize state sfor t = 1, T doselect action a with ε-greedy policy based on Qexecute action a, observe reward r and new state s'store transition (s, a, r, s') in Dsample random minibatch from Dcalculate target for each minibatch sampleupdate Q using gradient descentend for
end for
应用范围
- 适用于具有高维状态空间和离散动作空间的问题。
- 常用于游戏和模拟环境。
Double DQN
说明
主要解决了DQN在估计Q值时的过高估计(overestimation)问题。在传统的DQN中,选择和评估动作的Q值使用相同的网络,这可能导致在某些状态下对某些动作的Q值被高估,从而影响学习的稳定性和最终策略的质量。
Double DQN 通过使用两个不同的网络 QA 和 QB 来分别进行动作的选择和价值的估计,进而减少了传统DQN可能导致的Q值过高估计问题。
具体来说,动作选择是基于 QA 网络进行的,而价值估计则是基于 QB网络。在更新 QA 的过程中,使用 QB 来估计下一状态的价值,但是每隔固定的时间步, QB 会被 QA 的权值更新,从而实现两个网络的同步。这种方法提高了Q值估计的准确性,从而可以在复杂的决策环境中提供更稳定和可靠的学习性能。
伪代码
# Same as DQN until the target calculation
for each minibatch sample (s, a, r, s'):if s' is terminal:y = relse:a' = argmax_a Q(s', a; θ) # action selection by Q-networky = r + γ * Q(s', a'; θ') # target calculation by target networkupdate Q using gradient descent
应用范围
-
减少估计偏差,提高策略稳定性。
-
适用于需要精确动作价值估计的场景。
Dueling DQN
实现原理
Dueling DQN修改的是网络结构,算法中在输出层之前分流( dueling )出了两个层,如图所示,一个是优势层,用于估计每个动作带来的优势,输出维度为动作数一个是价值层,用于估计每个状态的价值,输出维度为 1。
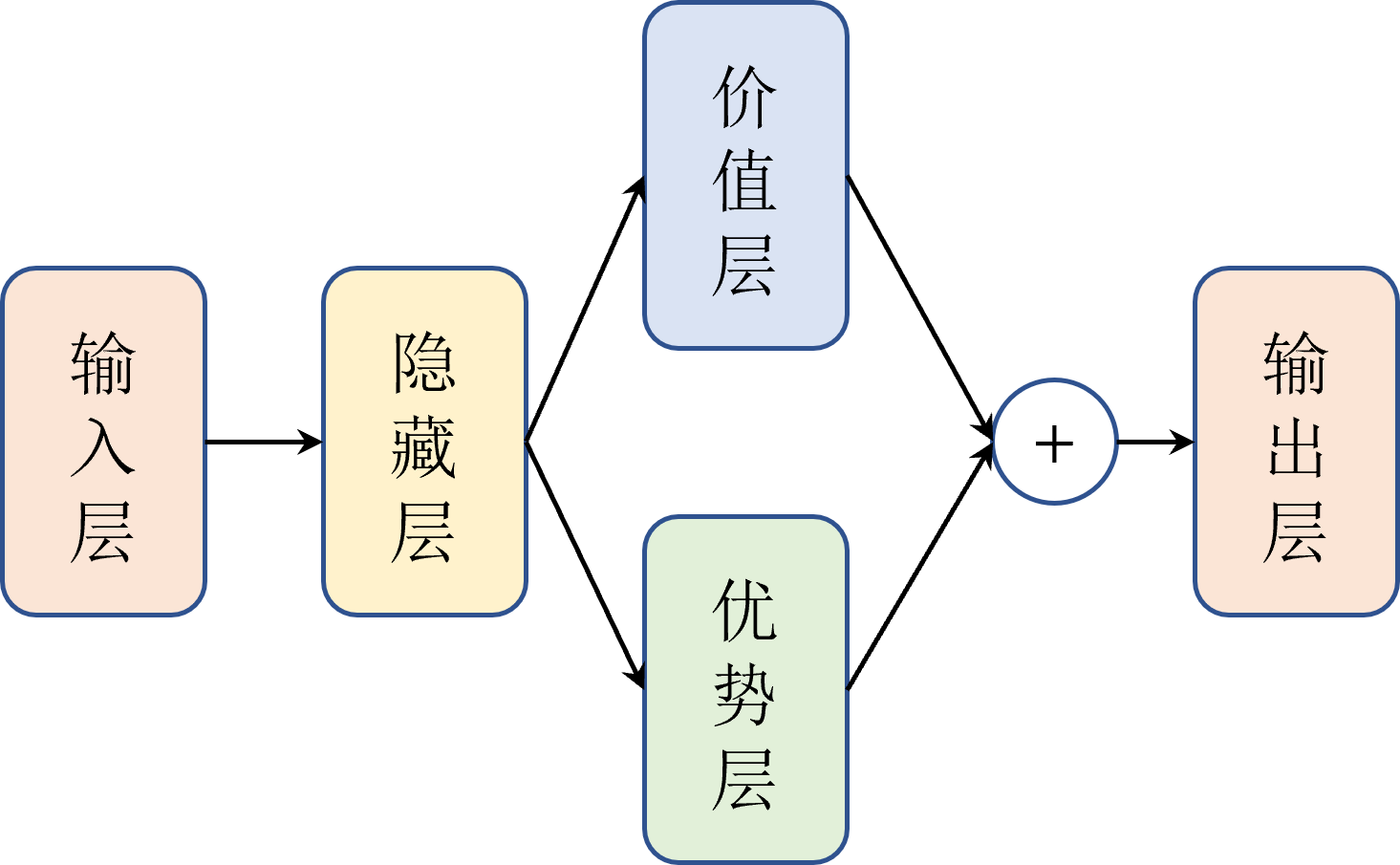
这种结构设计使得Dueling DQN在评估每个状态的价值时更加准确,尤其是在那些动作选择不会极大影响环境的情况下。换句话说,即使在状态的价值变化不大时,Dueling DQN也能有效地学习到动作间的差异,这对于在复杂策略空间中找到最优策略特别有用。
应用范围
Dueling DQN特别适合于那些状态值比动作选择本身更重要的场景,例如,在一些策略游戏或者决策问题中,环境可能对特定动作不敏感(比如不需要开火?),此时,能够精确评估状态价值的Dueling DQN将非常有用。此外,Dueling DQN也适用于需要从大量相似动作中做出选择的任务,因为它能够更好地区分各个动作的微小差异。
伪代码
# Network architecture change
for each minibatch sample (s, a, r, s'):V = V(s; θV) # State value functionA = A(s, a; θA) # Advantage functionQ = V + (A - mean(A)) # Q value calculationupdate Q using gradient descent
Per DQN (Prioritized Experience Replay DQN)
Per DQN增强了基本DQN的经验回放机制,通过优先级回放来指导学习过程。在传统的经验回放中,训练样本是随机抽取的,每个样本被重新使用的概率相同。然而,并非所有的经验都同等重要。Per DQN通过计算时间差分误差(Temporal Difference Error,TD error),为每个经验样本分配一个优先级,优先级高的样本更有可能被抽取来进行学习。
- 时序差分误差:TD error是实际奖励与当前Q值函数预测奖励之间的差异。较大的TD error意味着对应的经验可能会给我们的学习带来更多信息。
- 优先级的设定:在经验优先回放(Prioritized Experience Replay)中,每个经验的优先级是根据其时序差分误差(TD error)的大小来设定的。TD error是实际奖励与估计奖励之间的差异,它反映了当前策略预测的准确性。一个高TD error的经验表示当前策略有更大的学习潜力,因此被赋予更高的优先级,以便更频繁地从经验回放中被抽样学习。
应用范围
Per DQN适用于那些代理可以从特定经验中快速学习的场景。在复杂的环境中,一些关键的决策点可能只出现几次,传统的随机抽样可能会忽略这些经验。Per DQN确保这些有价值的经验能够被更频繁地回顾和学习,从而加速学习过程,有助于更快地收敛到一个好的策略。
伪代码
initialize priority replay memory D
for each minibatch sample (s, a, r, s'):calculate TD error: δ = |r + γ * max_a' Q(s', a') - Q(s, a)|update priority of (s, a, r, s') in D based on δupdate Q using gradient descent
缺陷:直接使用TD误差作为优先级存在一些问题。首先,考虑到算法效率问题,我们在每次更新时不会把经验回放中的所有样本都计算TD误差并更新对应的优先级,而是只更新当前取到的一定批量的样本。这样一来,每次计算的TD误差是对应之前的网络,而不是当前待更新的网络。
所以引入了额外的技巧:随机采样和重要性采样。
NoisyDQN
增加噪声层(炼丹的通用操作),提高模型泛化性,避免陷入局部最优解。
伪代码
initialize Q network with noisy layers
for each minibatch sample (s, a, r, s'):select action a using Q with noiseexecute action a, observe r, s'store transition, sample minibatchupdate Q using gradient descent
应用范围
- 适用于探索性任务和非稳态环境。
- 动态调整探索策略,适合于需要适应性探索的复杂场景。
这篇关于DQN、Double DQN、Dueling DQN、Per DQN、NoisyDQN 学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








