dueling专题
DQN、Double DQN、Dueling DQN、Per DQN、NoisyDQN 学习笔记
文章目录 DQN (Deep Q-Network)说明伪代码应用范围 Double DQN说明伪代码应用范围 Dueling DQN实现原理应用范围伪代码 Per DQN (Prioritized Experience Replay DQN)应用范围伪代码 NoisyDQN伪代码应用范围 部分内容与图片摘自:JoyRL 、 EasyRL DQN (Deep Q-Net
09、基于LunarLander登陆器的Dueling DQN强化学习(含PYTHON工程)
09、基于LunarLander登陆器的Dueling DQN强化学习(含PYTHON工程) 参考: 论文地址:https://proceedings.mlr.press/v48/wangf16.pdf LunarLander复现: 07、基于LunarLander登陆器的DQN强化学习案例(含PYTHON工程) 08、基于LunarLander登陆器的DDQN强化学习(含PYTHON工程

【深度强化学习】DQN, Double DQN, Dueling DQN
DQN 更新方程 Q θ ( s t , a t ) ← Q θ ( s t , a t ) + α ( r t + γ max a ′ Q θ ( s t + 1 , a ′ ) − Q θ ( s t , a t ) ) Q_\theta(s_t,a_t) \leftarrow Q_\theta(s_t,a_t) + \alpha \left( r_t + \gamma \r

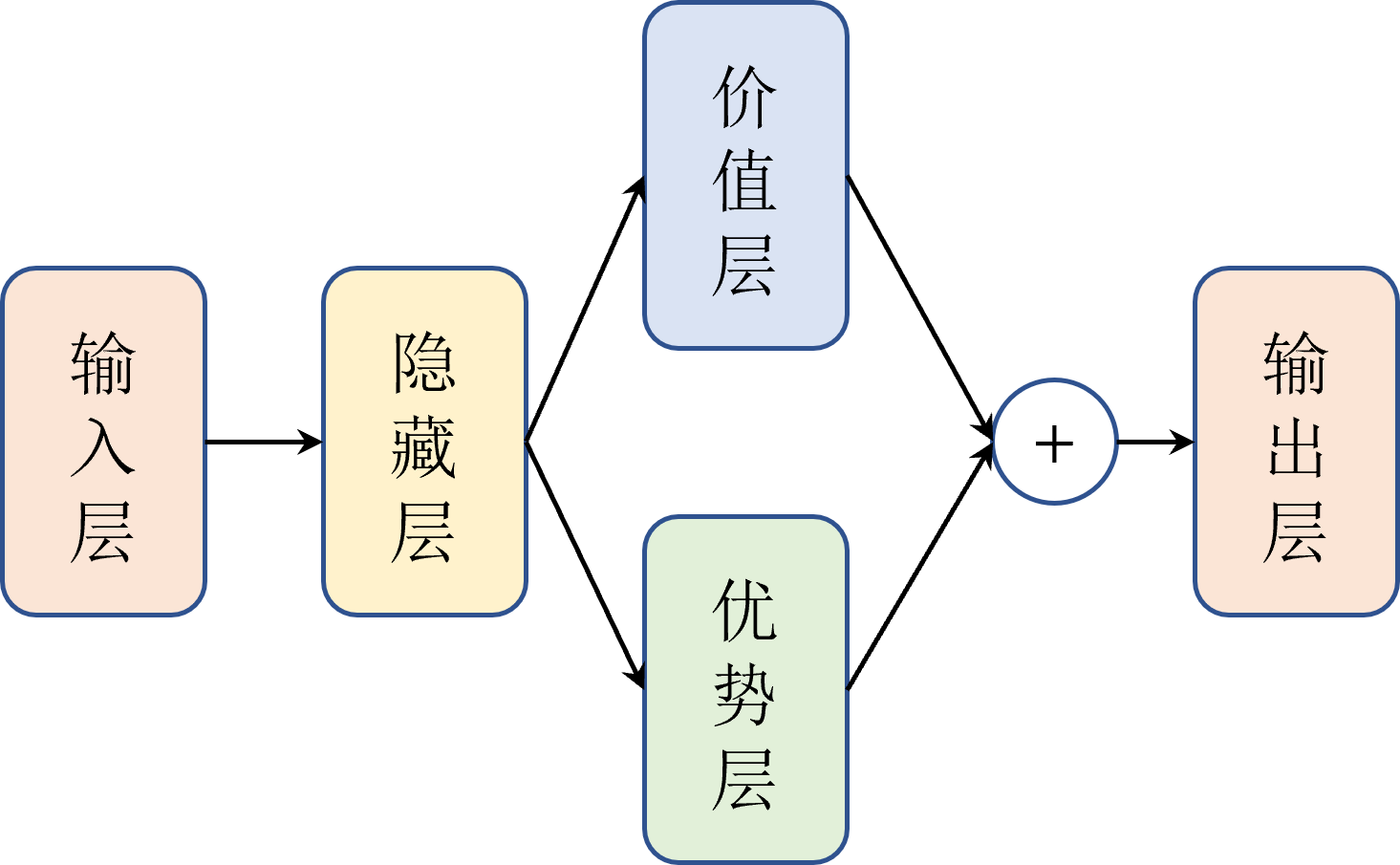
强化学习(二)——Dueling Network(DQN改进)
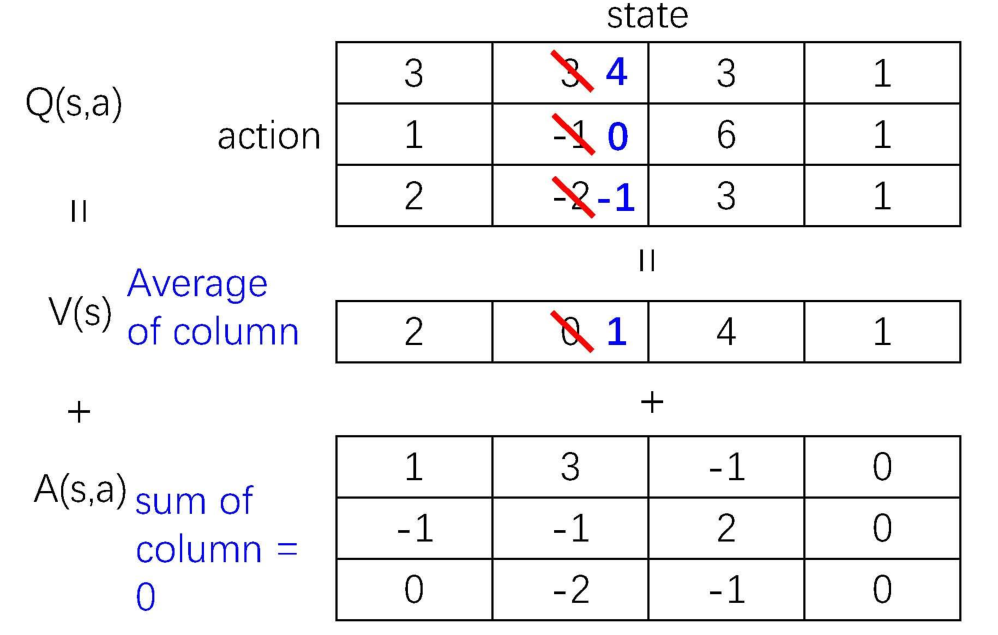
与DNQ相比,使用优势函数(A函数)和状态价值函数(V)代替之前的Q(动作价值)函数, 最核心公式为 Q ∗ ( s , a ) = A ∗ ( s , a ) + V ∗ ( s ) − max a A ∗ ( s , a ) Q^*(s,a)=A^*(s,a)+V^*(s)-\max_a A^*(s,a) Q∗(s,a)=A∗(s,a)+V∗(s)−maxaA∗(s,a)。 核心公式演
强化学习 - DQN及进化过程(Double DQN,Dueling DQN)
1.DQN 1.1概念 DQN相对于Q-Learning进行了三处改进: 1.引入神经网络:如下图所示希望能从状态S中提取Q(s,a) 2.经验回放机制:连续动作空间采样时,前后数据具有强关联性,而神经网络训练时要求数据之间具有独立同分布特性,简单理解,就是前后输入的数据之间要有独立性,所以对于连续空间数据,采用随机采样法, 3.设置单独目标网络:下式

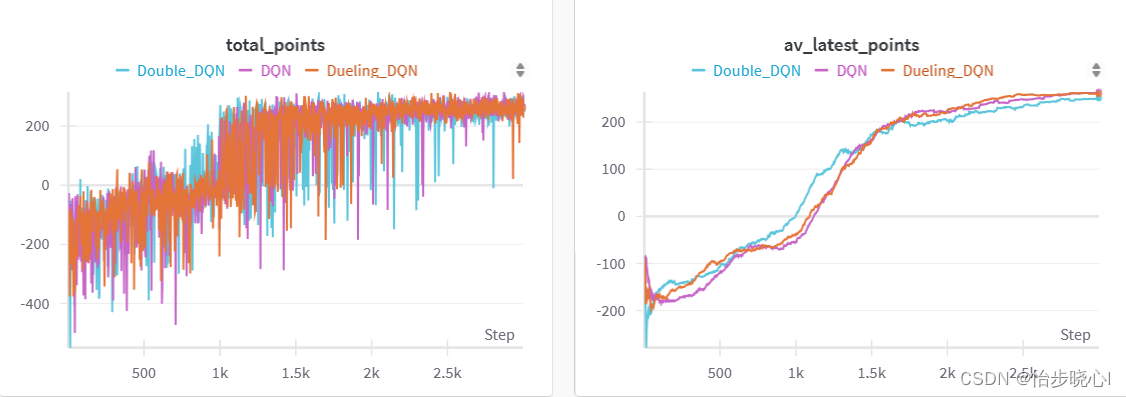
【强化学习】11 —— Double DQN算法与Dueling DQN算法
文章目录 Q-learning中的过高估计Double DQNDouble DQN代码实践Pendulum环境代码结果 Dueling DQNDueling DQN网络结构Dueling DQN优点Dueling DQN 代码实践结果 参考 Q-learning中的过高估计 普通的 DQN 算法通常会导致对值的过高估计(overestimation)。传统 DQN 优化的 T
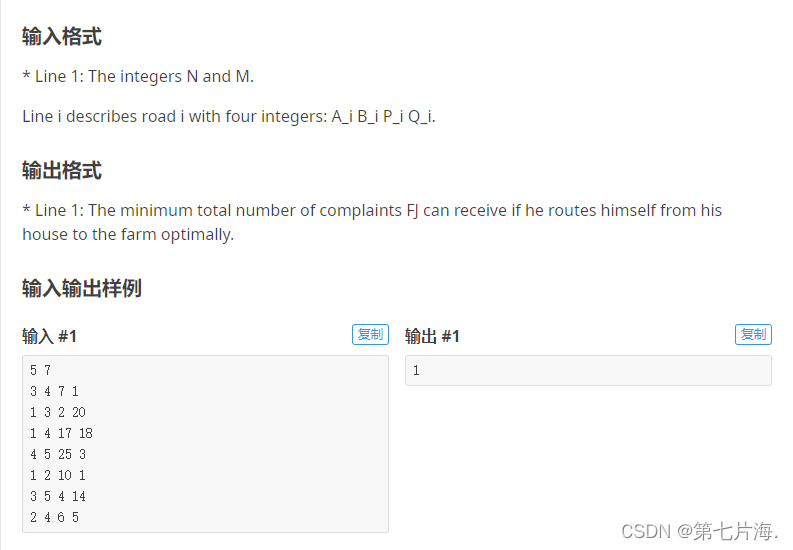
【洛谷P3106】Dueling GPSs S【最短路 变式】
P r o b l e m l i n k Problem~link Problem link 分析: 以 n n n为起点 跑两次 s p f a spfa spfa 记录两个 G P S GPS GPS的最短路径 最后再做一遍 s p f a spfa spfa 对于统计不在最短路上 可以先建边权为 2 2 2的图 跑最短路 遇到相同的 − 1 -1 −1即可 CODE: #i