per专题
![【Get深一度】谐振腔中的电场(E Field[V_per_m])与磁场(H field[A_per_m])分布](https://img-blog.csdn.net/20160809155646491?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
【Get深一度】谐振腔中的电场(E Field[V_per_m])与磁场(H field[A_per_m])分布
1.模式1[TM010模]的电场和磁场分布 模式1在腔体横截面(XY)上的电磁场分布

React Native之编译提示Only one default export allowed per module.
1 问题 部分代码如下 class HomeScreen extends React.Component {render() {return (<View style={{ flex: 1, alignItems: 'center', justifyContent: 'center' }}><Text>Home Screen</Text></View>);}}export default c

三种访问模式(Per-Call Service,Sessionful Service,Singleton Service)
1.单调服务(Per-Call Service):每次的客户端请求分配一个新的服务实例。类似于Net Remoting的SingleCall模式; 单调服务(Per-Call Service):每次的客户端请求分配一个新的服务实例。服务实例的生存周期紧紧限制于一次调用的开始与结束之间。客户端的每次请求都会产生新的服务实例来响应这个调用。类似于Net Remoting的SingleCall模
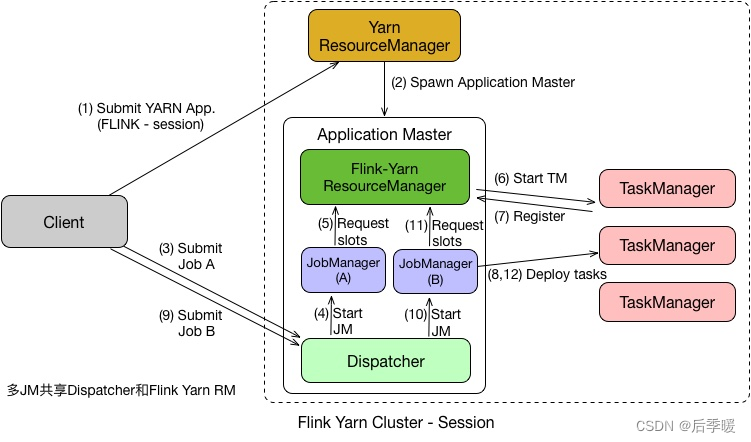
flink on yarn-per job源码解析、flink on k8s介绍
Flink 架构概览–JobManager JobManager的功能主要有: 将 JobGraph 转换成 Execution Graph,最终将 Execution Graph 拿来运行Scheduler 组件负责 Task 的调度Checkpoint Coordinator 组件负责协调整个任务的 Checkpoint,包括 Checkpoint 的开始和完成通过 Actor
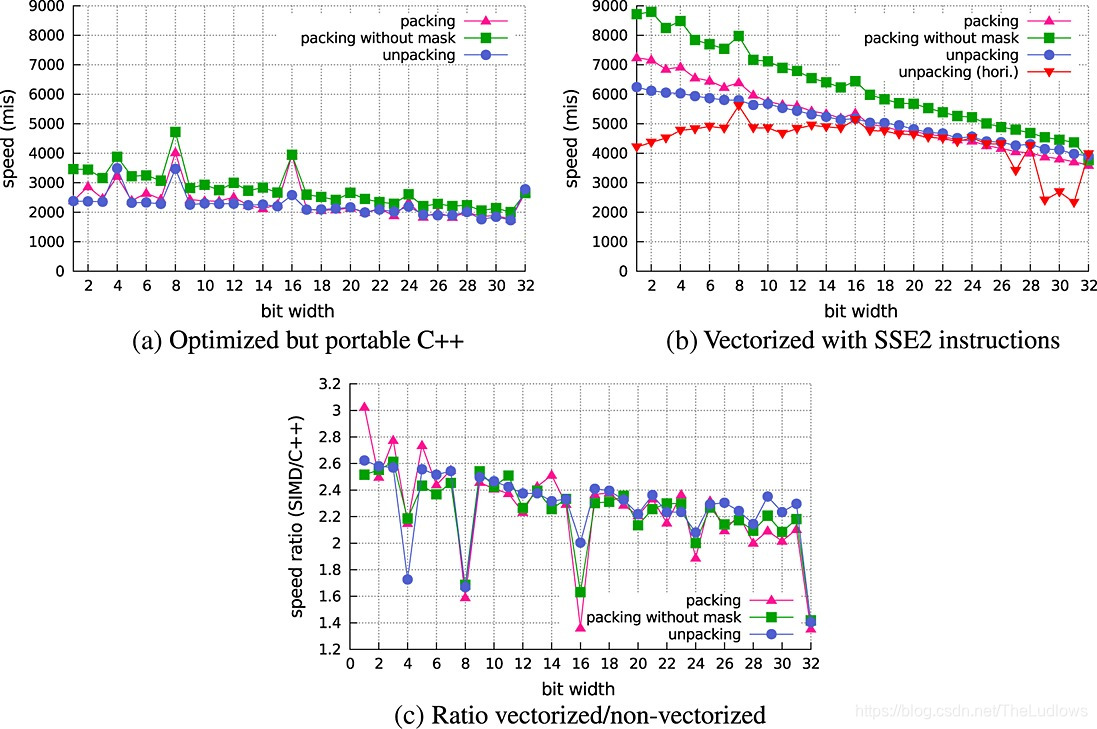
Decoding billions of integers per second through vectorization
, Decoding billions of integers per second through vectorization D. Lemire and L. Boytsov LICEF Research Center, TELUQ, Montreal, QC, Canada Carnegie Mellon University, Pittsburgh, PA, USA
理论学习:GPU 进程 ngpus_per_node是什么,world_size是什么?
在分布式训练环境中,ngpus_per_node和world_size是两个常用的术语,它们用于配置和管理跨多个节点和GPU的训练过程。 ngpus_per_node: ngpus_per_node指的是单个节点(机器或服务器)上可用于训练的GPU数量。在多GPU训练场景中,你可能希望利用一个节点上的所有GPU来并行处理数据,加速训练过程。这个参数帮助你确定每个节点上有多少GP
![[论文笔记] BPC(bits per character)和BPW(bits per word)](/front/images/it_default.jpg)
[论文笔记] BPC(bits per character)和BPW(bits per word)
BPC和BPW都是评估语言模型性能的指标: BPC (Bits-Per-Character) BPC表示 每个字符的平均编码长度,计算公式为: BPC = 交叉熵损失失/ log(2) 其中交叉熵损失是模型在数据集上的平均负对数似然。 BPC越小,表示模型对数据集的建模能力越强。 BPW (Bits-Per-Word)) BPW表示 每个单
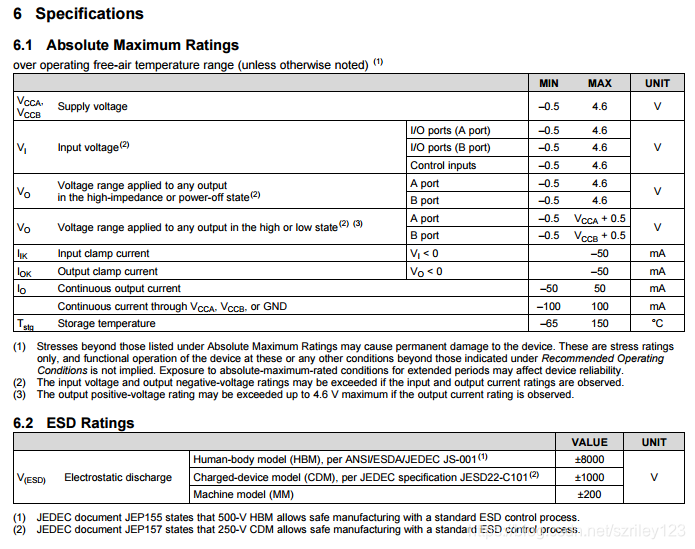
SN74AHCT541PWR缓冲器 非反向1Element 8 Bit per Element 三态 Output 20-TSSOP
SN74AHCT541PWR 工作范围2 V至5.5 V VCC 闩锁性能超过250 mA JESD 描述/订购信息 AHC541八进制缓冲器/驱动器非常适合驱动总线或缓冲存储器地址寄存器。 这些设备具有输入和 包裹两侧的输出到便于印刷电路板布局。 三态控制门是双输入AND门具有低电平有效输入,如果有的话输出使能(OE1或OE2)输入为高电平 相应的输出处于高阻态州。 输出时提供非反转数据它们
20130403-[转]One ELF Section per Function
KEI MDK软件中,工程设置有这样的一个选项。 选项One ELF Section per Function的主要功能是对冗余函数的优化。通过这个选项,可以在最后生成的二进制文件中将冗余函数排除掉(虽然其所在的文件已经参与了编译链接),以便最大程度地优化最后生成的二进制代码。 而该选项实现的机制是将每一个函数作为一个优化的单元,而并非整个文件作为参与优化的单元。 选项One ELF Sec
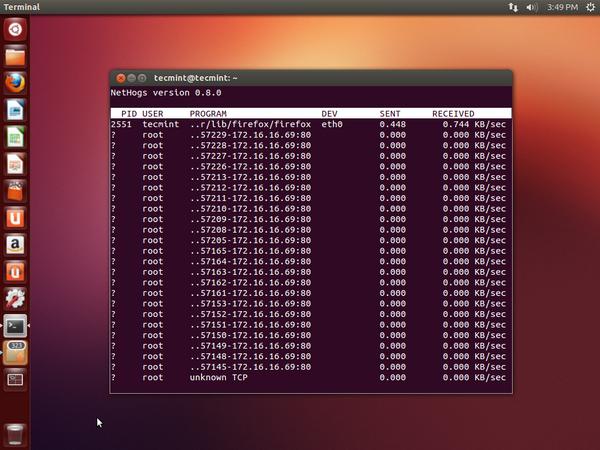
NetHogs - Monitor Per Process Network Bandwidth Usage in Real Time
原文链接:http://www.tecmint.com/nethogs-monitor-per-process-network-bandwidth-usage-in-real-time/ Linux operating systems have tons of open source network monitoring tools on the web. Say, you can use
Requests Per Second
HBase UI中Requests Per Second:当前region server中每秒接收到的rpc请求数 参考文章:Hbase源码分析:Hbase UI中Requests Per Second的具体含义
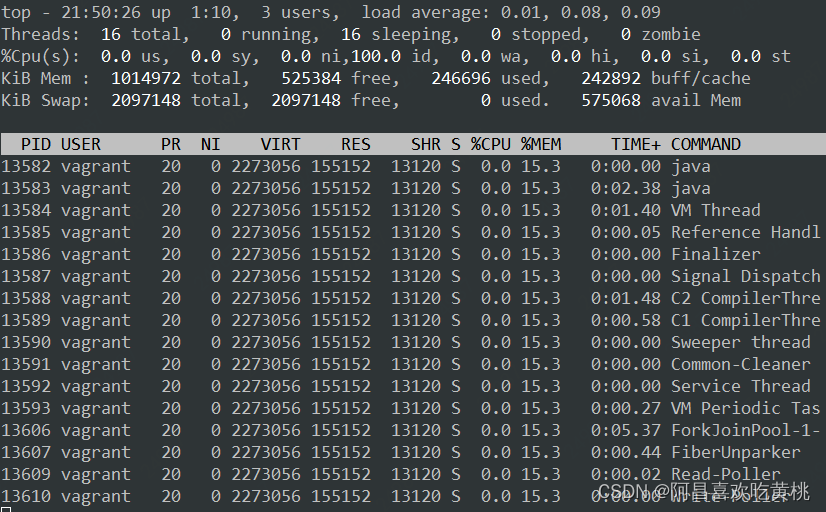
Day852.Thread-Per-Message模式 -Java 并发编程实战
Thread-Per-Message模式 Hi,我是阿昌,今天学习记录的是关于Thread-Per-Message模式的内容。 Thread-Per-Message 模式,简言之就是为每个任务分配一个独立的线程。 并发编程领域的问题总结为三个核心问题: 分工同步互斥 其中,同步和互斥相关问题更多地源自微观,而分工问题则是源自宏观。解决问题,往往都是从宏观入手,在编程领域,软件的设计过程也

flink per job on yarn 找不到或无法加载主类org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint
前言 最近一直忙着规则引擎项目的开发。目前规则引擎项目基于flink流式计算来开发的。对于用户配置的规则要动态生成flink job 并自动化的发布到yarn上进行执行。考虑到将多个flink job共享一个yarn session势必会造成资源的争夺以及相互影响,觉得发布方式采用单个flink job直接发布到yarn上,作为单独的application在yarn上执行。针对这种方式,目前fl
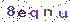
linux内核percpu变量声明,Linux内核同步机制之(二):Per-CPU变量
Linux内核同步机制之(二):Per-CPU变量 作者:linuxer 发布于:2014-10-16 11:17 分类:内核同步机制 一、源由:为何引入Per-CPU变量? 1、lock bus带来的性能问题 在ARM平台上,ARMv6之前,SWP和SWPB指令被用来支持对shared memory的访问: SWP , , [] Rn中保存了SWP指令要操作的内存地址,通过该指令可以将Rn指定
linux -- per-CPU变量
per-CPU变量 per-CPU变量是一种存在与每个CPU本地的变量,对于每一种per-CPU变量,每个CPU在本地都有一份它的副本。 per-CPU变量的优点 多处理器系统(smp)中无需考虑与其他处理器的竞争问题(并非绝对的)可以利用处理器本地的cache硬件,提高访问速度 per-CPU变量的分类 按照分配内存空间的类型来看,有两种: 静态per-CPU变量动态per-CPU变
DQN、Double DQN、Dueling DQN、Per DQN、NoisyDQN 学习笔记
文章目录 DQN (Deep Q-Network)说明伪代码应用范围 Double DQN说明伪代码应用范围 Dueling DQN实现原理应用范围伪代码 Per DQN (Prioritized Experience Replay DQN)应用范围伪代码 NoisyDQN伪代码应用范围 部分内容与图片摘自:JoyRL 、 EasyRL DQN (Deep Q-Net
设计模式之多线程分工模式--- Thread-Per-Message模式
系列文章目录 设计模式之避免共享的设计模式Immutability(不变性)模式 设计模式之并发特定场景下的设计模式 Two-phase Termination(两阶段终止)模式 设计模式之避免共享的设计模式Copy-on-Write模式 设计模式之避免共享的设计模式 Thread-Specific Storage 模式 设计模式之多线程版本的if------Guarded Suspension
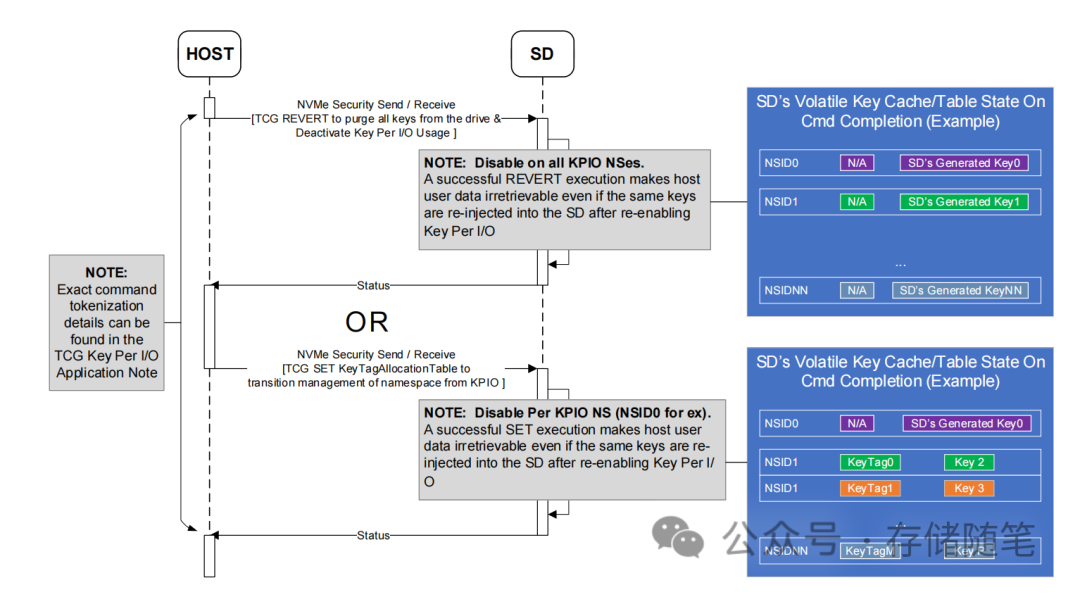
浅析NVMe key per IO加密技术-2
二、Key per IO功能设置的流程 设置Key Per I/O功能需要对NVMe存储设备进行一系列配置,涉及多个步骤和能力要求。以下是一个简化的流程概述: 硬件支持:首先,NVMe固态硬盘支持Key Per I/O技术,并且了解相关的NVM Express规格、TCG Key Per I/O SSC v1.00标准以及其他行业规范。 初始化检测: 通过NVMe Identify

min_faces_per_person=60 is too restrictive解决办法(人脸识别数据lfw_funneled)
min_faces_per_person=60 is too restrictive解决办法. 在运行: faces = fetch_lfw_people(min_faces_per_person=60)#实例化 #每个人需要60张图 这个代码时出现问题: 这个是因为有数据没有下载完整而报的错误,下载到的目录(我的是window系统,在)下载好复制到这个目录就行,必须先将lfw_ho

【并发设计模式】聊聊Thread-Per-Message与Worker-Thread模式
在并发编程中,核心就是同步、互斥、分工。 同步是多个线程之间按照一定的顺序进行执行,比如A执行完,B在执行。而互斥是多个线程之间对于共享资源的互斥。两个侧重点不一样,同步关注的是执行顺序,互斥关注的是资源的排他性访问。 分工则是从一个宏观的角度,将任务庖丁解牛,将一个大任务进行拆分,每个线程执行一个任务的子集。主要的设计模式就是Thread-Per-Message(来一个任务,新建一个线程执行

多线程设计模式:Thread-Per-Message模式
为每个命令或请求新分配一个线程,由这个线程来执行处理,这就是Thread-Per-Message模式。 举个例子: 名字说明Main向Host发送字符,显示请求的类Host针对请求创建线程的类Helper提供字符显示功能的被动类 代码: Main: public class Main {public static void main(String[] args) {System.ou
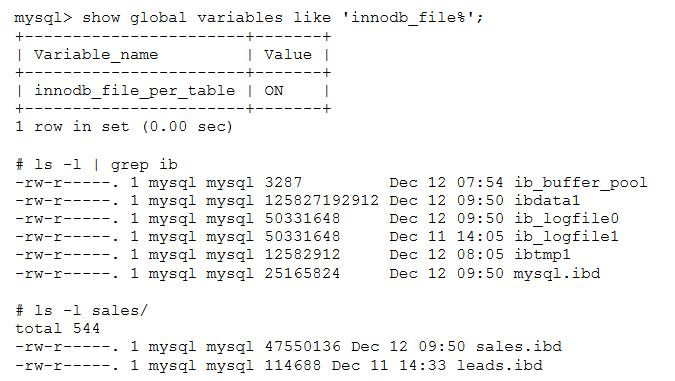
MySQL 8.0 InnoDB Tablespaces之File-per-table tablespaces(单独表空间)
文章目录 MySQL 8.0 InnoDB Tablespaces之File-per-table tablespaces(单独表空间)File-per-table tablespaces(单独表空间)相关变量:innodb_file_per_table使用TABLESPACE子句指定表空间变量innodb_file_per_table设置为关闭状态时创建表指定TABLESPACE:innod
Thread-Per-Message设计模式
Thread-Per-Message是为每一个消息的处理开辟一个线程,以并发方式处理,提高系统整体的吞吐量。这种模式再日常开发中非常常见,为了避免线程的频繁创建和销毁,可以使用线程池来代替。 示例代码如下: public class Request {private String business;public Request(String business) {this.bu
Thread-Per-Message设计模式
Thread-Per-Message是为每一个消息的处理开辟一个线程,以并发方式处理,提高系统整体的吞吐量。这种模式再日常开发中非常常见,为了避免线程的频繁创建和销毁,可以使用线程池来代替。 示例代码如下: public class Request {private String business;public Request(String business) {this.bu
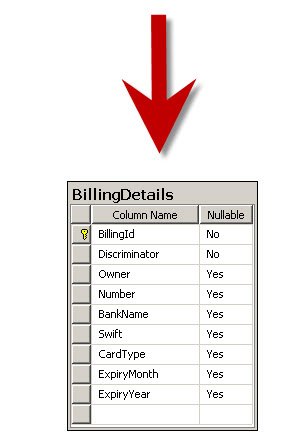
Inheritance with EF Code First: Part 1 – Table per Hierarchy (TPH)
以下三篇文章是Entity Framework Code-First系列中第七回:Entity Framework Code-First(7):Inheritance Strategy 提到的三篇。这三篇文章写的时间有点久远,还是在2010年,提到EF应该在4.1版本之前,使用的还是ObjectContext而不是现在的DbContext,内容供参考 ----------------------