本文主要是介绍强化学习与Deep Q-Network(DQN),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是强化学习?难点是甚么?
1.有监督?无监督?是有稀疏并延时的标签---奖励(reword)
2.信用分配问题,得分可能跟你现在的行为没有直接的关系(不好表述)
3.对于现有得分,搜索/不搜索
ps:强化学习就是一个不断学习来提升自己的一个模型,当前的决策由现在或者未来决定的。
ps:滴滴的司机派单,阿尔法狗的棋谱学习,都有强化学习的影子。
马尔可夫决策过程
模型:
有限序列,状态序列和行为序列,
有确定假设:当前的状态只由上一状态决定,当前的行为基于当前的状态。
具有无后效性,马尔可夫性。
把“眼光”放长远:打折未来奖励(discounted future reward)
t时刻(包括t时刻)的未来奖励:(假设是一个马尔可夫决策过程)
![]()
因为未来有不确定性,所以只需要计算打折的未来奖励!(乘一个[0,1]系数):
![]()
写成递推公式:(定义好了打折的未来奖励)
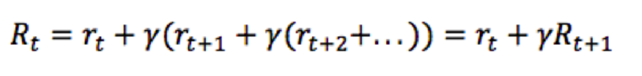
怎么预估“未来收益”?
进行建模!
假设函数:Q(s,a)是在s状态下采取a行为并在之后采取最优动作来获得最高打折的未来奖励
那么最大的奖励就是:当前s状态下的收益 + Q(s,a)是在s的下一时刻最大的收益!
发现了没:这就是一个DP,maxVal就是一个递推方程(转态转移方程),但是对于DP都知道时间空间消耗比较大
状态空间太大怎么办? 使用深度神经网络(DQN)
对state和action进行输入来预测Q函数的值,(这个值是随机初始化的)
建模:利用表达能力极强的神经网络

定义损失函数:均方误差损失
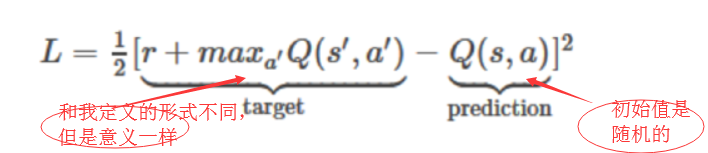
这个模型没有加入池化层,因为引出pooling层会损失掉图片模式的位置信息,这显然是不可行的!
但是,Q函数不是线性的,一定不是凸函数,那么收敛有会有问题!
“重演”策略
经验回放,把所有的经历都记录下来,在SGD时随机批选取样本,不能按时序来进行排,
因为训练实例之间相似性太大,网络很容易收敛到局部最小值!(冗余项太多,会加大该特征的表达)
总结:
1.信用分配问题:该算法通过神经网络来预测,可以将reword回馈到关键步骤
2.搜索问题:损失每次都以求最值的方式进行优化,这是一种贪心的思想,但是它会带引模型搜索当前认为最好的策略!
这篇关于强化学习与Deep Q-Network(DQN)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







